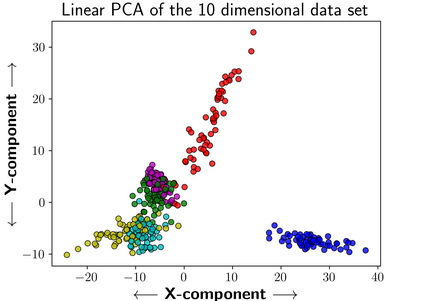
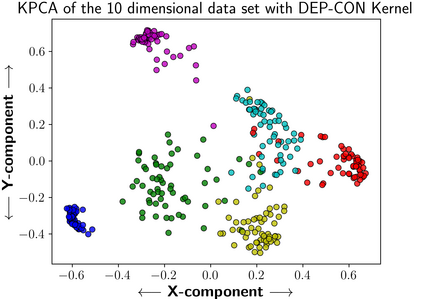
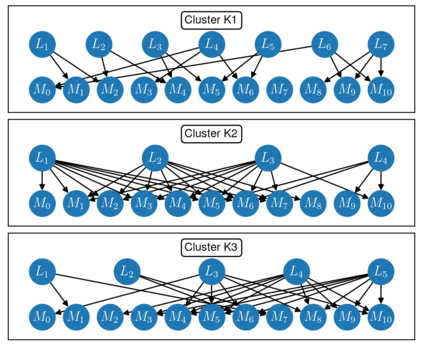
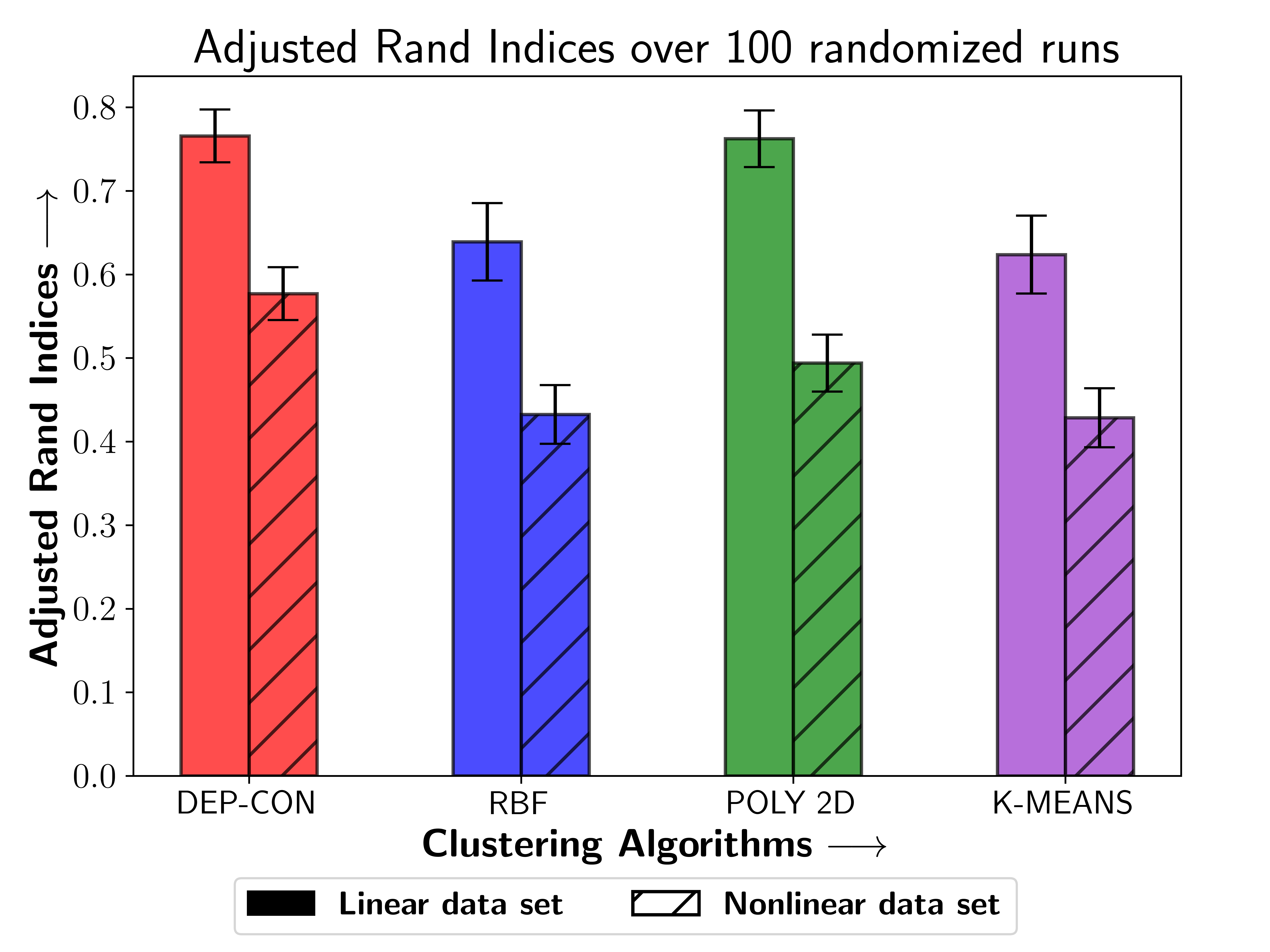
We consider the problem of causal structure learning in the setting of heterogeneous populations, i.e., populations in which a single causal structure does not adequately represent all population members, as is common in biological and social sciences. To this end, we introduce a distance covariance-based kernel designed specifically to measure the similarity between the underlying nonlinear causal structures of different samples. Indeed, we prove that the corresponding feature map is a statistically consistent estimator of nonlinear independence structure, rendering the kernel itself a statistical test for the hypothesis that sets of samples come from different generating causal structures. Even stronger, we prove that the kernel space is isometric to the space of causal ancestral graphs, so that distance between samples in the kernel space is guaranteed to correspond to distance between their generating causal structures. This kernel thus enables us to perform clustering to identify the homogeneous subpopulations, for which we can then learn causal structures using existing methods. Though we focus on the theoretical aspects of the kernel, we also evaluate its performance on synthetic data and demonstrate its use on a real gene expression data set.
翻译:我们考虑了不同人群(即生物和社会科学中常见的单一因果结构不能充分代表所有人口成员的人口)的因果结构学习问题。为此,我们引入了远程共变内核,专门用来测量不同样本的内在非线性因果结构之间的相似性。事实上,我们证明相应的特征图是统计上一致的非线性独立结构的估测器,使内核本身成为对不同因果结构产生样本组合的假设的统计测试。更强烈的是,我们证明内核空间与因果祖先图的空间是测量的,因此保证内核样本之间的距离与产生因果结构之间的距离相符。因此,这一内核使我们能够进行分组,以识别同质的亚人口群,然后用现有方法学习因果结构。尽管我们把重点放在了内核的理论方面,但我们也评估了其合成数据的性能,并展示其用于真实的基因表达数据集。