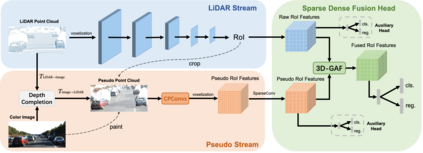
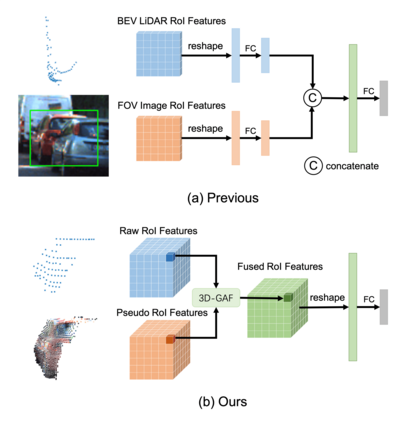
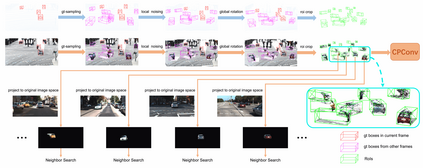
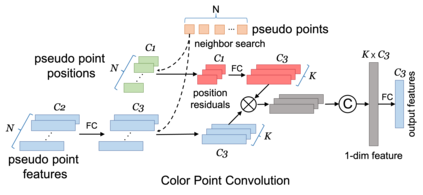
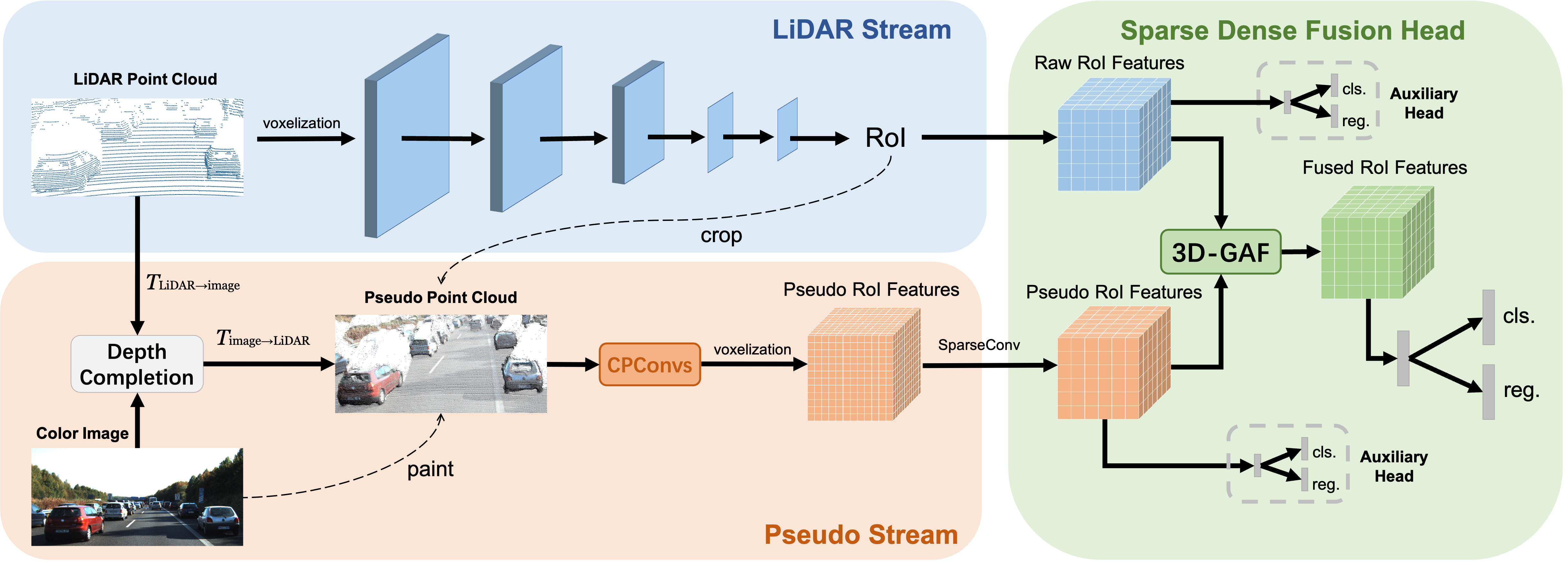
Current LiDAR-only 3D detection methods inevitably suffer from the sparsity of point clouds. Many multi-modal methods are proposed to alleviate this issue, while different representations of images and point clouds make it difficult to fuse them, resulting in suboptimal performance. In this paper, we present a novel multi-modal framework SFD (Sparse Fuse Dense), which utilizes pseudo point clouds generated from depth completion to tackle the issues mentioned above. Different from prior works, we propose a new RoI fusion strategy 3D-GAF (3D Grid-wise Attentive Fusion) to make fuller use of information from different types of point clouds. Specifically, 3D-GAF fuses 3D RoI features from the couple of point clouds in a grid-wise attentive way, which is more fine-grained and more precise. In addition, we propose a SynAugment (Synchronized Augmentation) to enable our multi-modal framework to utilize all data augmentation approaches tailored to LiDAR-only methods. Lastly, we customize an effective and efficient feature extractor CPConv (Color Point Convolution) for pseudo point clouds. It can explore 2D image features and 3D geometric features of pseudo point clouds simultaneously. Our method holds the highest entry on the KITTI car 3D object detection leaderboard, demonstrating the effectiveness of our SFD. Codes are available at https://github.com/LittlePey/SFD.
翻译:目前只有三维天体的激光雷达探测方法不可避免地会受到点云宽度的影响。 许多多式方法都提议缓解这一问题, 而不同图像和点云的不同表达方式使得难以将图像和点云合为一体, 从而导致不理想的性能。 在本文中, 我们提出了一个全新的多式框架 SFD (Sparse Fuse Dense), 它使用从深度完成产生的假的点云来解决上述问题。 不同于先前的工程, 我们提议了一个新的 RoI 融合战略 3D- GAF (3D Grid- Wid- attention Fution ), 以更充分地利用不同类型的点云层云层云层云层云层的信息。 最后, 我们将三维的地貌提取点的 CP Condion( Colorpoint Contraction ) 的三维功能从两端云层云层云层云层云层云层云层云层云层云层的两端连接, 并且将我们现有的Slodal 3L 级云层图层图层图解解。