【论文推荐】最新五篇视频分类相关论文—细粒度行人识别、群组归一化、MLtuner、时序特征
【导读】既昨天推出五篇视频分类(Video Classification)文章,专知内容组今天又推出最近七篇视觉问答相关文章,为大家进行介绍,欢迎查看!
1. Fine-grained Activity Recognition in Baseball Videos(在棒球视频中细粒度的行人识别)
作者:AJ Piergiovanni,Michael S. Ryoo
机构:Indiana University
摘要:In this paper, we introduce a challenging new dataset, MLB-YouTube, designed for fine-grained activity detection. The dataset contains two settings: segmented video classification as well as activity detection in continuous videos. We experimentally compare various recognition approaches capturing temporal structure in activity videos, by classifying segmented videos and extending those approaches to continuous videos. We also compare models on the extremely difficult task of predicting pitch speed and pitch type from broadcast baseball videos. We find that learning temporal structure is valuable for fine-grained activity recognition.

期刊:arXiv, 2018年4月10日
网址:
http://www.zhuanzhi.ai/document/0519a3c3e75dab982dc4e2b80b5b92b9
2. DAiSEE: Towards User Engagement Recognition in the Wild
作者:Abhay Gupta,Arjun D'Cunha,Kamal Awasthi,Vineeth Balasubramanian
摘要:We introduce DAiSEE, the first multi-label video classification dataset comprising of 9068 video snippets captured from 112 users for recognizing the user affective states of boredom, confusion, engagement, and frustration in the wild. The dataset has four levels of labels namely - very low, low, high, and very high for each of the affective states, which are crowd annotated and correlated with a gold standard annotation created using a team of expert psychologists. We have also established benchmark results on this dataset using state-of-the-art video classification methods that are available today. We believe that DAiSEE will provide the research community with challenges in feature extraction, context-based inference, and development of suitable machine learning methods for related tasks, thus providing a springboard for further research. The dataset is available for download at https://iith.ac.in/~daisee-dataset.

期刊:arXiv, 2018年4月13日
网址:
http://www.zhuanzhi.ai/document/9cda5868fc0eb068afaccf79c30dbe82
3. Group Normalization(群组归一化)
作者:Yuxin Wu,Kaiming He
摘要:Batch Normalization (BN) is a milestone technique in the development of deep learning, enabling various networks to train. However, normalizing along the batch dimension introduces problems --- BN's error increases rapidly when the batch size becomes smaller, caused by inaccurate batch statistics estimation. This limits BN's usage for training larger models and transferring features to computer vision tasks including detection, segmentation, and video, which require small batches constrained by memory consumption. In this paper, we present Group Normalization (GN) as a simple alternative to BN. GN divides the channels into groups and computes within each group the mean and variance for normalization. GN's computation is independent of batch sizes, and its accuracy is stable in a wide range of batch sizes. On ResNet-50 trained in ImageNet, GN has 10.6% lower error than its BN counterpart when using a batch size of 2; when using typical batch sizes, GN is comparably good with BN and outperforms other normalization variants. Moreover, GN can be naturally transferred from pre-training to fine-tuning. GN can outperform or compete with its BN-based counterparts for object detection and segmentation in COCO, and for video classification in Kinetics, showing that GN can effectively replace the powerful BN in a variety of tasks. GN can be easily implemented by a few lines of code in modern libraries.
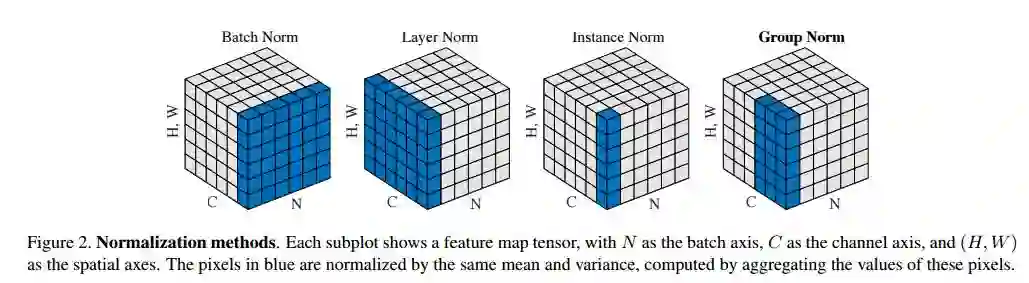
期刊:arXiv, 2018年3月23日
网址:
http://www.zhuanzhi.ai/document/dfc73cf6728c3caef9f50672e18ffc1d
4. MLtuner: System Support for Automatic Machine Learning Tuning(MLtuner: 系统支持自动机器学习调优)
作者:Henggang Cui,Gregory R. Ganger,Phillip B. Gibbons
机构:Carnegie Mellon University
摘要:MLtuner automatically tunes settings for training tunables (such as the learning rate, the momentum, the mini-batch size, and the data staleness bound) that have a significant impact on large-scale machine learning (ML) performance. Traditionally, these tunables are set manually, which is unsurprisingly error-prone and difficult to do without extensive domain knowledge. MLtuner uses efficient snapshotting, branching, and optimization-guided online trial-and-error to find good initial settings as well as to re-tune settings during execution. Experiments show that MLtuner can robustly find and re-tune tunable settings for a variety of ML applications, including image classification (for 3 models and 2 datasets), video classification, and matrix factorization. Compared to state-of-the-art ML auto-tuning approaches, MLtuner is more robust for large problems and over an order of magnitude faster.
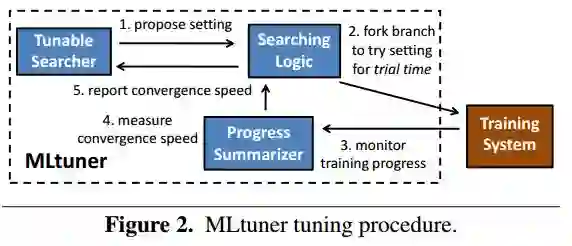
期刊:arXiv, 2018年3月20日
网址:
http://www.zhuanzhi.ai/document/5803972ddb941d18dd2cd93d89b8b10b
5. Learning Representative Temporal Features for Action Recognition(学习具有代表性的动作识别的时序特征)
作者:Ali Javidani,Ahmad Mahmoudi-Aznaveh
摘要:In this paper, a novel video classification methodology is presented that aims to recognize different categories of third-person videos efficiently. The idea is to keep track of motion in videos by following optical flow elements over time. To classify the resulted motion time series efficiently, the idea is letting the machine to learn temporal features along the time dimension. This is done by training a multi-channel one dimensional Convolutional Neural Network (1D-CNN). Since CNNs represent the input data hierarchically, high level features are obtained by further processing of features in lower level layers. As a result, in the case of time series, long-term temporal features are extracted from short-term ones. Besides, the superiority of the proposed method over most of the deep-learning based approaches is that we only try to learn representative temporal features along the time dimension. This reduces the number of learning parameters significantly which results in trainability of our method on even smaller datasets. It is illustrated that the proposed method could reach state-of-the-art results on two public datasets UCF11 and jHMDB with the aid of a more efficient feature vector representation.
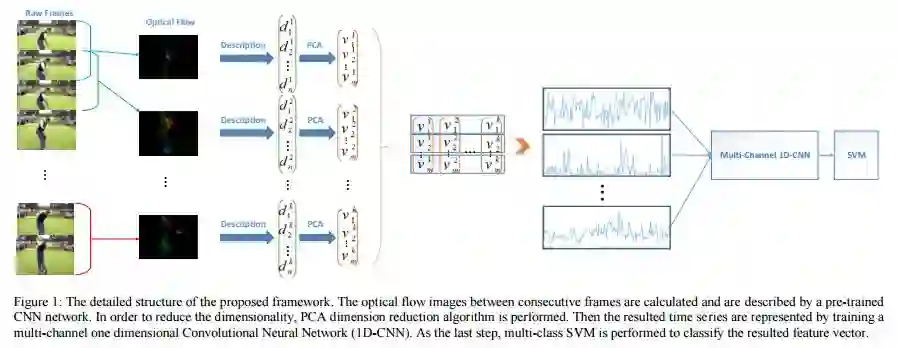
期刊:arXiv, 2018年3月14日
网址:
http://www.zhuanzhi.ai/document/54ce5dc067ce56e4930a75ea67e830d4
-END-
专 · 知
人工智能领域主题知识资料查看获取:【专知荟萃】人工智能领域26个主题知识资料全集(入门/进阶/论文/综述/视频/专家等)
请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请扫一扫如下二维码关注我们的公众号,获取人工智能的专业知识!

请加专知小助手微信(Rancho_Fang),加入专知主题人工智能群交流!加入专知主题群(请备注主题类型:AI、NLP、CV、 KG等)交流~
投稿&广告&商务合作:fangquanyi@gmail.com
点击“阅读原文”,使用专知




