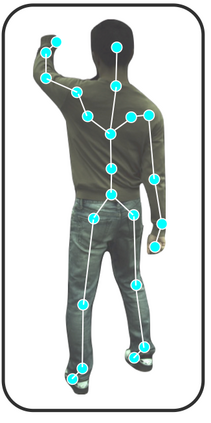
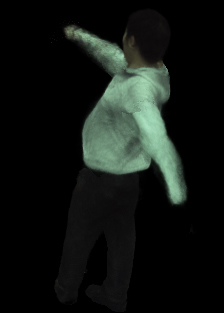This paper introduces Motion-oriented Compositional Neural Radiance Fields (MoCo-NeRF), a framework designed to perform free-viewpoint rendering of monocular human videos via novel non-rigid motion modeling approach. In the context of dynamic clothed humans, complex cloth dynamics generate non-rigid motions that are intrinsically distinct from skeletal articulations and critically important for the rendering quality. The conventional approach models non-rigid motions as spatial (3D) deviations in addition to skeletal transformations. However, it is either time-consuming or challenging to achieve optimal quality due to its high learning complexity without a direct supervision. To target this problem, we propose a novel approach of modeling non-rigid motions as radiance residual fields to benefit from more direct color supervision in the rendering and utilize the rigid radiance fields as a prior to reduce the complexity of the learning process. Our approach utilizes a single multiresolution hash encoding (MHE) to concurrently learn the canonical T-pose representation from rigid skeletal motions and the radiance residual field for non-rigid motions. Additionally, to further improve both training efficiency and usability, we extend MoCo-NeRF to support simultaneous training of multiple subjects within a single framework, thanks to our effective design for modeling non-rigid motions. This scalability is achieved through the integration of a global MHE and learnable identity codes in addition to multiple local MHEs. We present extensive results on ZJU-MoCap and MonoCap, clearly demonstrating state-of-the-art performance in both single- and multi-subject settings. The code and model will be made publicly available at the project page: https://stevejaehyeok.github.io/publications/moco-nerf.
翻译:暂无翻译