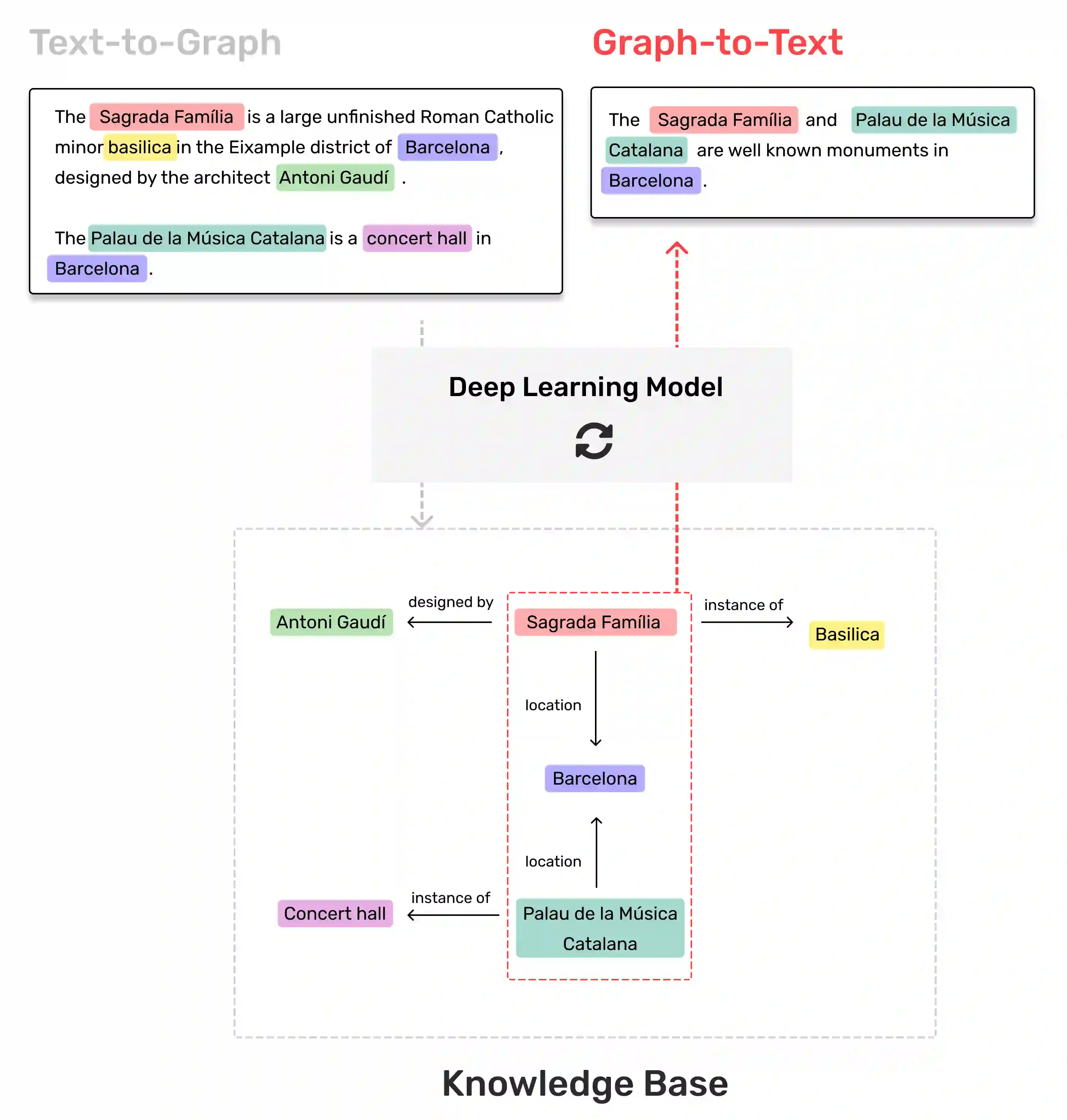
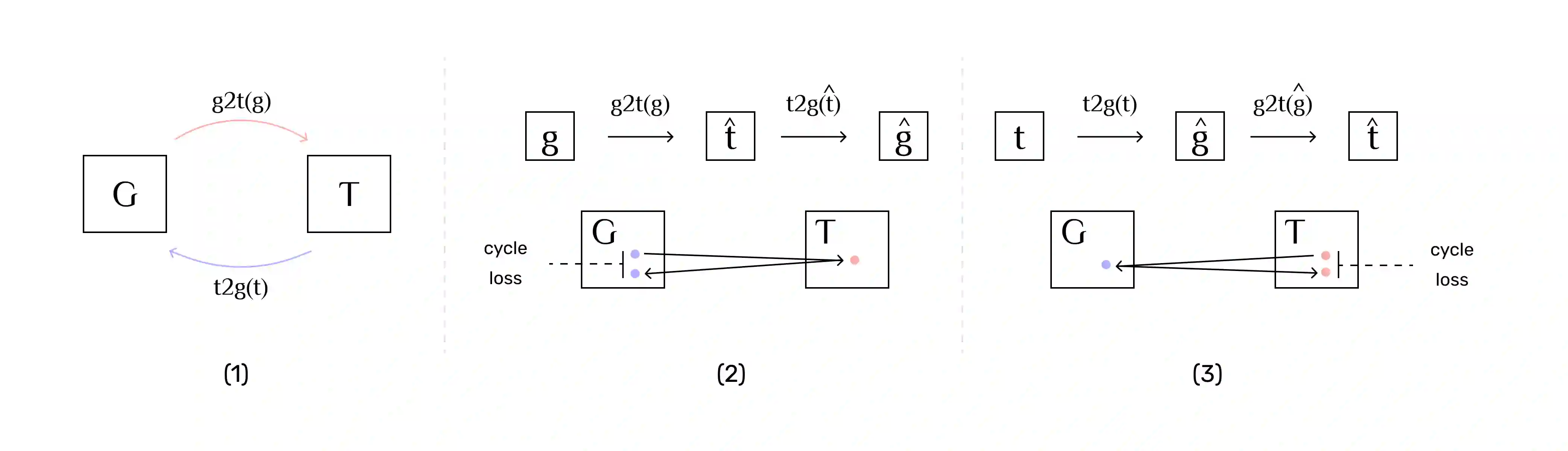
The Artificial Intelligence industry regularly develops applications that mostly rely on Knowledge Bases, a data repository about specific, or general, domains, usually represented in a graph shape. Similar to other databases, they face two main challenges: information ingestion and information retrieval. We approach these challenges by jointly learning graph extraction from text and text generation from graphs. The proposed solution, a T5 architecture, is trained in a multi-task semi-supervised environment, with our collected non-parallel data, following a cycle training regime. Experiments on WebNLG dataset show that our approach surpasses unsupervised state-of-the-art results in text-to-graph and graph-to-text. More relevantly, our framework is more consistent across seen and unseen domains than supervised models. The resulting model can be easily trained in any new domain with non-parallel data, by simply adding text and graphs about it, in our cycle framework.
翻译:人造情报产业定期开发主要依赖知识库的应用,即通常以图表形式呈现的具体或一般领域的数据储存库。与其他数据库一样,它们面临两大挑战:信息摄入和信息检索。我们共同从文本和图表生成的文本中学习图形提取和文本生成,以应对这些挑战。拟议中的解决方案T5结构在多任务半监督环境中得到培训,按照循环培训制度,我们收集的非平行数据。WebNLG数据集的实验显示,我们的方法超过了文本到图表到文本的未经监督的最新结果。更为相关的是,我们的框架比监督的模式更加一致,在可见和看不见的领域比监督的模式更加一致。 由此产生的模型很容易在任何新领域用非平行数据进行培训,简单地在我们的周期框架中添加关于它的案文和图表。