【论文推荐】最新八篇图像描述生成相关论文—比较级对抗学习、正则化RNNs、深层网络、视觉对话、婴儿说话、自我检索
【导读】专知内容组整理了最近八篇图像描述生成(Image Captioning)相关文章,为大家进行介绍,欢迎查看!
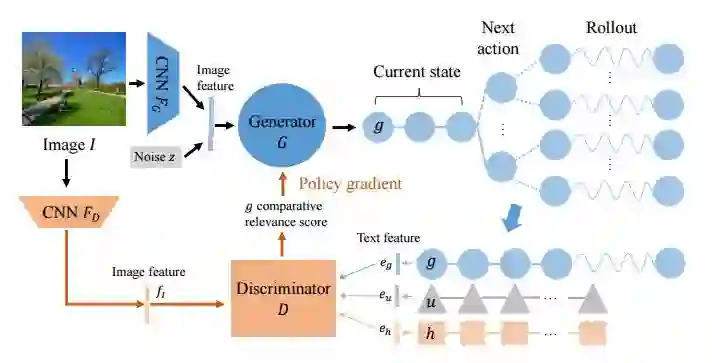
1.Generating Diverse and Accurate Visual Captions by Comparative Adversarial Learning(通过比较级对抗学习产生多样而准确的视觉描述)
作者:Dianqi Li,Qiuyuan Huang,Xiaodong He,Lei Zhang,Ming-Ting Sun
机构:University of Washington,Microsoft Research
摘要:We study how to generate captions that are not only accurate in describing an image but also discriminative across different images. The problem is both fundamental and interesting, as most machine-generated captions, despite phenomenal research progresses in the past several years, are expressed in a very monotonic and featureless format. While such captions are normally accurate, they often lack important characteristics in human languages - distinctiveness for each caption and diversity for different images. To address this problem, we propose a novel conditional generative adversarial network for generating diverse captions across images. Instead of estimating the quality of a caption solely on one image, the proposed comparative adversarial learning framework better assesses the quality of captions by comparing a set of captions within the image-caption joint space. By contrasting with human-written captions and image-mismatched captions, the caption generator effectively exploits the inherent characteristics of human languages, and generates more discriminative captions. We show that our proposed network is capable of producing accurate and diverse captions across images.
期刊:arXiv, 2018年4月11日
网址:
http://www.zhuanzhi.ai/document/f4a3a35025bdebdbe8f9c56ae20b93a0
2.Decoupled Novel Object Captioner(解耦的新颖物体描述方法)
作者:Yu Wu,Linchao Zhu,Lu Jiang,Yi Yang
机构:University of Technology Sydney
摘要:Image captioning is a challenging task where the machine automatically describes an image by sentences or phrases. It often requires a large number of paired image-sentence annotations for training. However, a pre-trained captioning model can hardly be applied to a new domain in which some novel object categories exist, i.e., the objects and their description words are unseen during model training. To correctly caption the novel object, it requires professional human workers to annotate the images by sentences with the novel words. It is labor expensive and thus limits its usage in real-world applications. In this paper, we introduce the zero-shot novel object captioning task where the machine generates descriptions without extra sentences about the novel object. To tackle the challenging problem, we propose a Decoupled Novel Object Captioner (DNOC) framework that can fully decouple the language sequence model from the object descriptions. DNOC has two components. 1) A Sequence Model with the Placeholder (SM-P) generates a sentence containing placeholders. The placeholder represents an unseen novel object. Thus, the sequence model can be decoupled from the novel object descriptions. 2) A key-value object memory built upon the freely available detection model, contains the visual information and the corresponding word for each object. The SM-P will generate a query to retrieve the words from the object memory. The placeholder will then be filled with the correct word, resulting in a caption with novel object descriptions. The experimental results on the held-out MSCOCO dataset demonstrate the ability of DNOC in describing novel concepts in the zero-shot novel object captioning task.

期刊:arXiv, 2018年4月11日
网址:
http://www.zhuanzhi.ai/document/61feb1b265ff63779ace64d60e6b489c
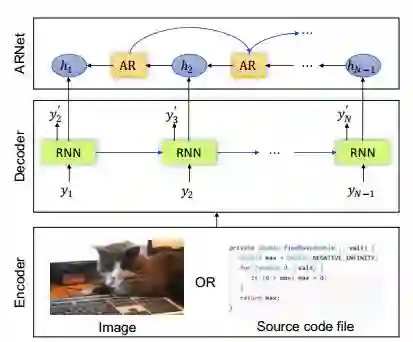
3.Regularizing RNNs for Caption Generation by Reconstructing The Past with The Present(基于重构过去与现在的正则化RNNs的描述生成)
作者:Xinpeng Chen,Lin Ma,Wenhao Jiang,Jian Yao,Wei Liu
机构:Wuhan University,Tencent AI Lab
摘要:Recently, caption generation with an encoder-decoder framework has been extensively studied and applied in different domains, such as image captioning, code captioning, and so on. In this paper, we propose a novel architecture, namely Auto-Reconstructor Network (ARNet), which, coupling with the conventional encoder-decoder framework, works in an end-to-end fashion to generate captions. ARNet aims at reconstructing the previous hidden state with the present one, besides behaving as the input-dependent transition operator. Therefore, ARNet encourages the current hidden state to embed more information from the previous one, which can help regularize the transition dynamics of recurrent neural networks (RNNs). Extensive experimental results show that our proposed ARNet boosts the performance over the existing encoder-decoder models on both image captioning and source code captioning tasks. Additionally, ARNet remarkably reduces the discrepancy between training and inference processes for caption generation. Furthermore, the performance on permuted sequential MNIST demonstrates that ARNet can effectively regularize RNN, especially on modeling long-term dependencies. Our code is available at: https://github.com/chenxinpeng/ARNet
期刊:arXiv, 2018年4月7日
网址:
http://www.zhuanzhi.ai/document/6524664f920f56938c7a336e7a813ae7
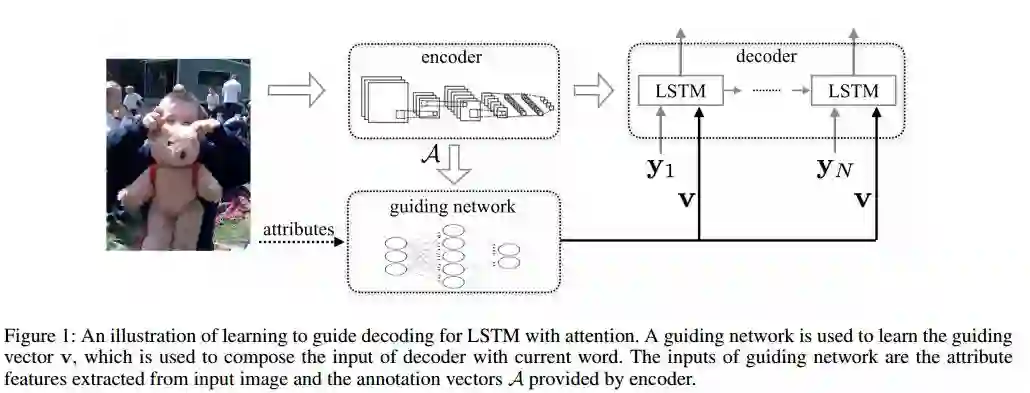
4.Learning to Guide Decoding for Image Captioning(学习去引导解码图像描述)
作者:Wenhao Jiang,Lin Ma,Xinpeng Chen,Hanwang Zhang,Wei Liu
机构:Nanyang Technological University,Wuhan University
摘要:Recently, much advance has been made in image captioning, and an encoder-decoder framework has achieved outstanding performance for this task. In this paper, we propose an extension of the encoder-decoder framework by adding a component called guiding network. The guiding network models the attribute properties of input images, and its output is leveraged to compose the input of the decoder at each time step. The guiding network can be plugged into the current encoder-decoder framework and trained in an end-to-end manner. Hence, the guiding vector can be adaptively learned according to the signal from the decoder, making itself to embed information from both image and language. Additionally, discriminative supervision can be employed to further improve the quality of guidance. The advantages of our proposed approach are verified by experiments carried out on the MS COCO dataset.
期刊:arXiv, 2018年4月3日
网址:
http://www.zhuanzhi.ai/document/5f37f057c35d0b2d9710d7cc4c58a145
5.Guide Me: Interacting with Deep Networks(Guide Me:与深层网络互动)
作者:Christian Rupprecht,Iro Laina,Nassir Navab,Gregory D. Hager,Federico Tombari
机构:Technische Universitat M¨ unchen,Johns Hopkins University
摘要:Interaction and collaboration between humans and intelligent machines has become increasingly important as machine learning methods move into real-world applications that involve end users. While much prior work lies at the intersection of natural language and vision, such as image captioning or image generation from text descriptions, less focus has been placed on the use of language to guide or improve the performance of a learned visual processing algorithm. In this paper, we explore methods to flexibly guide a trained convolutional neural network through user input to improve its performance during inference. We do so by inserting a layer that acts as a spatio-semantic guide into the network. This guide is trained to modify the network's activations, either directly via an energy minimization scheme or indirectly through a recurrent model that translates human language queries to interaction weights. Learning the verbal interaction is fully automatic and does not require manual text annotations. We evaluate the method on two datasets, showing that guiding a pre-trained network can improve performance, and provide extensive insights into the interaction between the guide and the CNN.

期刊:arXiv, 2018年3月31日
网址:
http://www.zhuanzhi.ai/document/6befbf6f8ae65656918eaed680e6a5bc
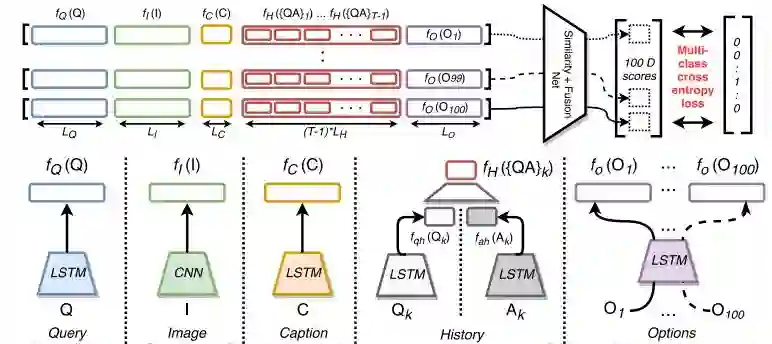
6.Two can play this Game: Visual Dialog with Discriminative Question Generation and Answering(两个可以玩这个游戏:通过视觉对话产生和回答有辨别力的问题)
作者:Unnat Jain,Svetlana Lazebnik,Alexander Schwing
摘要:Human conversation is a complex mechanism with subtle nuances. It is hence an ambitious goal to develop artificial intelligence agents that can participate fluently in a conversation. While we are still far from achieving this goal, recent progress in visual question answering, image captioning, and visual question generation shows that dialog systems may be realizable in the not too distant future. To this end, a novel dataset was introduced recently and encouraging results were demonstrated, particularly for question answering. In this paper, we demonstrate a simple symmetric discriminative baseline, that can be applied to both predicting an answer as well as predicting a question. We show that this method performs on par with the state of the art, even memory net based methods. In addition, for the first time on the visual dialog dataset, we assess the performance of a system asking questions, and demonstrate how visual dialog can be generated from discriminative question generation and question answering.
期刊:arXiv, 2018年3月30日
网址:
http://www.zhuanzhi.ai/document/8f1d5d863cc03d7b3eff2f2fa29cd19d
7.Neural Baby Talk(神经婴儿说话)
作者:Jiasen Lu,Jianwei Yang,Dhruv Batra,Devi Parikh
摘要:We introduce a novel framework for image captioning that can produce natural language explicitly grounded in entities that object detectors find in the image. Our approach reconciles classical slot filling approaches (that are generally better grounded in images) with modern neural captioning approaches (that are generally more natural sounding and accurate). Our approach first generates a sentence `template' with slot locations explicitly tied to specific image regions. These slots are then filled in by visual concepts identified in the regions by object detectors. The entire architecture (sentence template generation and slot filling with object detectors) is end-to-end differentiable. We verify the effectiveness of our proposed model on different image captioning tasks. On standard image captioning and novel object captioning, our model reaches state-of-the-art on both COCO and Flickr30k datasets. We also demonstrate that our model has unique advantages when the train and test distributions of scene compositions -- and hence language priors of associated captions -- are different. Code has been made available at: https://github.com/jiasenlu/NeuralBabyTalk
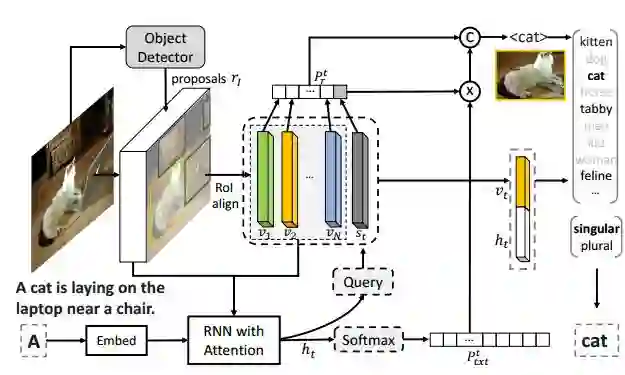
期刊:arXiv, 2018年3月27日
网址:
http://www.zhuanzhi.ai/document/bcc80072e7c8b2aa341e4ad8af8640ff
8.Show, Tell and Discriminate: Image Captioning by Self-retrieval with Partially Labeled Data(显示、叙述和辨别:利用部分标记的数据自我检索的图像描述生成)
作者:Xihui Liu,Hongsheng Li,Jing Shao,Dapeng Chen,Xiaogang Wang
机构:The Chinese University of Hong Kong
摘要:The aim of image captioning is to generate similar captions by machine as human do to describe image contents. Despite many efforts, generating discriminative captions for images remains non-trivial. Most traditional approaches imitate the language structure patterns, thus tend to fall into a stereotype of replicating frequent phrases or sentences and neglect unique aspects of each image. In this work, we propose an image captioning framework with a self-retrieval module as training guidance, which encourages generating discriminative captions. It brings unique advantages: (1) the self-retrieval guidance can act as a metric and an evaluator of caption discriminativeness to assure the quality of generated captions. (2) The correspondence between generated captions and images are naturally incorporated in the generation process without human annotations, and hence our approach could utilize a large amount of unlabeled images to boost captioning performance with no additional laborious annotations. We demonstrate the effectiveness of the proposed retrieval-guided method on MS-COCO and Flickr30k captioning datasets, and show its superior captioning performance with more discriminative captions.
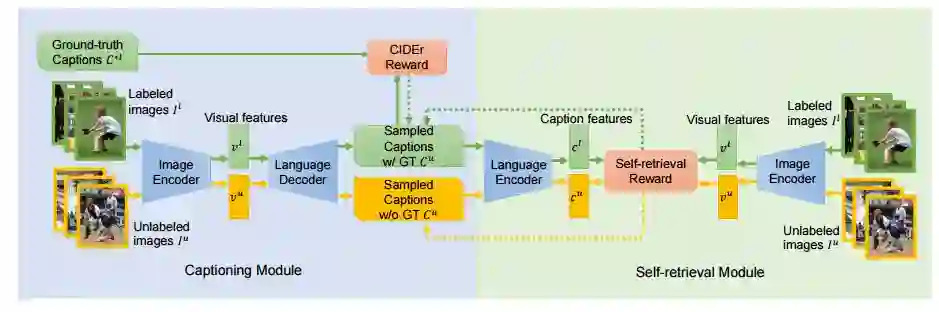
期刊:arXiv, 2018年3月22日
网址:
http://www.zhuanzhi.ai/document/42c6ed33b30160319eabe4944921d54a
-END-
专 · 知
人工智能领域主题知识资料查看获取:【专知荟萃】人工智能领域26个主题知识资料全集(入门/进阶/论文/综述/视频/专家等)
同时欢迎各位用户进行专知投稿,详情请点击:
【诚邀】专知诚挚邀请各位专业者加入AI创作者计划!了解使用专知!
请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请扫一扫如下二维码关注我们的公众号,获取人工智能的专业知识!

请加专知小助手微信(Rancho_Fang),加入专知主题人工智能群交流!加入专知主题群(请备注主题类型:AI、NLP、CV、 KG等)交流~
投稿&广告&商务合作:fangquanyi@gmail.com
点击“阅读原文”,使用专知





