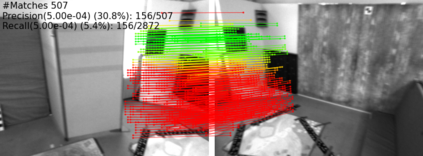
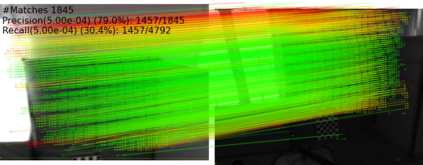
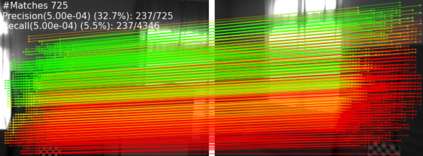
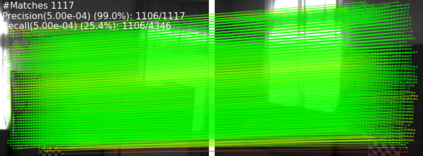
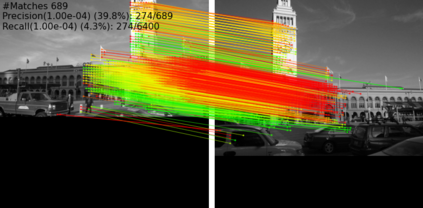
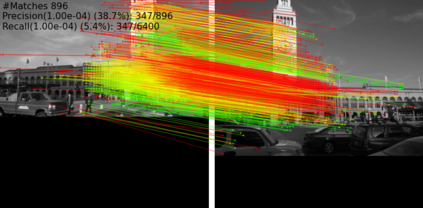
Extracting point correspondences from two or more views of a scene is a fundamental computer vision problem with particular importance for relative camera pose estimation and structure-from-motion. Existing local feature matching approaches, trained with correspondence supervision on large-scale datasets, obtain highly-accurate matches on the test sets. However, they do not generalise well to new datasets with different characteristics to those they were trained on, unlike classic feature extractors. Instead, they require finetuning, which assumes that ground-truth correspondences or ground-truth camera poses and 3D structure are available. We relax this assumption by removing the requirement of 3D structure, e.g., depth maps or point clouds, and only require camera pose information, which can be obtained from odometry. We do so by replacing correspondence losses with epipolar losses, which encourage putative matches to lie on the associated epipolar line. While weaker than correspondence supervision, we observe that this cue is sufficient for finetuning existing models on new data. We then further relax the assumption of known camera poses by using pose estimates in a novel bootstrapping approach. We evaluate on highly challenging datasets, including an indoor drone dataset and an outdoor smartphone camera dataset, and obtain state-of-the-art results without strong supervision.
翻译:暂无翻译