【论文推荐】最新7篇条件随机场(CRF)相关论文—图像标注、对抗学习、端到端、注意力机制、三维人体姿态、图像分割、行为分割和识别
【导读】专知内容组整理了最近七篇条件随机场(Conditional Random Field )相关文章,为大家进行介绍,欢迎查看!
1. Deep Neural Networks In Fully Connected CRF For Image Labeling With Social Network Metadata(结合社交网络元数据的图像标注:全连接CRF的深度神经网络方法)
作者:Chengjiang Long,Roddy Collins,Eran Swears,Anthony Hoogs
摘要:We propose a novel method for predicting image labels by fusing image content descriptors with the social media context of each image. An image uploaded to a social media site such as Flickr often has meaningful, associated information, such as comments and other images the user has uploaded, that is complementary to pixel content and helpful in predicting labels. Prediction challenges such as ImageNet~\cite{imagenet_cvpr09} and MSCOCO~\cite{LinMBHPRDZ:ECCV14} use only pixels, while other methods make predictions purely from social media context \cite{McAuleyECCV12}. Our method is based on a novel fully connected Conditional Random Field (CRF) framework, where each node is an image, and consists of two deep Convolutional Neural Networks (CNN) and one Recurrent Neural Network (RNN) that model both textual and visual node/image information. The edge weights of the CRF graph represent textual similarity and link-based metadata such as user sets and image groups. We model the CRF as an RNN for both learning and inference, and incorporate the weighted ranking loss and cross entropy loss into the CRF parameter optimization to handle the training data imbalance issue. Our proposed approach is evaluated on the MIR-9K dataset and experimentally outperforms current state-of-the-art approaches.

网址:
http://www.zhuanzhi.ai/document/6c2a100a9db96cbfdb6a47127675969b
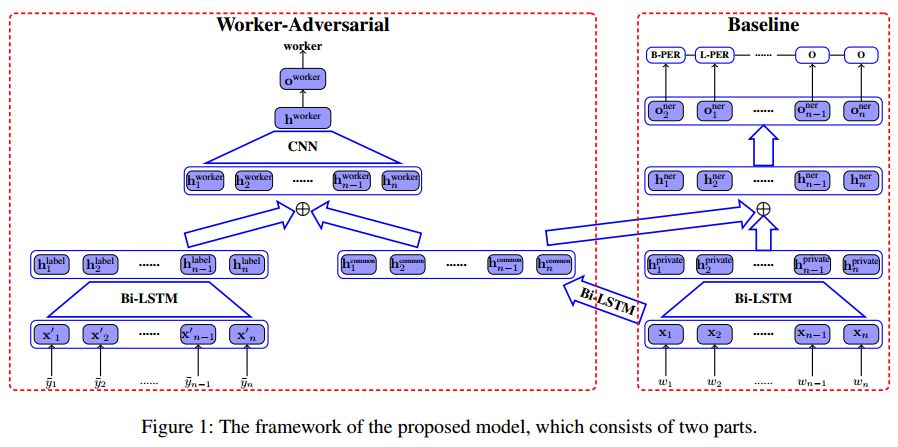
2. Adversarial Learning for Chinese NER from Crowd Annotations(基于众包机制对抗学习的中文命名实体识别方法)
作者:YaoSheng Yang,Meishan Zhang,Wenliang Chen,Wei Zhang,Haofen Wang,Min Zhang
摘要:To quickly obtain new labeled data, we can choose crowdsourcing as an alternative way at lower cost in a short time. But as an exchange, crowd annotations from non-experts may be of lower quality than those from experts. In this paper, we propose an approach to performing crowd annotation learning for Chinese Named Entity Recognition (NER) to make full use of the noisy sequence labels from multiple annotators. Inspired by adversarial learning, our approach uses a common Bi-LSTM and a private Bi-LSTM for representing annotator-generic and -specific information. The annotator-generic information is the common knowledge for entities easily mastered by the crowd. Finally, we build our Chinese NE tagger based on the LSTM-CRF model. In our experiments, we create two data sets for Chinese NER tasks from two domains. The experimental results show that our system achieves better scores than strong baseline systems.
期刊:arXiv, 2018年1月16日
网址:
http://www.zhuanzhi.ai/document/03ad7c4b7ace464f54bdc0003e5fb9b3
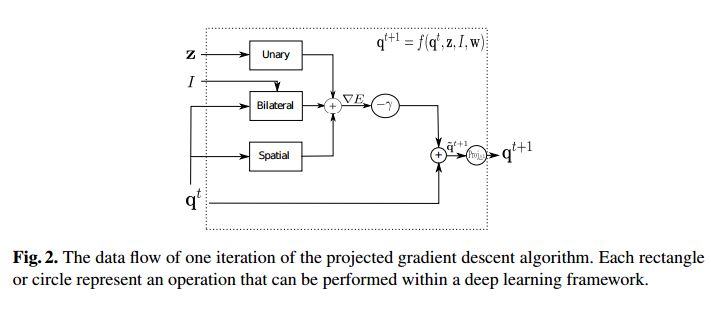
3. A Projected Gradient Descent Method for CRF Inference allowing End-To-End Training of Arbitrary Pairwise Potentials(一种用于CRF推理的投影梯度下降法,允许对任意的成对电位进行端到端训练)
作者:Måns Larsson,Anurag Arnab,Fredrik Kahl,Shuai Zheng,Philip Torr
摘要:Are we using the right potential functions in the Conditional Random Field models that are popular in the Vision community? Semantic segmentation and other pixel-level labelling tasks have made significant progress recently due to the deep learning paradigm. However, most state-of-the-art structured prediction methods also include a random field model with a hand-crafted Gaussian potential to model spatial priors, label consistencies and feature-based image conditioning. In this paper, we challenge this view by developing a new inference and learning framework which can learn pairwise CRF potentials restricted only by their dependence on the image pixel values and the size of the support. Both standard spatial and high-dimensional bilateral kernels are considered. Our framework is based on the observation that CRF inference can be achieved via projected gradient descent and consequently, can easily be integrated in deep neural networks to allow for end-to-end training. It is empirically demonstrated that such learned potentials can improve segmentation accuracy and that certain label class interactions are indeed better modelled by a non-Gaussian potential. In addition, we compare our inference method to the commonly used mean-field algorithm. Our framework is evaluated on several public benchmarks for semantic segmentation with improved performance compared to previous state-of-the-art CNN+CRF models.
期刊:arXiv, 2018年1月2日
网址:
http://www.zhuanzhi.ai/document/f27a61ce53c80d902403035a0447a3c4
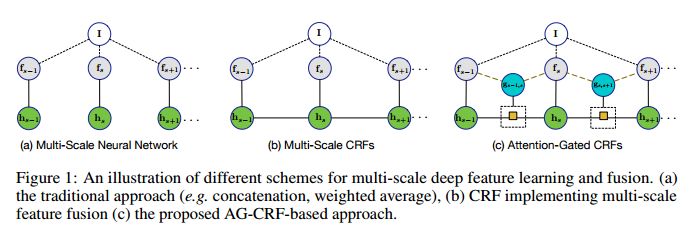
4. Learning Deep Structured Multi-Scale Features using Attention-Gated CRFs for Contour Prediction(利用注意力机制的CRFs学习深度结构的多尺度特征进行轮廓预测)
作者:Dan Xu,Wanli Ouyang,Xavier Alameda-Pineda,Elisa Ricci,Xiaogang Wang,Nicu Sebe
摘要:Recent works have shown that exploiting multi-scale representations deeply learned via convolutional neural networks (CNN) is of tremendous importance for accurate contour detection. This paper presents a novel approach for predicting contours which advances the state of the art in two fundamental aspects, i.e. multi-scale feature generation and fusion. Different from previous works directly consider- ing multi-scale feature maps obtained from the inner layers of a primary CNN architecture, we introduce a hierarchical deep model which produces more rich and complementary representations. Furthermore, to refine and robustly fuse the representations learned at different scales, the novel Attention-Gated Conditional Random Fields (AG-CRFs) are proposed. The experiments ran on two publicly available datasets (BSDS500 and NYUDv2) demonstrate the effectiveness of the latent AG-CRF model and of the overall hierarchical framework.
期刊:arXiv, 2018年1月2日
网址:
http://www.zhuanzhi.ai/document/07566a15d9798204db8b23f8aab9d828
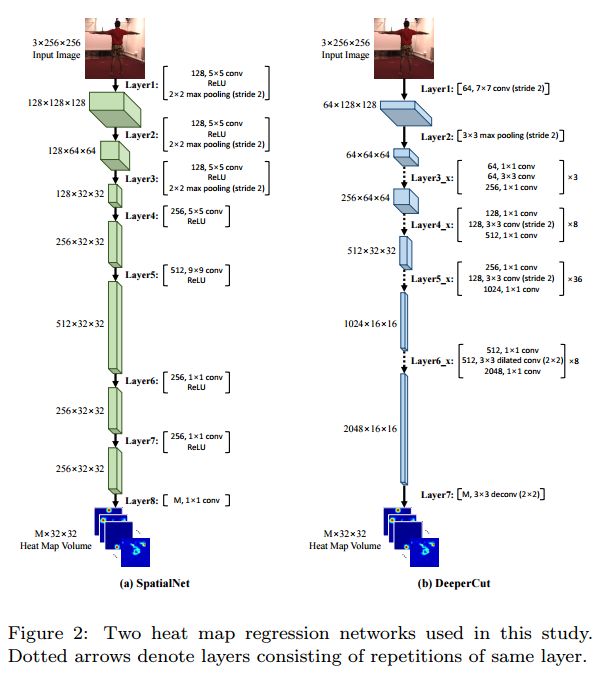
5. 2D-3D Pose Consistency-based Conditional Random Fields for 3D Human Pose Estimation(基于2D-3D姿态一致性的条件随机场的三维人体姿态估计)
作者:Ju Yong Chang,Kyoung Mu Lee
摘要:This study considers the 3D human pose estimation problem in a single RGB image by proposing a conditional random field (CRF) model over 2D poses, in which the 3D pose is obtained as a byproduct of the inference process. The unary term of the proposed CRF model is defined based on a powerful heat-map regression network, which has been proposed for 2D human pose estimation. This study also presents a regression network for lifting the 2D pose to 3D pose and proposes the prior term based on the consistency between the estimated 3D pose and the 2D pose. To obtain the approximate solution of the proposed CRF model, the N-best strategy is adopted. The proposed inference algorithm can be viewed as sequential processes of bottom-up generation of 2D and 3D pose proposals from the input 2D image based on deep networks and top-down verification of such proposals by checking their consistencies. To evaluate the proposed method, we use two large-scale datasets: Human3.6M and HumanEva. Experimental results show that the proposed method achieves the state-of-the-art 3D human pose estimation performance.
期刊:arXiv, 2017年12月28日
网址:
http://www.zhuanzhi.ai/document/352a0d2a77c7b0bbaeef9902abcd21be
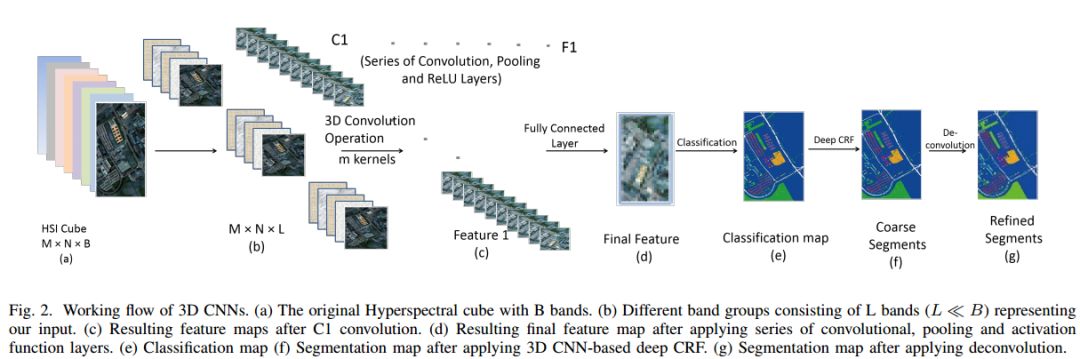
6. Conditional Random Field and Deep Feature Learning for Hyperspectral Image Segmentation(基于条件随机场和深度特征学习的高光谱图像分割)
作者:Fahim Irfan Alam,Jun Zhou,Alan Wee-Chung Liew,Xiuping Jia,Jocelyn Chanussot,Yongsheng Gao
摘要:Network Virtualization is one of the most promising technologies for future networking and considered as a critical IT resource that connects distributed, virtualized Cloud Computing services and different components such as storage, servers and application. Network Virtualization allows multiple virtual networks to coexist on same shared physical infrastructure simultaneously. One of the crucial keys in Network Virtualization is Virtual Network Embedding, which provides a method to allocate physical substrate resources to virtual network requests. In this paper, we investigate Virtual Network Embedding strategies and related issues for resource allocation of an Internet Provider(InP) to efficiently embed virtual networks that are requested by Virtual Network Operators(VNOs) who share the same infrastructure provided by the InP. In order to achieve that goal, we design a heuristic Virtual Network Embedding algorithm that simultaneously embeds virtual nodes and virtual links of each virtual network request onto physic infrastructure. Through extensive simulations, we demonstrate that our proposed scheme improves significantly the performance of Virtual Network Embedding by enhancing the long-term average revenue as well as acceptance ratio and resource utilization of virtual network requests compared to prior algorithms.
期刊:arXiv, 2017年12月27日
网址:
http://www.zhuanzhi.ai/document/0d0b73aec22f09677393117c0e5af8d9
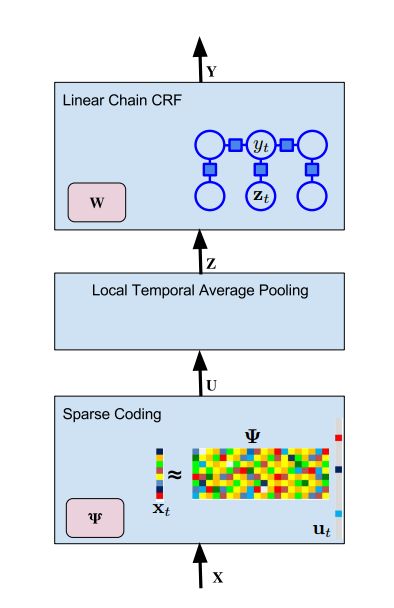
7. End-to-End Fine-Grained Action Segmentation and Recognition Using Conditional Random Field Models and Discriminative Sparse Coding(基于条件随机场模型和判别稀疏编码的端到端细粒度行为分割和识别)
作者:Effrosyni Mavroudi,Divya Bhaskara,Shahin Sefati,Haider Ali,René Vidal
摘要:Fine-grained action segmentation and recognition is an important yet challenging task. Given a long, untrimmed sequence of kinematic data, the task is to classify the action at each time frame and segment the time series into the correct sequence of actions. In this paper, we propose a novel framework that combines a temporal Conditional Random Field (CRF) model with a powerful frame-level representation based on discriminative sparse coding. We introduce an end-to-end algorithm for jointly learning the weights of the CRF model, which include action classification and action transition costs, as well as an overcomplete dictionary of mid-level action primitives. This results in a CRF model that is driven by sparse coding features obtained using a discriminative dictionary that is shared among different actions and adapted to the task of structured output learning. We evaluate our method on three surgical tasks using kinematic data from the JIGSAWS dataset, as well as on a food preparation task using accelerometer data from the 50 Salads dataset. Our results show that the proposed method performs on par or better than state-of-the-art methods.
期刊:arXiv, 2018年1月29日
网址:
http://www.zhuanzhi.ai/document/55105800c4988d2e0244ce94fc001536
-END-
专 · 知
人工智能领域主题知识资料查看获取:【专知荟萃】人工智能领域26个主题知识资料全集(入门/进阶/论文/综述/视频/专家等)
同时欢迎各位用户进行专知投稿,详情请点击:
【诚邀】专知诚挚邀请各位专业者加入AI创作者计划!了解使用专知!
请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请扫一扫如下二维码关注我们的公众号,获取人工智能的专业知识!

请加专知小助手微信(Rancho_Fang),加入专知主题人工智能群交流!
点击“阅读原文”,使用专知!





