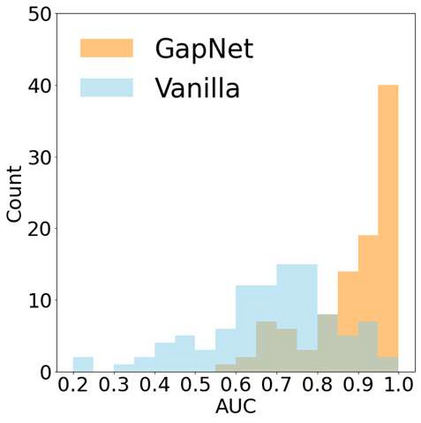
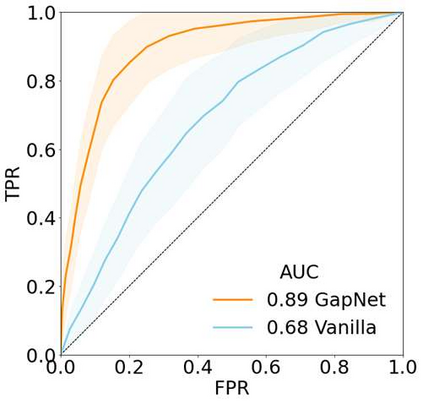
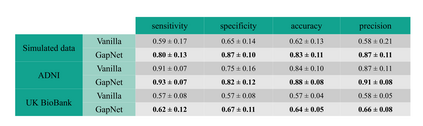
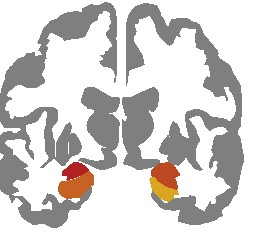
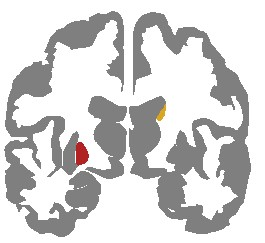
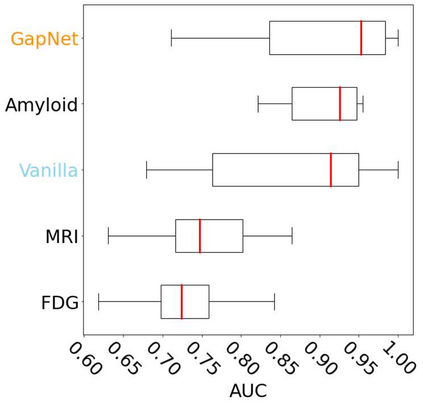
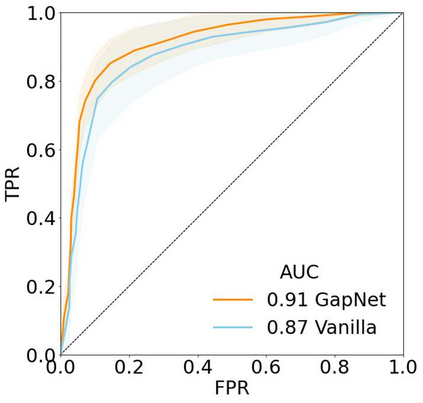
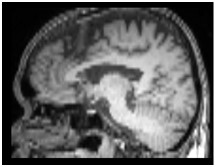
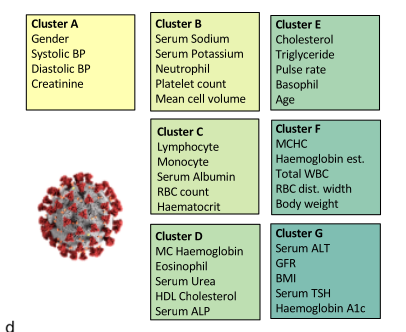
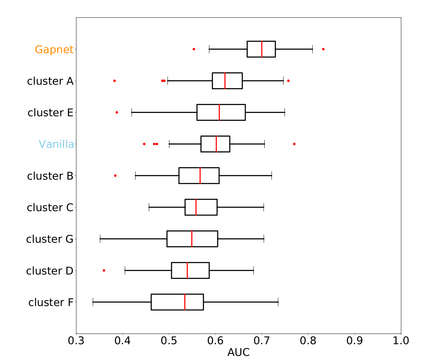
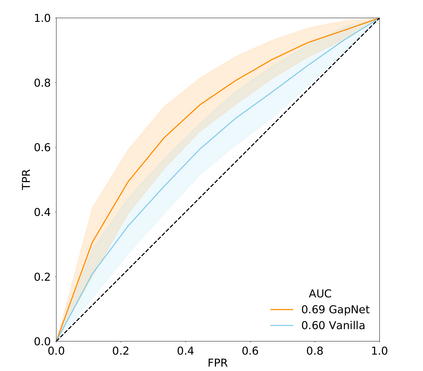
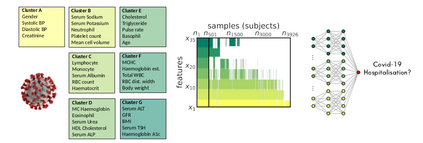
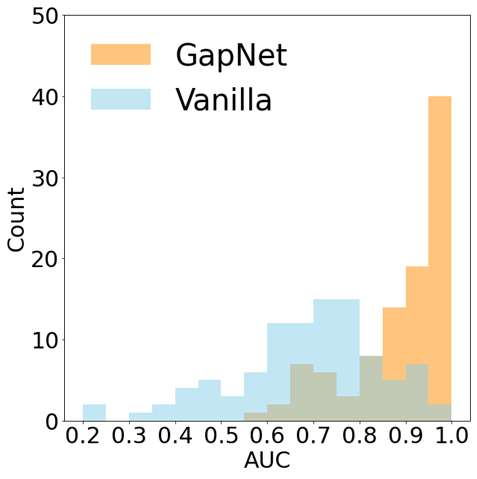
Neural network training and validation rely on the availability of large high-quality datasets. However, in many cases only incomplete datasets are available, particularly in health care applications, where each patient typically undergoes different clinical procedures or can drop out of a study. Since the data to train the neural networks need to be complete, most studies discard the incomplete datapoints, which reduces the size of the training data, or impute the missing features, which can lead to artefacts. Alas, both approaches are inadequate when a large portion of the data is missing. Here, we introduce GapNet, an alternative deep-learning training approach that can use highly incomplete datasets. First, the dataset is split into subsets of samples containing all values for a certain cluster of features. Then, these subsets are used to train individual neural networks. Finally, this ensemble of neural networks is combined into a single neural network whose training is fine-tuned using all complete datapoints. Using two highly incomplete real-world medical datasets, we show that GapNet improves the identification of patients with underlying Alzheimer's disease pathology and of patients at risk of hospitalization due to Covid-19. By distilling the information available in incomplete datasets without having to reduce their size or to impute missing values, GapNet will permit to extract valuable information from a wide range of datasets, benefiting diverse fields from medicine to engineering.
翻译:神经网络的培训和验证取决于大量高质量数据集的可用性。然而,在许多情况下,只能提供不完整的数据集,特别是在保健应用中,每个病人通常都经过不同的临床程序,或者可以退出研究。由于神经网络培训的数据需要完成,大多数研究抛弃了不完整的数据点,因为数据点减少了培训数据的规模,或者低估了缺失的特征,从而可能导致人工制品。唉,当数据缺少大量数据时,这两种方法都不够充分。在这里,我们引入GapNet,这是一种可以使用高度不完整数据集的替代深层次学习培训方法。首先,数据集被分成包含某些特征组的所有值的样本子组。然后,这些子组被用于培训单个神经网络。最后,神经网络的这一组合被合并成一个单一的神经网络网络,用所有完整的数据点对培训进行精确调整。使用两个高度不完整的真实世界医学数据集,我们展示GapNet改进了对具有基本老年痴呆症病病病病病病症病理学基础的病人的医学识别方法,并且将病人的精度分成了一组样本组,从而降低了他们住院到无法提取的宝贵数据的范围。