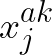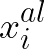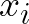Self-supervised learning has emerged as a strategy to reduce the reliance on costly supervised signal by pretraining representations only using unlabeled data. These methods combine heuristic proxy classification tasks with data augmentations and have achieved significant success, but our theoretical understanding of this success remains limited. In this paper we analyze self-supervised representation learning using a causal framework. We show how data augmentations can be more effectively utilized through explicit invariance constraints on the proxy classifiers employed during pretraining. Based on this, we propose a novel self-supervised objective, Representation Learning via Invariant Causal Mechanisms (ReLIC), that enforces invariant prediction of proxy targets across augmentations through an invariance regularizer which yields improved generalization guarantees. Further, using causality we generalize contrastive learning, a particular kind of self-supervised method, and provide an alternative theoretical explanation for the success of these methods. Empirically, ReLIC significantly outperforms competing methods in terms of robustness and out-of-distribution generalization on ImageNet, while also significantly outperforming these methods on Atari achieving above human-level performance on $51$ out of $57$ games.
翻译:自我监督的学习已成为一项战略,旨在减少对培训前代表机构依赖费用昂贵的监管信号的依赖,仅使用未贴标签的数据。这些方法将超常代用代用分类任务与数据扩增相结合,并取得了显著的成功,但我们对这一成功的理论理解仍然有限。在本文件中,我们利用因果框架分析自监管代用代用学习。我们展示了如何通过在培训前使用的代用分类机构明显存在差异来更有效地利用数据扩增。在此基础上,我们提出了一个新的自我监督目标,即通过Invariant Causal机制(ReLIC)进行代用代用代用代用方法,即通过可改进通用保证的惯用惯用代用代用方法对代用目标进行不动预测。此外,我们利用因果性来分析自监管的代用代用方法,特别是一种自我监督的方法,为这些方法的成功提供替代的理论解释。基于此,ReLIC在图像网的稳健性和分配外通用化方面大大超越了相互竞争的方法,同时也大大超过Atarilegy on Atariefore agotial ex exment on 557Alien ention。