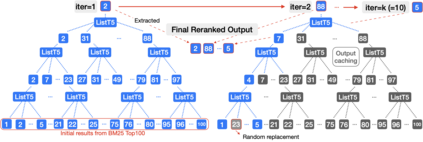
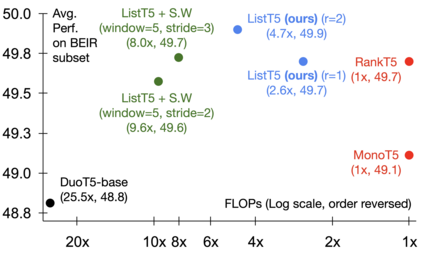
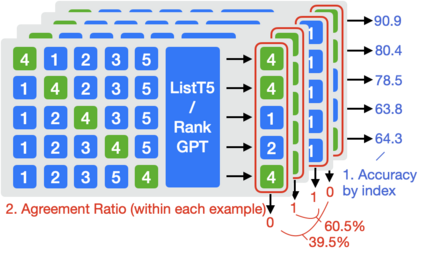
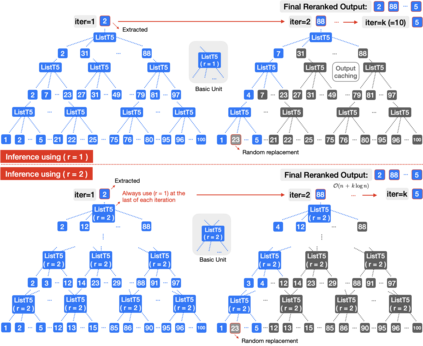
We propose ListT5, a novel reranking approach based on Fusion-in-Decoder (FiD) that handles multiple candidate passages at both train and inference time. We also introduce an efficient inference framework for listwise ranking based on m-ary tournament sort with output caching. We evaluate and compare our model on the BEIR benchmark for zero-shot retrieval task, demonstrating that ListT5 (1) outperforms the state-of-the-art RankT5 baseline with a notable +1.3 gain in the average NDCG@10 score, (2) has an efficiency comparable to pointwise ranking models and surpasses the efficiency of previous listwise ranking models, and (3) overcomes the lost-in-the-middle problem of previous listwise rerankers. Our code, model checkpoints, and the evaluation framework are fully open-sourced at \url{https://github.com/soyoung97/ListT5}.
翻译:暂无翻译