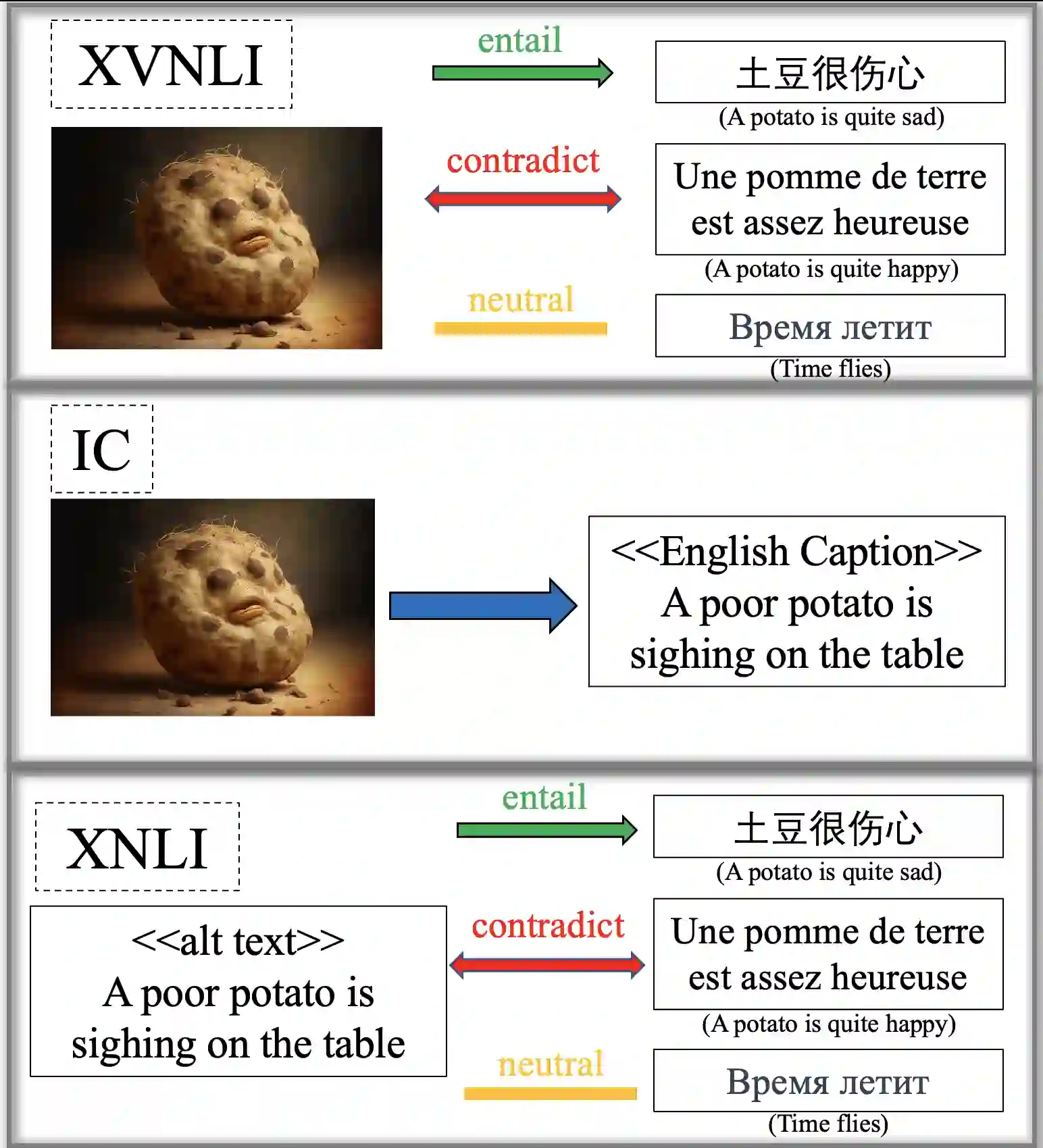
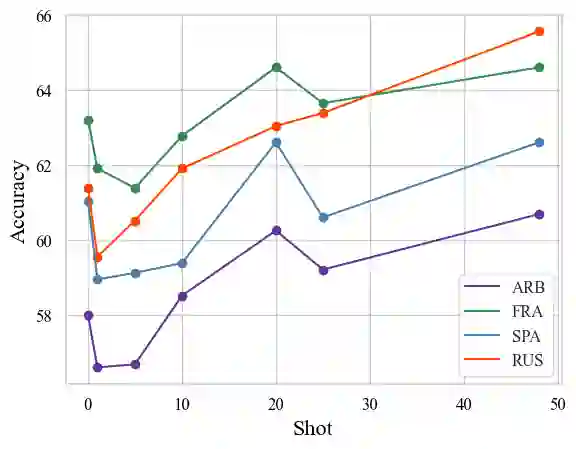
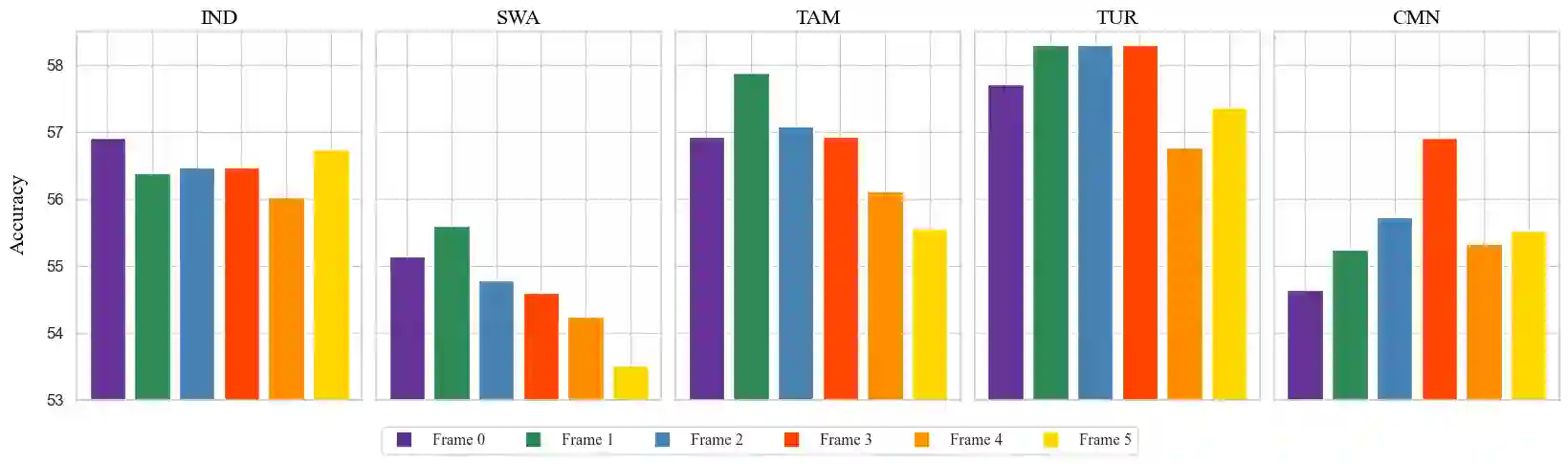
Most multilingual vision-and-language (V&L) research aims to accomplish multilingual and multimodal capabilities within one model. However, the scarcity of multilingual captions for images has hindered the development. To overcome this obstacle, we propose ICU, Image Caption Understanding, which divides a V&L task into two stages: a V&L model performs image captioning in English, and a multilingual language model (mLM), in turn, takes the caption as the alt text and performs crosslingual language understanding. The burden of multilingual processing is lifted off V&L model and placed on mLM. Since the multilingual text data is relatively of higher abundance and quality, ICU can facilitate the conquering of language barriers for V&L models. In experiments on two tasks across 9 languages in the IGLUE benchmark, we show that ICU can achieve new state-of-the-art results for five languages, and comparable results for the rest.
翻译:暂无翻译