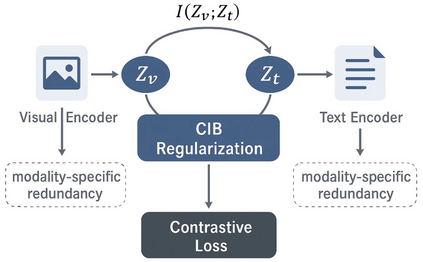
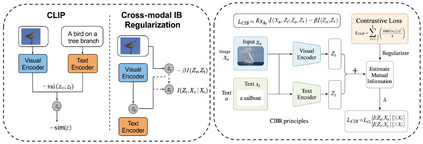
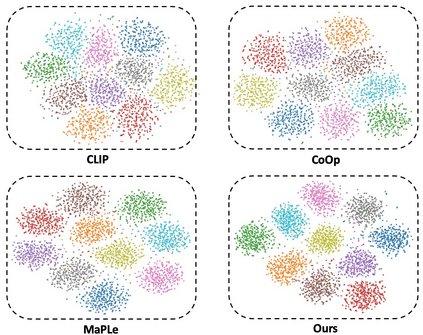
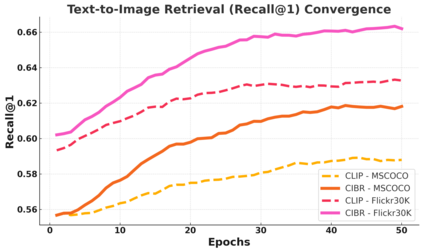
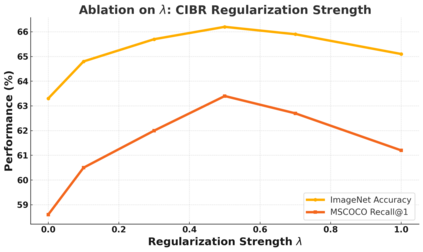
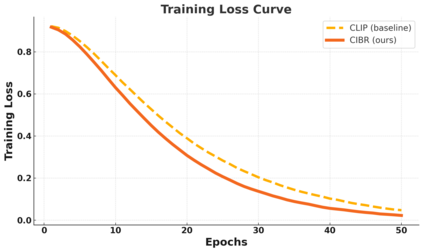
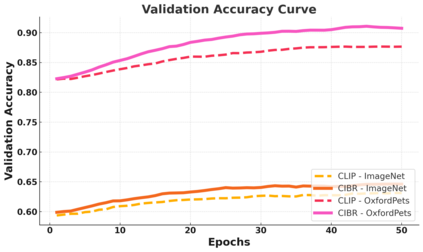
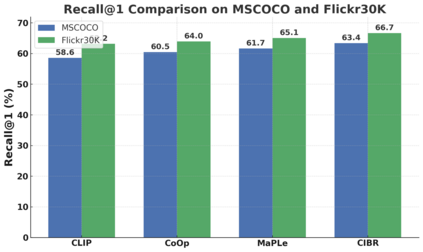
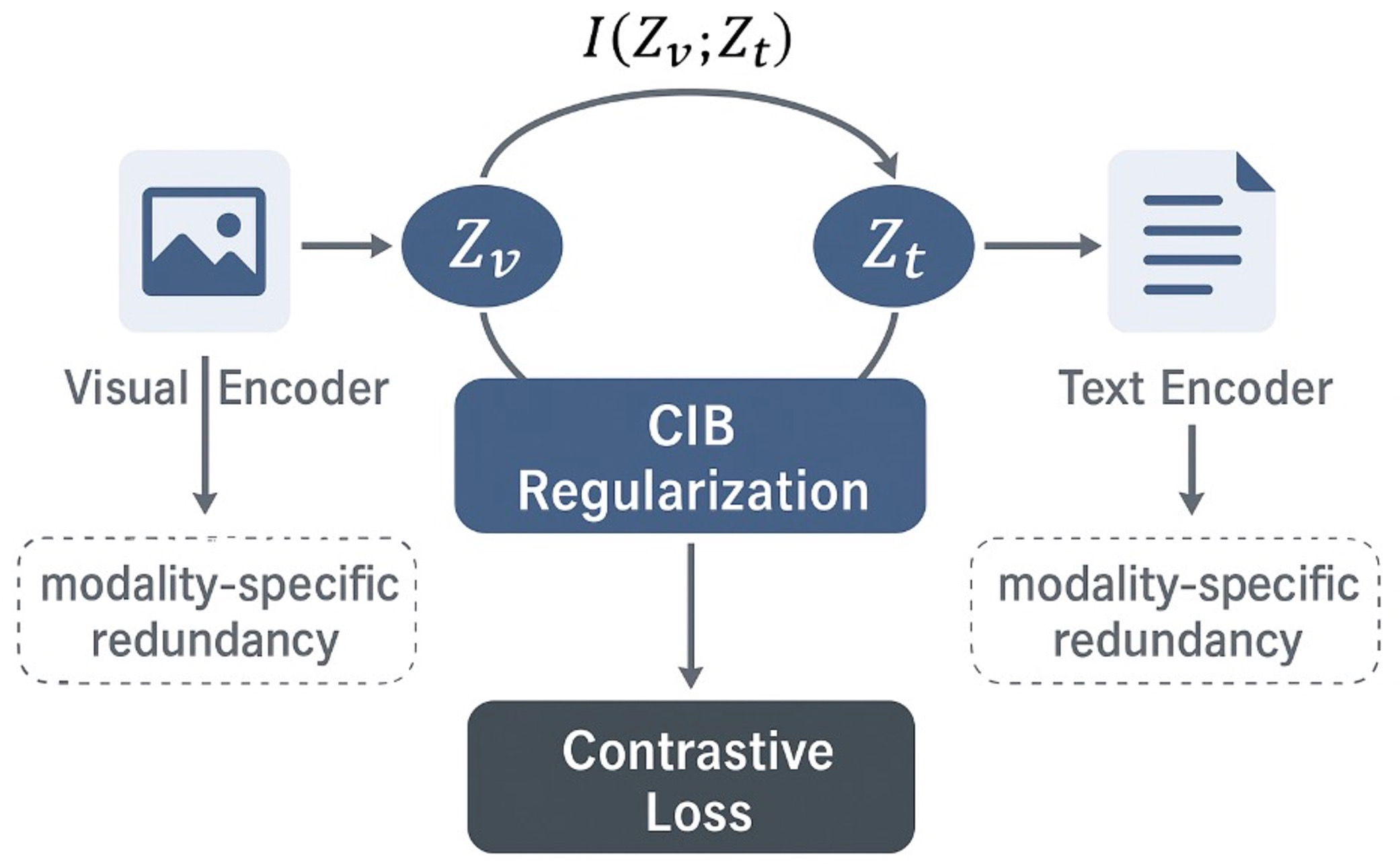
Contrastive Language-Image Pretraining (CLIP) has achieved remarkable success in cross-modal tasks such as zero-shot image classification and text-image retrieval by effectively aligning visual and textual representations. However, the theoretical foundations underlying CLIP's strong generalization remain unclear. In this work, we address this gap by proposing the Cross-modal Information Bottleneck (CIB) framework. CIB offers a principled interpretation of CLIP's contrastive learning objective as an implicit Information Bottleneck optimization. Under this view, the model maximizes shared cross-modal information while discarding modality-specific redundancies, thereby preserving essential semantic alignment across modalities. Building on this insight, we introduce a Cross-modal Information Bottleneck Regularization (CIBR) method that explicitly enforces these IB principles during training. CIBR introduces a penalty term to discourage modality-specific redundancy, thereby enhancing semantic alignment between image and text features. We validate CIBR on extensive vision-language benchmarks, including zero-shot classification across seven diverse image datasets and text-image retrieval on MSCOCO and Flickr30K. The results show consistent performance gains over standard CLIP. These findings provide the first theoretical understanding of CLIP's generalization through the IB lens. They also demonstrate practical improvements, offering guidance for future cross-modal representation learning.
翻译:暂无翻译