【推荐】决策树/随机森林深入解析
转自:爱可可_爱生活
The random forest has been a burgeoning machine learning technique in the last few years. It is a non-linear tree-based model that often provides accurate results. However, being mostly black box, it is oftentimes hard to interpret and fully understand. In this blog, we will deep dive into the fundamentals of random forests to better grasp them. We start by looking at the decision tree—the building block of the random forest. This work is an extension of the work done by Ando Saabas (https://github.com/andosa/treeinterpreter). Code to create the plots in this blog can be found on my GitHub.
How Do Decision Trees Work?
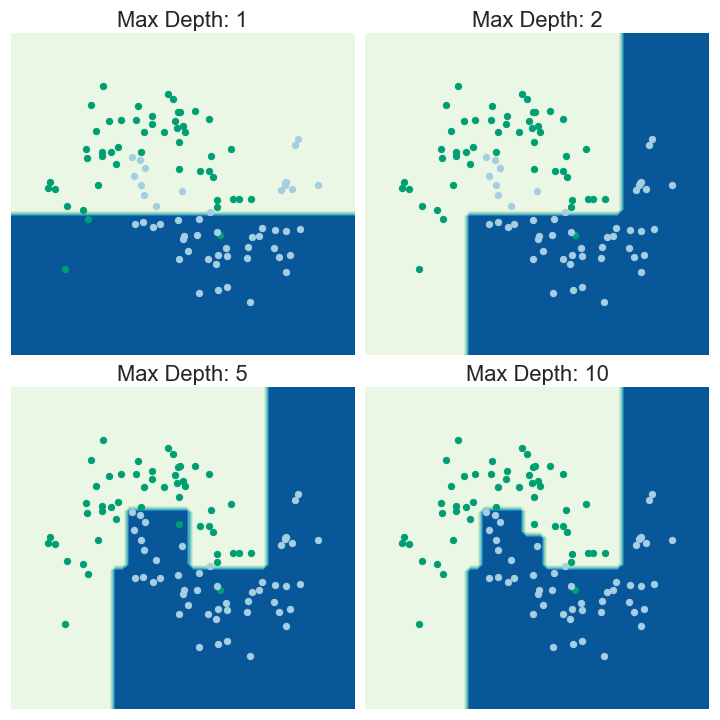
Decision trees work by iteratively splitting the data into distinct subsets in a greedy fashion. For regression trees, they are chosen to minimize either the MSE (mean squared error) or the MAE (mean absolute error) within all of the subsets. For classification trees, the splits are chosen so as to minimize entropy or Gini impurity in the resulting subsets.
The resulting classifier separates the feature space into distinct subsets. Prediction of an observation is made based on which subset the observation falls into.
Decision Tree Contributions
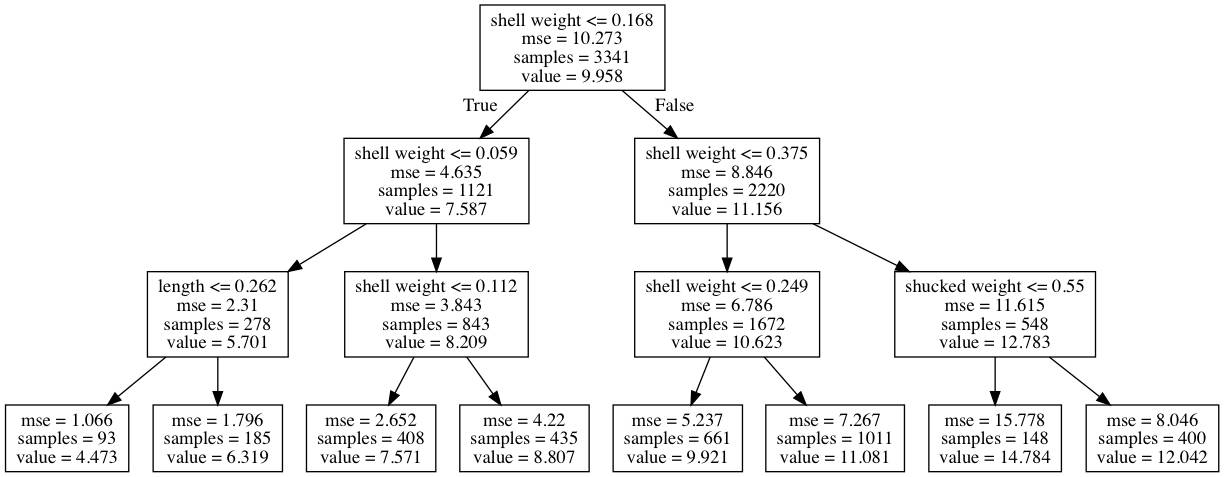
Let’s use the abalone data set as an example. We will try to predict the number of rings based on variables such as shell weight, length, diameter, etc. We fit a shallow decision tree for illustrative purposes. We achieve this by limiting the maximum depth of the tree to 3 levels.
链接:
http://engineering.pivotal.io/post/interpreting-decision-trees-and-random-forests/
原文链接:
https://m.weibo.cn/1402400261/4154291830791293



