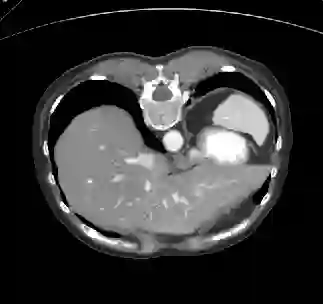
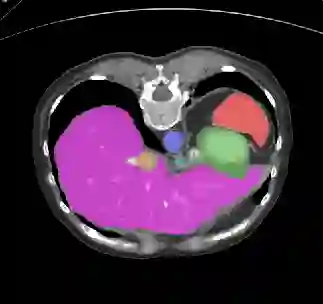
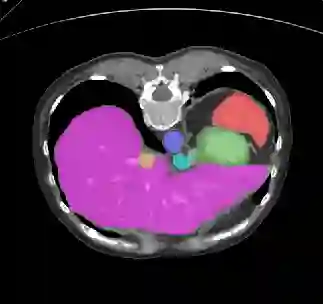
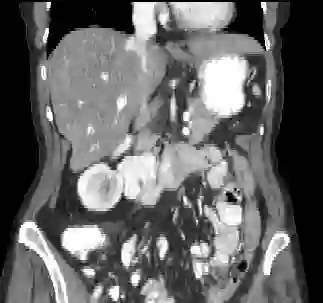
Recently, deep learning methods have achieved state-of-the-art performance in many medical image segmentation tasks. Many of these are based on convolutional neural networks (CNNs). For such methods, the encoder is the key part for global and local information extraction from input images; the extracted features are then passed to the decoder for predicting the segmentations. In contrast, several recent works show a superior performance with the use of transformers, which can better model long-range spatial dependencies and capture low-level details. However, transformer as sole encoder underperforms for some tasks where it cannot efficiently replace the convolution based encoder. In this paper, we propose a model with double encoders for 3D biomedical image segmentation. Our model is a U-shaped CNN augmented with an independent transformer encoder. We fuse the information from the convolutional encoder and the transformer, and pass it to the decoder to obtain the results. We evaluate our methods on three public datasets from three different challenges: BTCV, MoDA and Decathlon. Compared to the state-of-the-art models with and without transformers on each task, our proposed method obtains higher Dice scores across the board.
翻译:最近,深层学习方法在许多医学图像分割任务中取得了最先进的性能,其中许多是建立在进化神经网络(CNNs)基础上的。对于这种方法,编码器是从输入图像中提取全球和地方信息的关键部分;提取的特征随后传递到解码器,以预测分解。相比之下,最近的一些工程显示,利用变压器,使用变压器可以更好地模拟长距离空间依赖并捕捉低级细节,其性能优异。然而,变压器作为唯一编码器,在无法有效取代以进化为基础的编码器的一些任务中,其变压器处于不完善状态。在本文中,我们为3D生物医学图像分割提出了一个配有双重编码器的模型。我们的模型是U型CNN,配有独立的变压器编码器。我们将来自变压器和变压器的信息结合到解调器,以获得结果。我们从三种不同挑战中评估了我们三种公共数据集的方法:BTCV、MoDA和Decathlon。我们建议了一个模型,而每个变压了我们的变压器,而没有了一个州制。