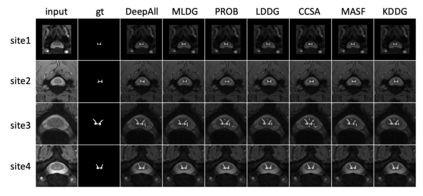
Though convolutional neural networks are widely used in different tasks, lack of generalization capability in the absence of sufficient and representative data is one of the challenges that hinder their practical application. In this paper, we propose a simple, effective, and plug-and-play training strategy named Knowledge Distillation for Domain Generalization (KDDG) which is built upon a knowledge distillation framework with the gradient filter as a novel regularization term. We find that both the ``richer dark knowledge" from the teacher network, as well as the gradient filter we proposed, can reduce the difficulty of learning the mapping which further improves the generalization ability of the model. We also conduct experiments extensively to show that our framework can significantly improve the generalization capability of deep neural networks in different tasks including image classification, segmentation, reinforcement learning by comparing our method with existing state-of-the-art domain generalization techniques. Last but not the least, we propose to adopt two metrics to analyze our proposed method in order to better understand how our proposed method benefits the generalization capability of deep neural networks.
翻译:虽然在不同的任务中广泛使用进化神经网络,但缺乏足够和有代表性的数据,缺乏普遍化能力是阻碍其实际应用的挑战之一。在本文中,我们提出一个简单、有效、插插插式培训战略,名为“通用域知识蒸馏”(KDDG),该战略以知识蒸馏框架为基础,以梯度过滤器为新颖的正规化术语。我们发现,教师网络的“更丰富的黑暗知识”以及我们提议的梯度过滤器,都能够减少学习绘图的困难,从而进一步提高模型的普及能力。我们还进行了广泛的实验,以表明我们的框架可以大大改善不同任务中深层神经网络的普及能力,包括图像分类、分解、通过将我们的方法与现有最新水平域通用技术进行比较而加强学习。最后但并非最不重要的一点,我们提议采用两种衡量尺度来分析我们提出的方法,以便更好地了解我们提出的方法如何有利于深层神经网络的普及能力。