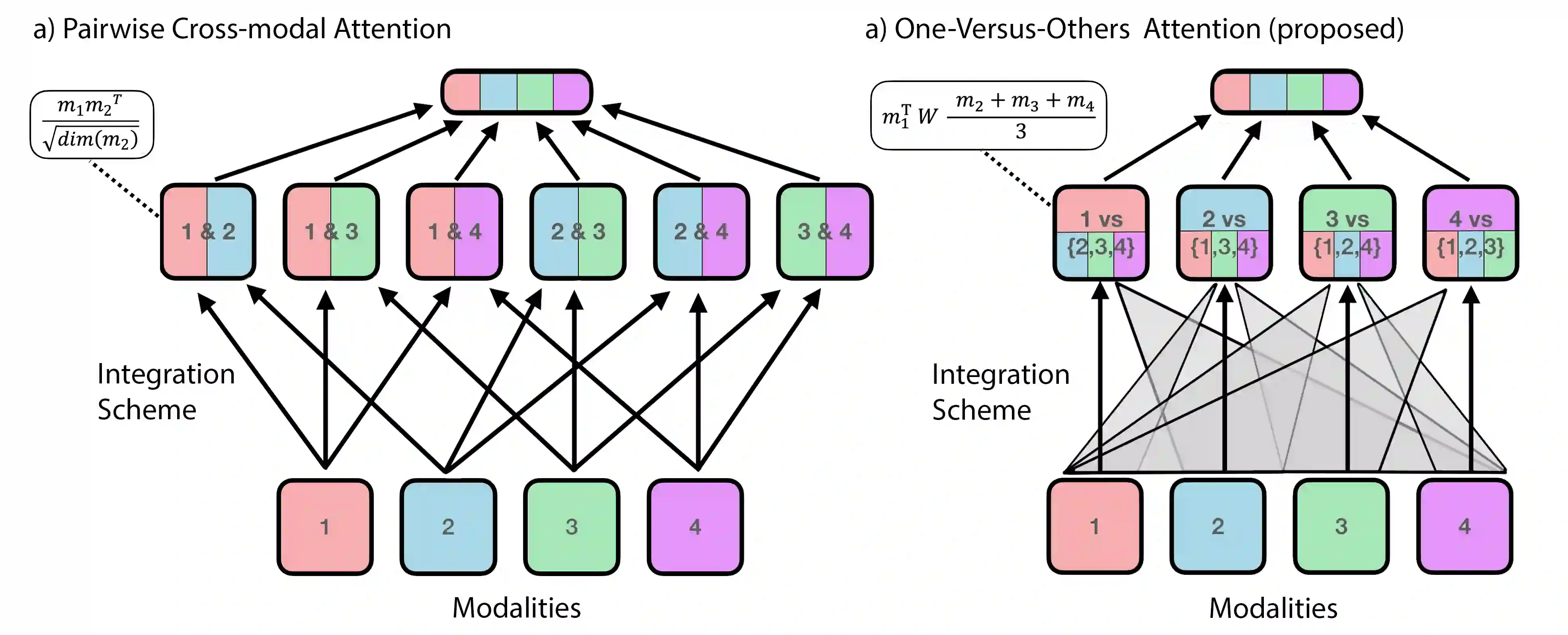
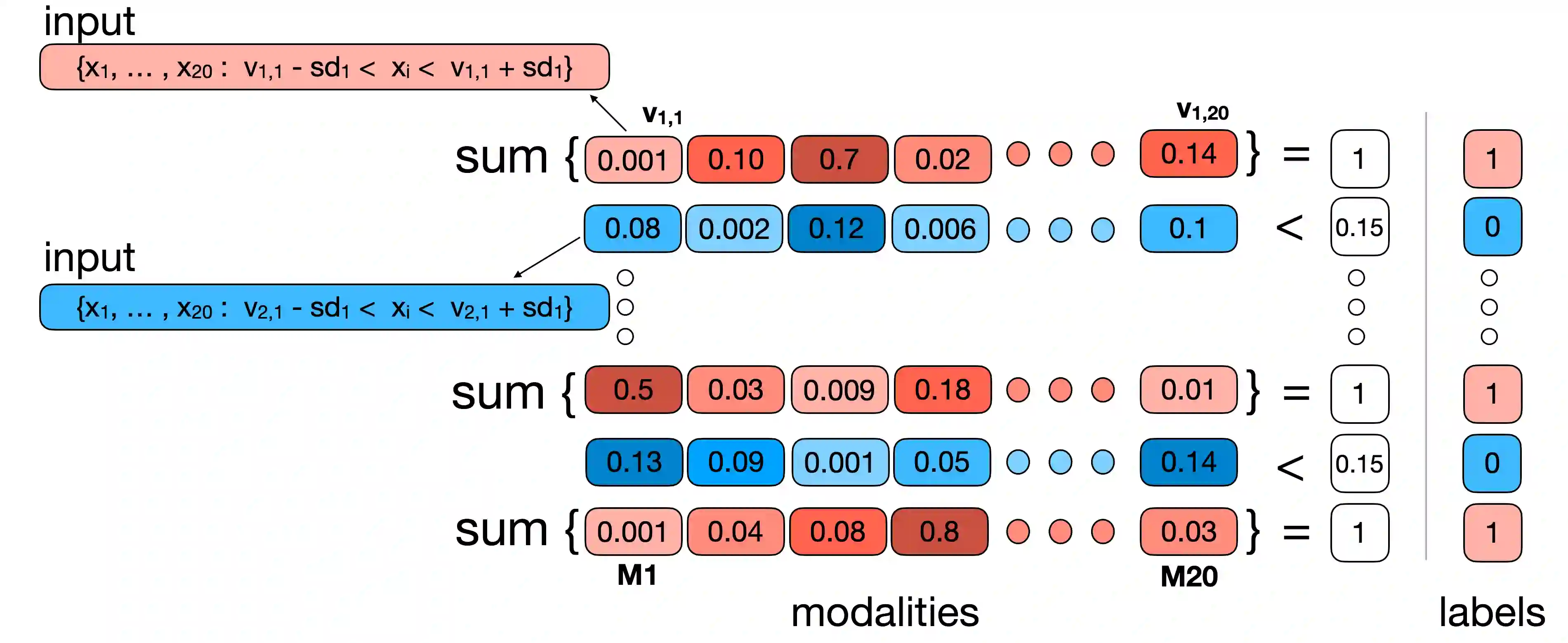
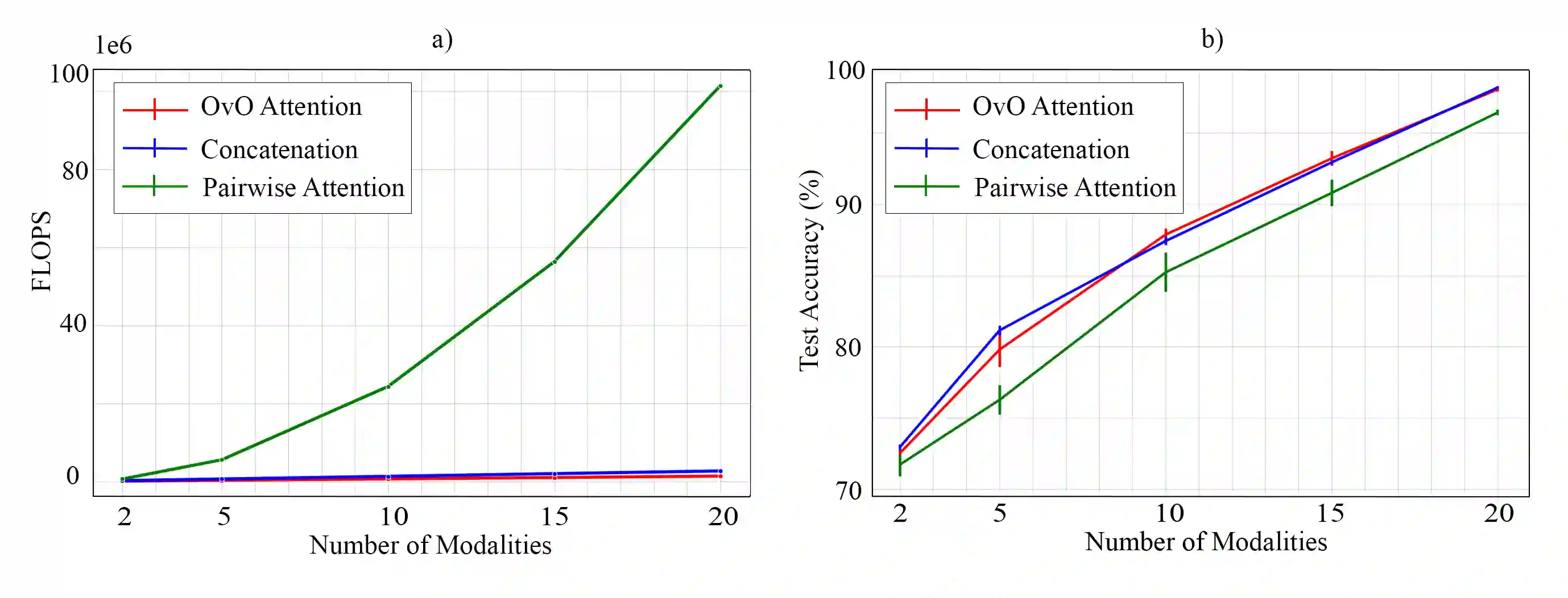
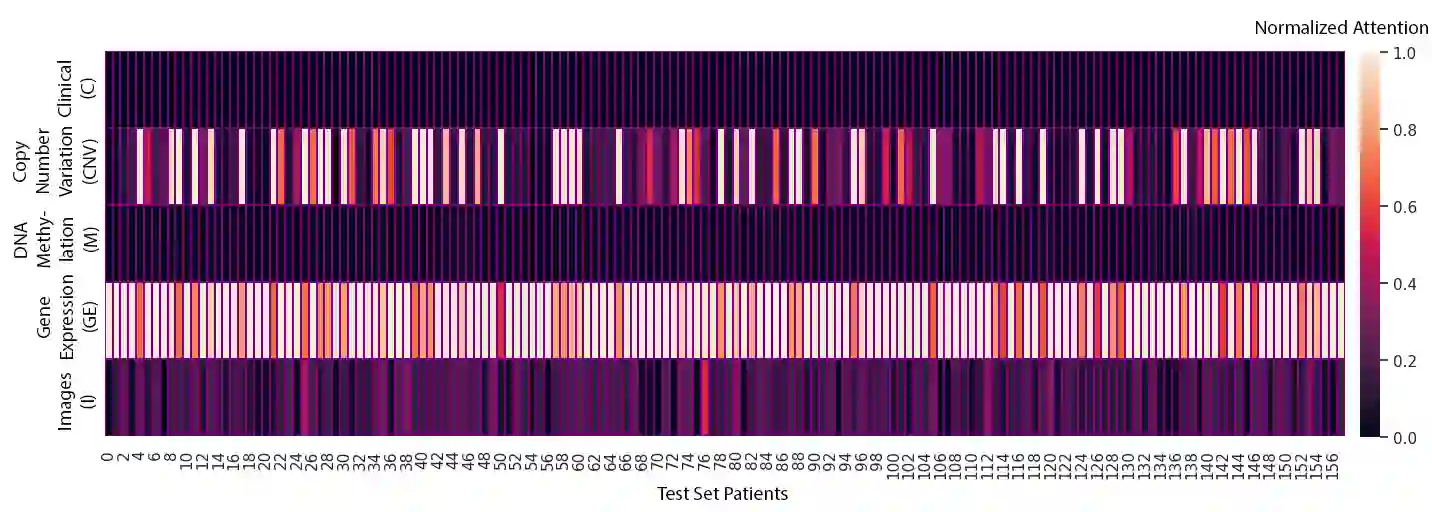
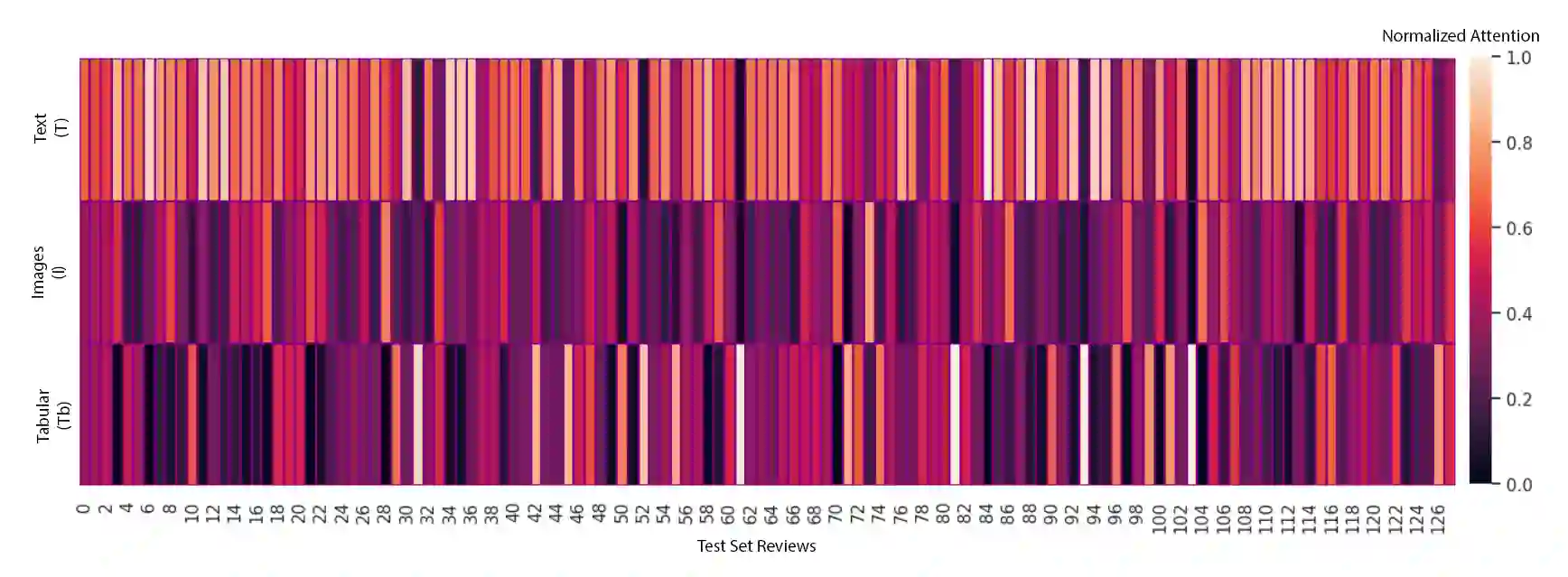
Multimodal learning models have become increasingly important as they surpass single-modality approaches on diverse tasks ranging from question-answering to autonomous driving. Despite the importance of multimodal learning, existing efforts focus on NLP applications, where the number of modalities is typically less than four (audio, video, text, images). However, data inputs in other domains, such as the medical field, may include X-rays, PET scans, MRIs, genetic screening, clinical notes, and more, creating a need for both efficient and accurate information fusion. Many state-of-the-art models rely on pairwise cross-modal attention, which does not scale well for applications with more than three modalities. For $n$ modalities, computing attention will result in $n \choose 2$ operations, potentially requiring considerable amounts of computational resources. To address this, we propose a new domain-neutral attention mechanism, One-Versus-Others (OvO) attention, that scales linearly with the number of modalities and requires only $n$ attention operations, thus offering a significant reduction in computational complexity compared to existing cross-modal attention algorithms. Using three diverse real-world datasets as well as an additional simulation experiment, we show that our method improves performance compared to popular fusion techniques while decreasing computation costs.
翻译:暂无翻译