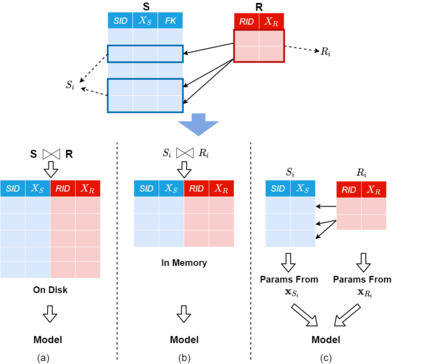
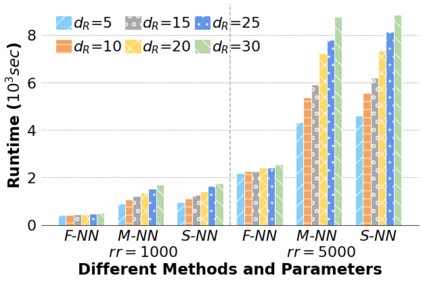
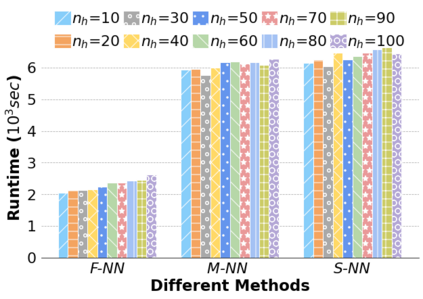
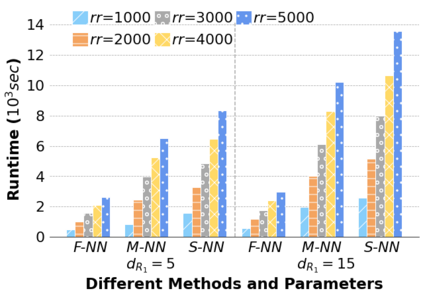
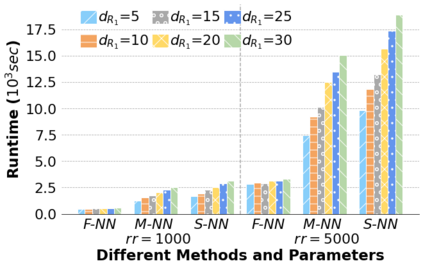
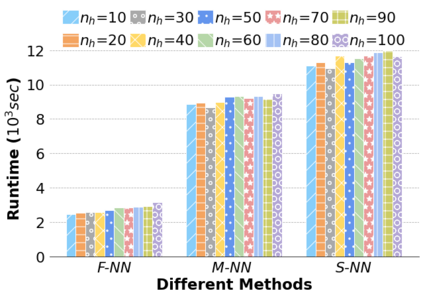
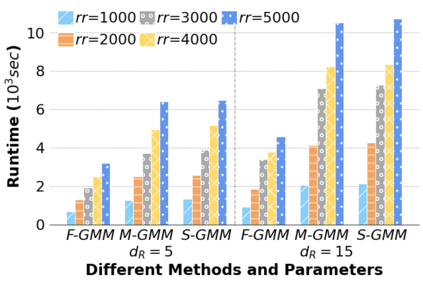
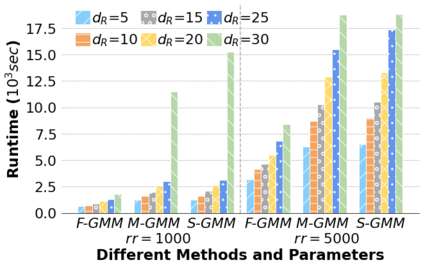
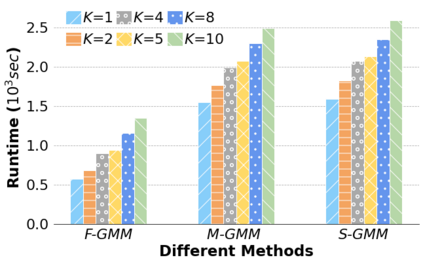
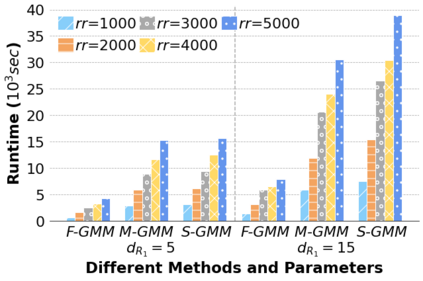
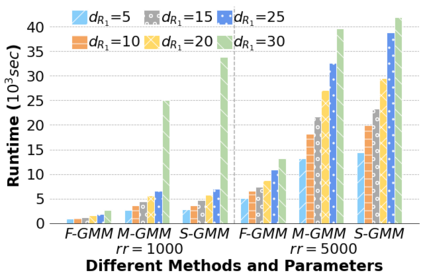
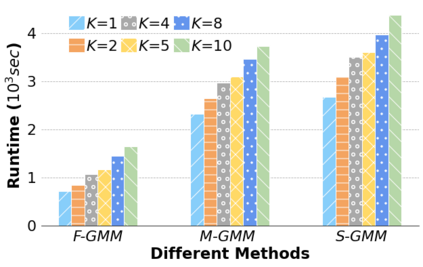
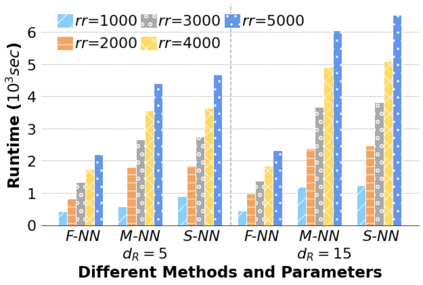
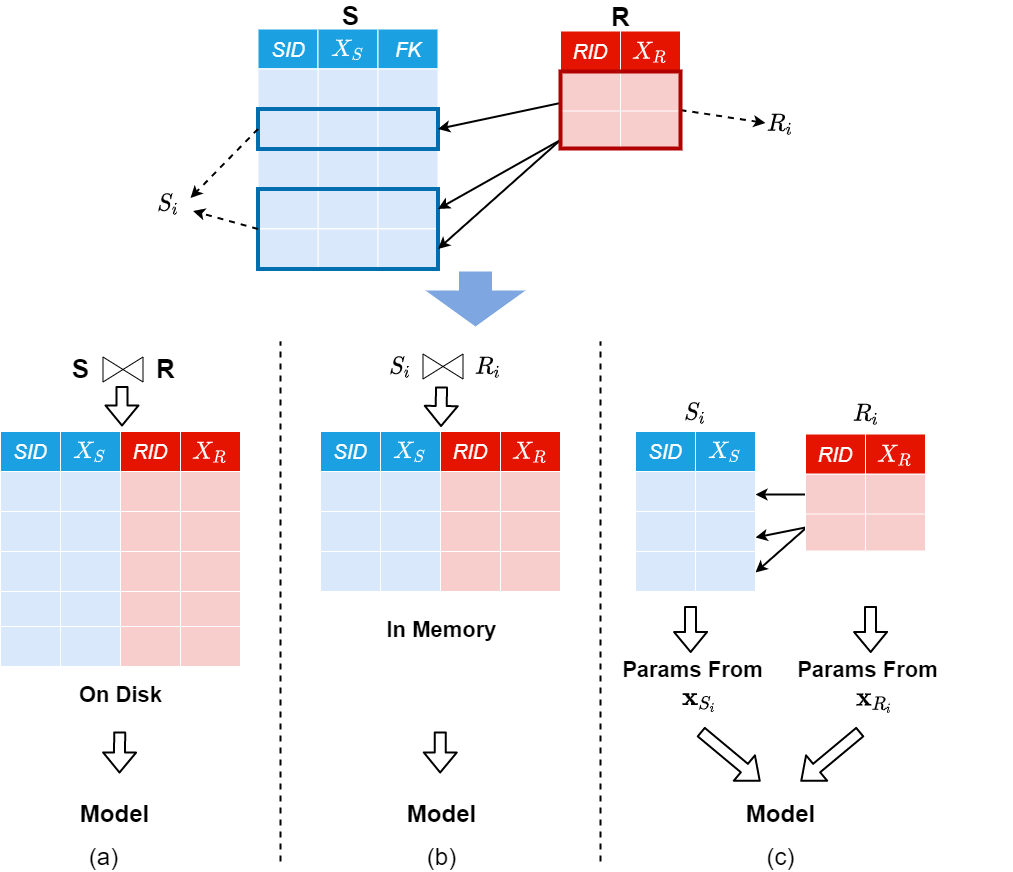
Machine Learning (ML) applications are proliferating in the enterprise. Relational data which are prevalent in enterprise applications are typically normalized; as a result, data has to be denormalized via primary/foreign-key joins to be provided as input to ML algorithms. In this paper, we study the implementation of popular nonlinear ML models, Gaussian Mixture Models (GMM) and Neural Networks (NN), over normalized data addressing both cases of binary and multi-way joins over normalized relations. For the case of GMM, we show how it is possible to decompose computation in a systematic way both for binary joins and for multi-way joins to construct mixture models. We demonstrate that by factoring the computation, one can conduct the training of the models much faster compared to other applicable approaches, without any loss in accuracy. For the case of NN, we propose algorithms to train the network taking normalized data as the input. Similarly, we present algorithms that can conduct the training of the network in a factorized way and offer performance advantages. The redundancy introduced by denormalization can be exploited for certain types of activation functions. However, we demonstrate that attempting to explore this redundancy is helpful up to a certain point; exploring redundancy at higher layers of the network will always result in increased costs and is not recommended. We present the results of a thorough experimental evaluation, varying several parameters of the input relations involved and demonstrate that our proposals for the training of GMM and NN yield drastic performance improvements typically starting at 100%, which become increasingly higher as parameters of the underlying data vary, without any loss in accuracy.
翻译:在企业中, 机器学习( ML) 应用程序正在扩散。 企业应用程序中普遍存在的通胀数据通常会正常化; 因此, 数据必须通过初级/ 外国键连接进行非正常化, 作为对 ML 算法的输入。 在本文中, 我们研究流行的非线性 ML 模型、 Gossian Mixture 模型( GMMM) 和神经网络( NN) 的采用, 超过标准化数据, 涉及二进制和多路连接, 而不是正常关系。 对于 GMM 来说, 我们展示了如何系统化地解析计算, 既用于二进制参数, 也用于多进制混合模型。 我们证明, 通过计算计算, 能够比其他适用的方法更快地对模型进行培训, 高三进制模型( GMM) 和神经网络(NNNN) 。 我们建议, 算算算法, 用来以因素化方式对网络进行培训, 并且提供性能优势的更高化计算。 通过计算, 递增的精度的精度, 我们的精度分析, 不断的网络的精度的精度分析, 的精度 将结果会显示, 的精度的精度的精度 。