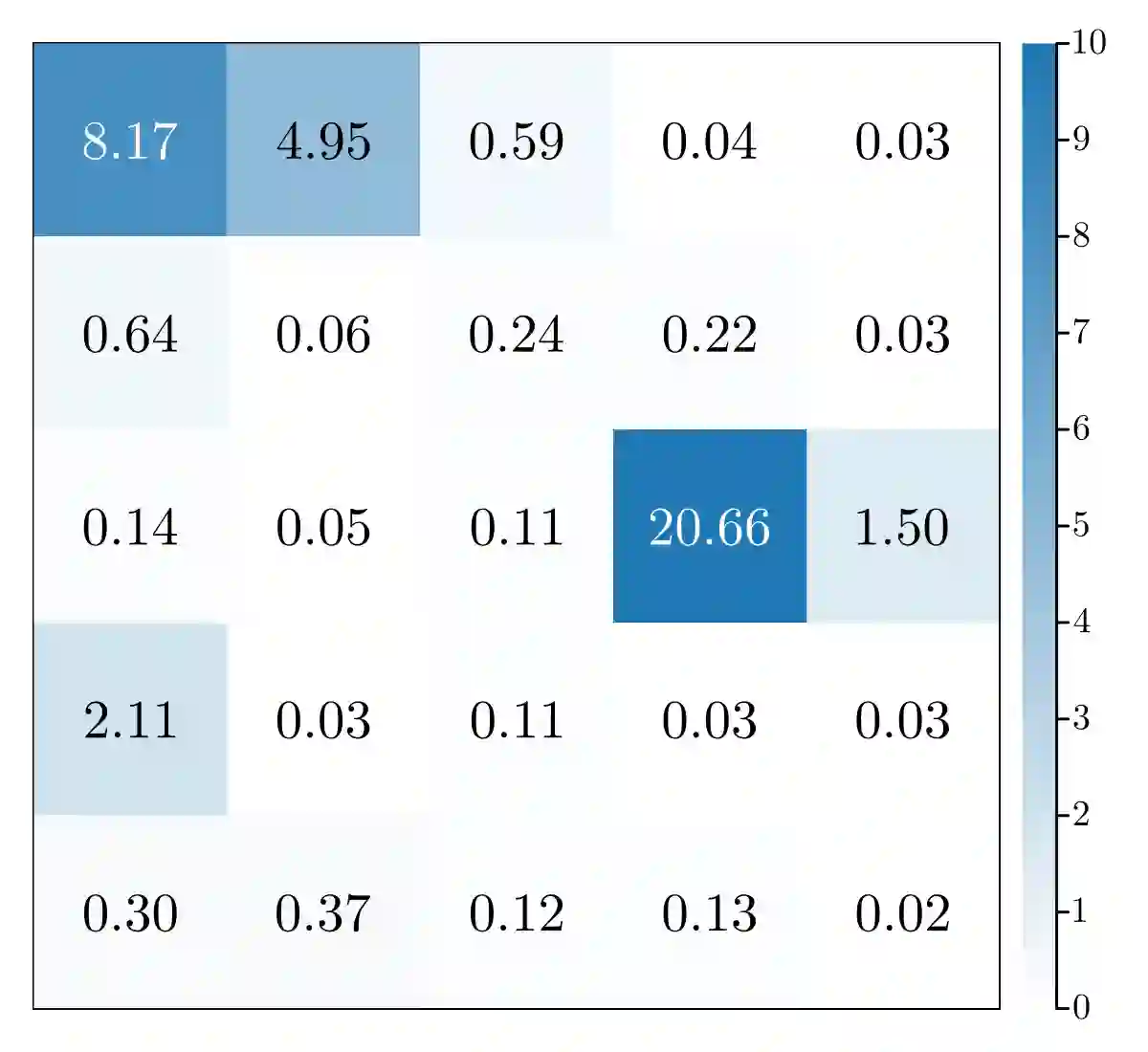
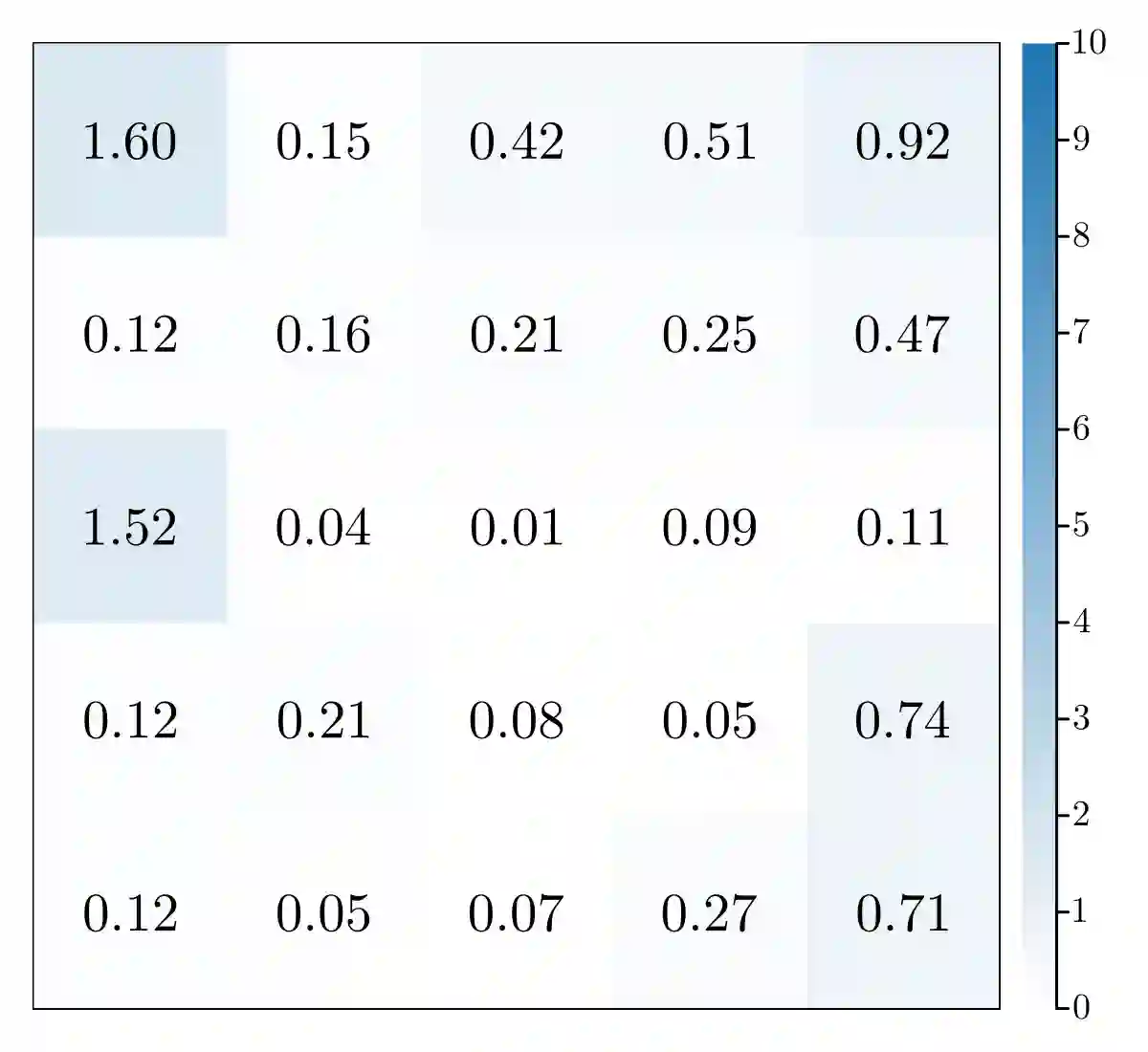
Markov games model interactions among multiple players in a stochastic, dynamic environment. Each player in a Markov game maximizes its expected total discounted reward, which depends upon the policies of the other players. We formulate a class of Markov games, termed affine Markov games, where an affine reward function couples the players' actions. We introduce a novel solution concept, the soft-Bellman equilibrium, where each player is boundedly rational and chooses a soft-Bellman policy rather than a purely rational policy as in the well-known Nash equilibrium concept. We provide conditions for the existence and uniqueness of the soft-Bellman equilibrium and propose a nonlinear least-squares algorithm to compute such an equilibrium in the forward problem. We then solve the inverse game problem of inferring the players' reward parameters from observed state-action trajectories via a projected-gradient algorithm. Experiments in a predator-prey OpenAI Gym environment show that the reward parameters inferred by the proposed algorithm outperform those inferred by a baseline algorithm: they reduce the Kullback-Leibler divergence between the equilibrium policies and observed policies by at least two orders of magnitude.
翻译:暂无翻译