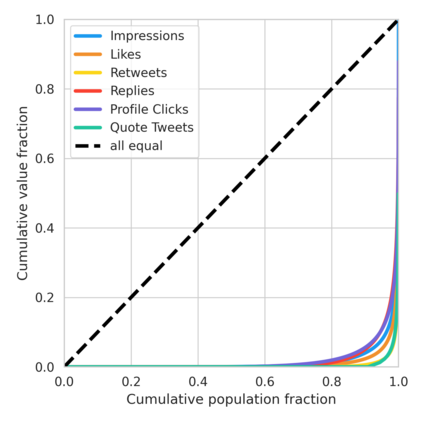
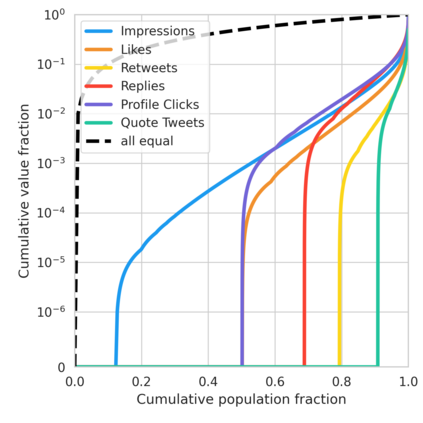
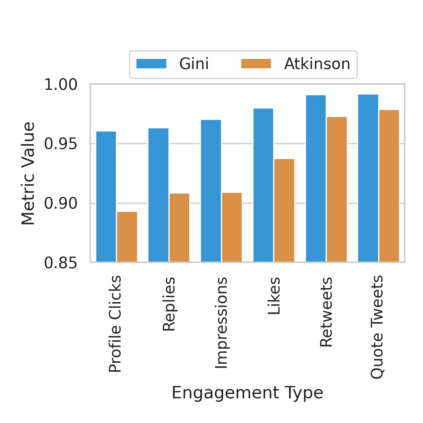
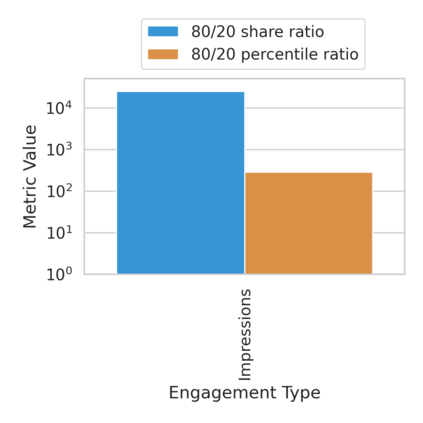
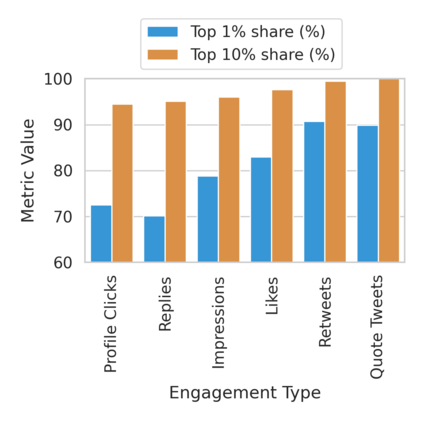
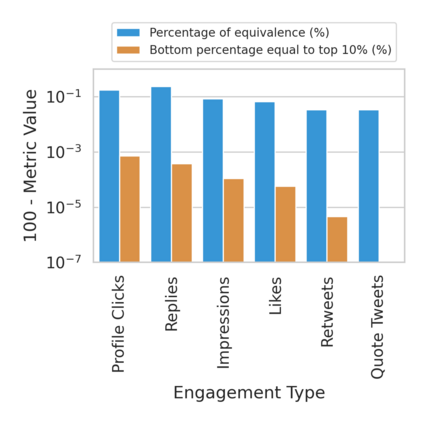
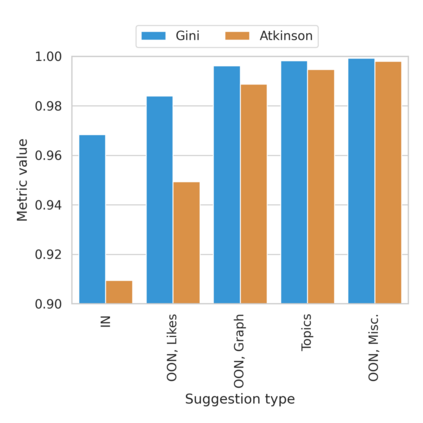
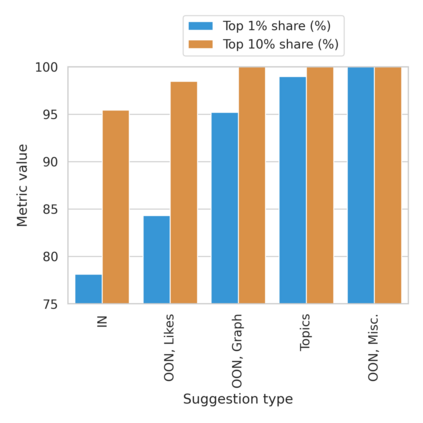
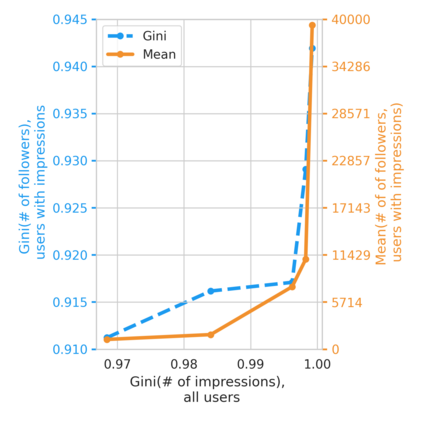
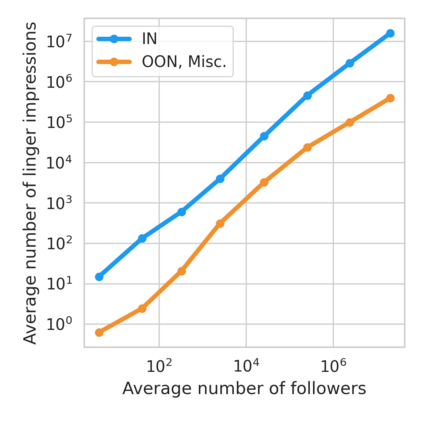
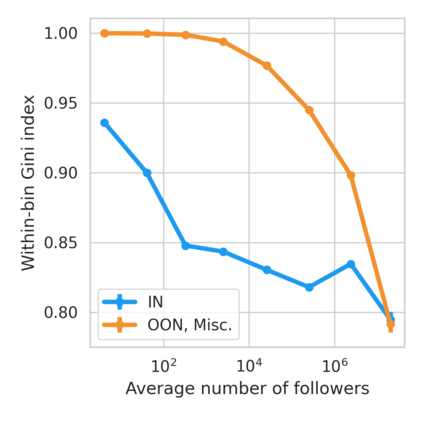
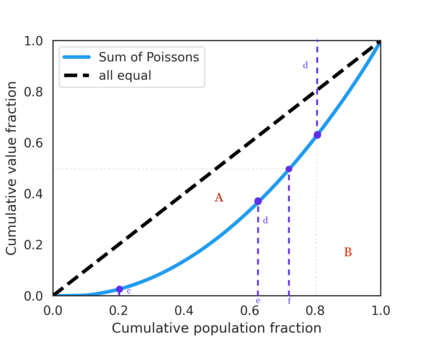
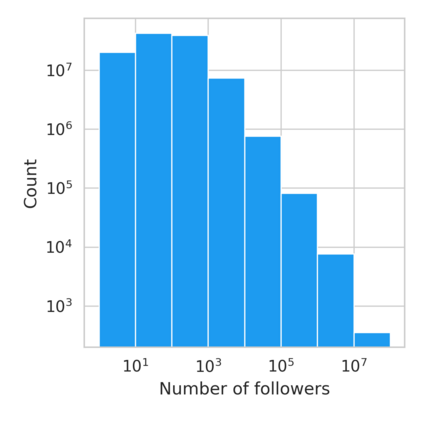
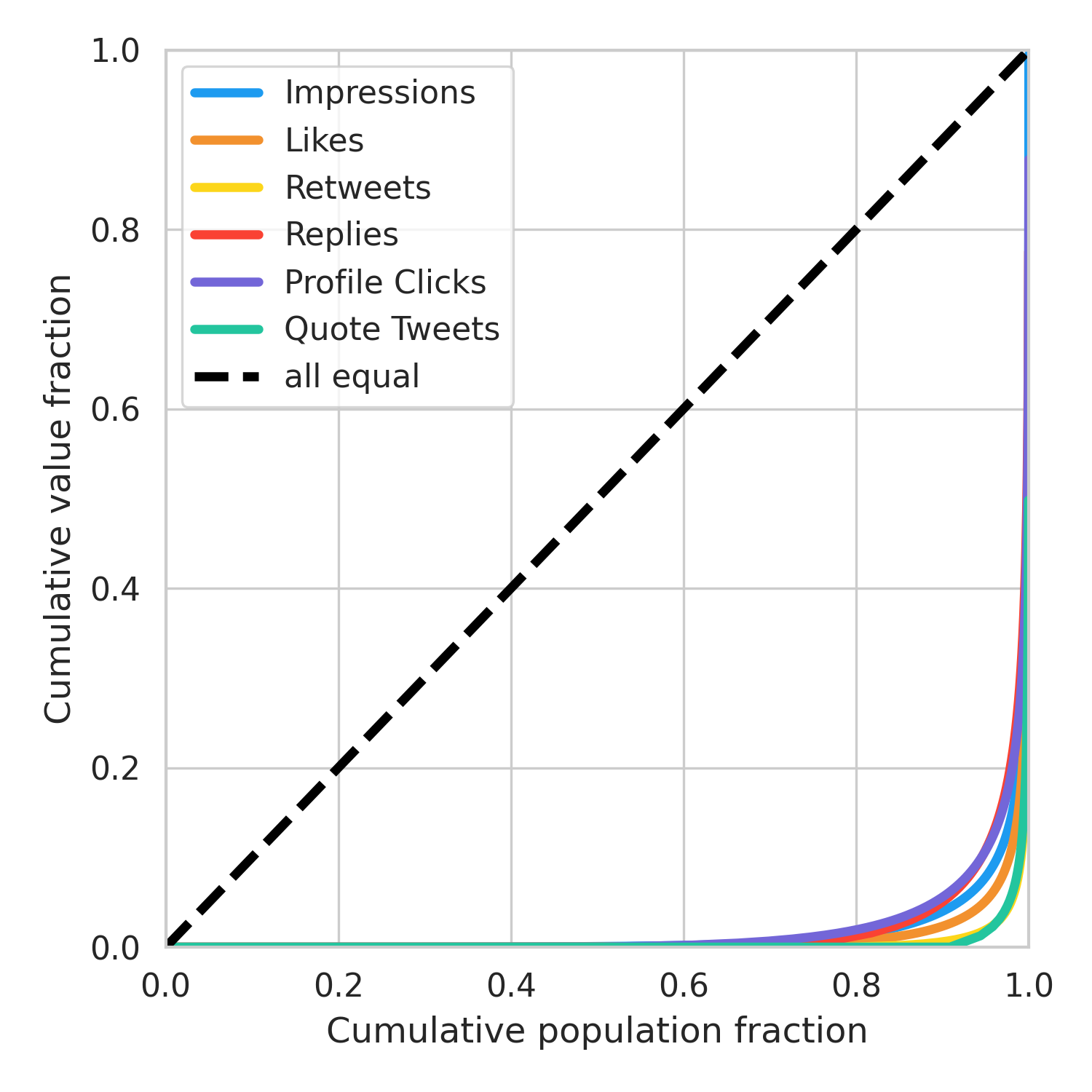
The harmful impacts of algorithmic decision systems have recently come into focus, with many examples of systems such as machine learning (ML) models amplifying existing societal biases. Most metrics attempting to quantify disparities resulting from ML algorithms focus on differences between groups, dividing users based on demographic identities and comparing model performance or overall outcomes between these groups. However, in industry settings, such information is often not available, and inferring these characteristics carries its own risks and biases. Moreover, typical metrics that focus on a single classifier's output ignore the complex network of systems that produce outcomes in real-world settings. In this paper, we evaluate a set of metrics originating from economics, distributional inequality metrics, and their ability to measure disparities in content exposure in a production recommendation system, the Twitter algorithmic timeline. We define desirable criteria for metrics to be used in an operational setting, specifically by ML practitioners. We characterize different types of engagement with content on Twitter using these metrics, and use these results to evaluate the metrics with respect to the desired criteria. We show that we can use these metrics to identify content suggestion algorithms that contribute more strongly to skewed outcomes between users. Overall, we conclude that these metrics can be useful tools for understanding disparate outcomes in online social networks.
翻译:算法决定系统的有害影响最近已引起注意,许多系统的例子,如机器学习(ML)模型等,扩大了现有的社会偏见。大多数试图量化由ML算法产生的差异的衡量标准都侧重于群体之间的差异,根据人口特征区分用户,比较这些群体之间的示范业绩或总体结果。然而,在行业环境中,这类信息往往得不到,推断这些特点本身就具有风险和偏见。此外,侧重于单一分类器输出的典型衡量标准忽视了在现实世界环境中产生结果的系统复杂网络。我们在本文件中评估了一套来自经济学、分布不平等衡量标准及其在生产建议系统(Twitter算法时间表)中衡量内容暴露差异的能力。我们界定了用于业务环境中使用的衡量标准的可取标准,特别是ML从业者。我们用这些衡量标准对在推特上使用内容的不同类型进行了描述,并使用这些结果来评价在现实世界环境中产生结果的衡量标准。我们用这些衡量标准来确定一套内容建议,用以更有力地帮助在生产建议系统(Twitter算法)中理解结果的在线用户之间。我们的结论是,这些衡量结果是不同的指标。