
题目: Self-Supervised Learning of Video-Induced Visual Invariances
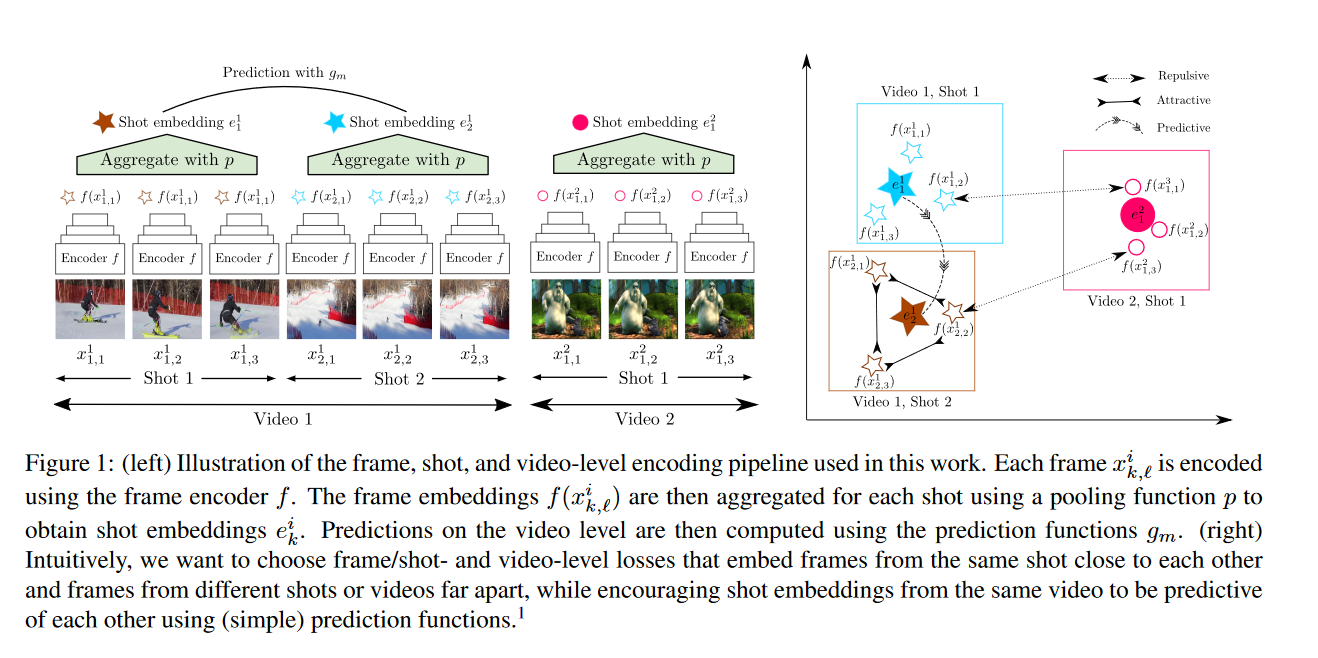
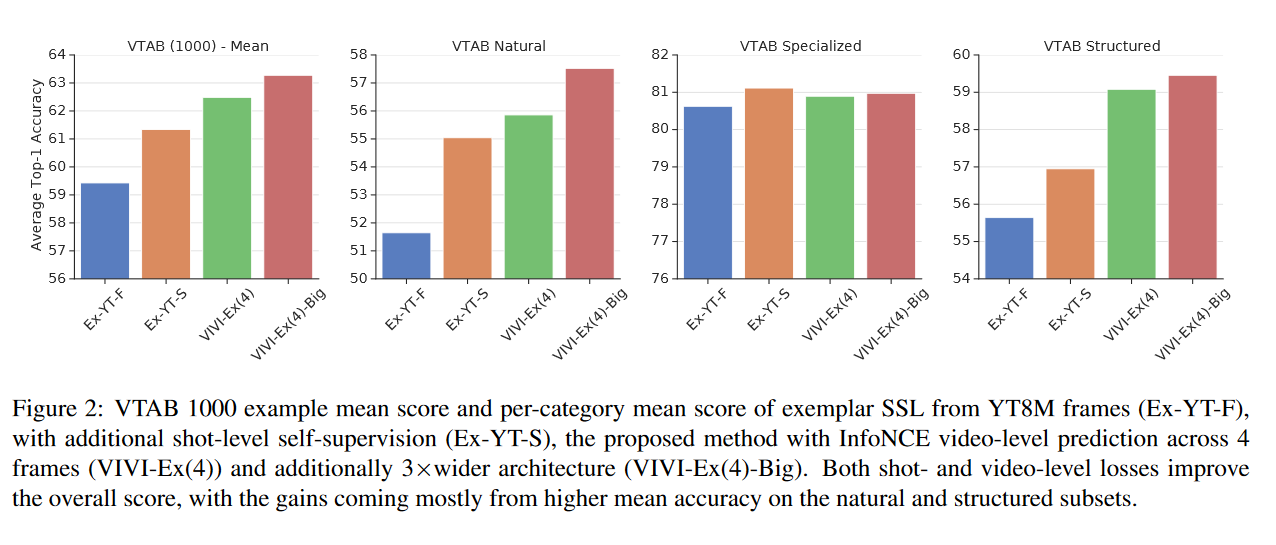
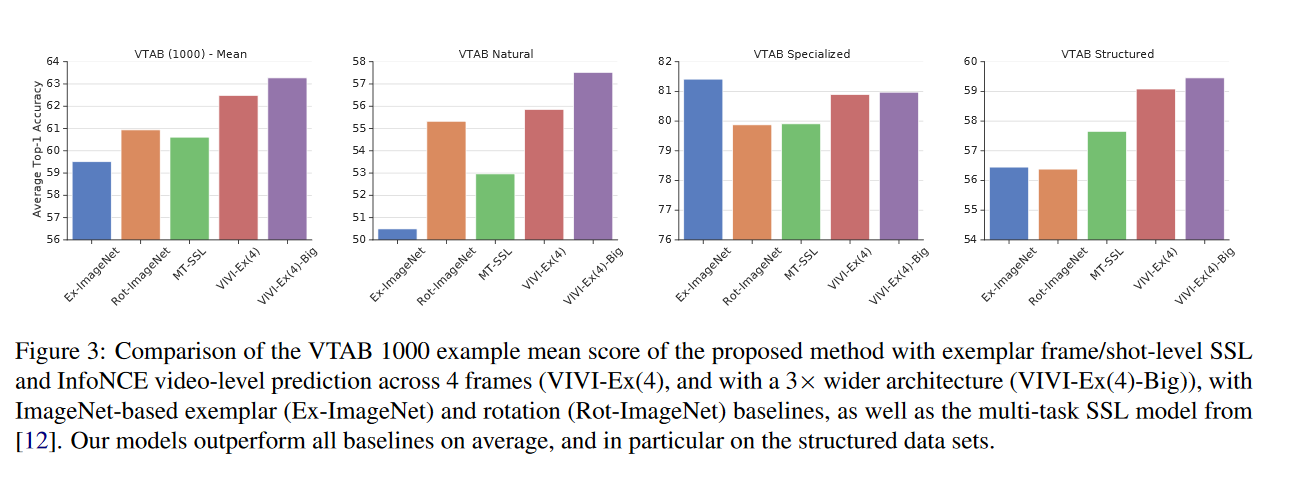
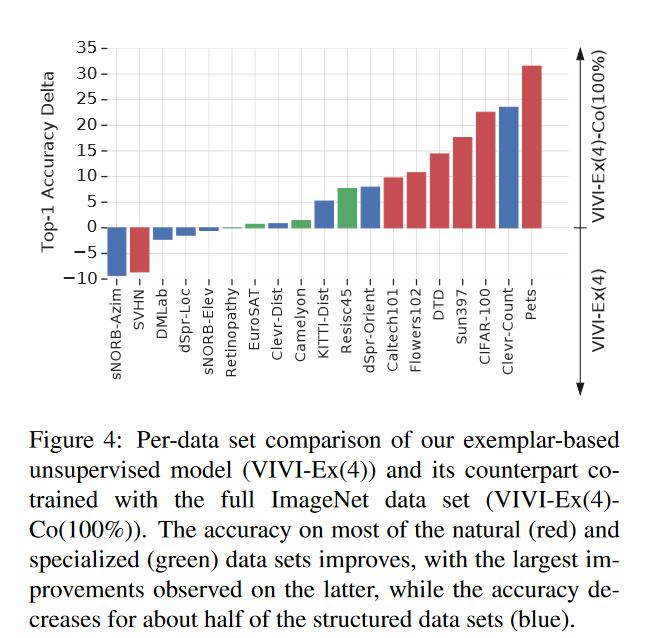
摘要: 我们提出了一种基于视频诱导视觉不变性(VIVI)的可转移视觉表示自监督学习的一般框架。我们考虑视频中存在的嵌入层次,并利用(i)帧级不变性(例如对颜色和对比度扰动的稳定性),(ii)镜头/剪辑级不变性(例如对对象方向和照明条件的变化的鲁棒性),以及(iii)视频级不变性(镜头/剪辑之间场景的语义关系),以定义整体的自监督损失。使用YouTube-8M(YT8M)数据集视频框架的不同变体的训练模型,我们在视觉任务适应基准(VTAB)的19个不同下游任务上获得最先进的自我监督传输学习结果,每个任务仅使用1000个标签。然后,我们展示如何与标记图像联合训练模型,在标记图像减少10倍的情况下,比anImageNet pretrained ResNet-50多0.8个点,以及使用完整ImageNet数据集的前一个最佳super-vised模型多3.7个点。
作者简介: Michael Tschannen,谷歌博士后研究员,对机器学习和计算机视觉很感兴趣。
成为VIP会员查看完整内容
相关内容

人工智能(Artificial Intelligence, AI )是研究、开发用于模拟、延伸和扩展人的智能的理论、方法、技术及应用系统的一门新的技术科学。 人工智能是计算机科学的一个分支。
专知会员服务
25+阅读 · 2020年7月1日
Arxiv
4+阅读 · 2017年10月26日
相关主题




相关VIP内容
专知会员服务
25+阅读 · 2020年7月1日
相关资讯
相关论文
Arxiv
4+阅读 · 2017年10月26日