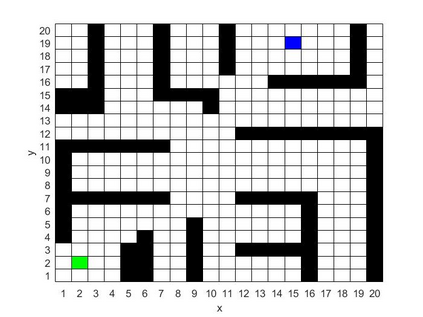
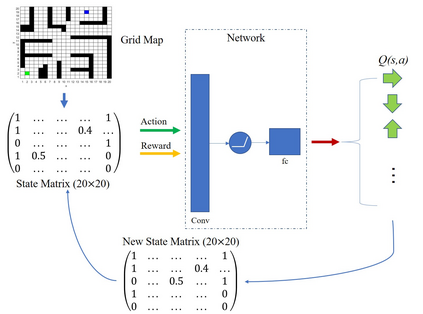
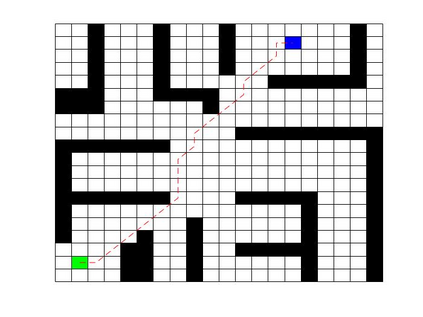
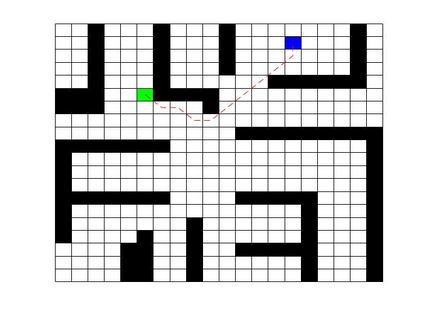
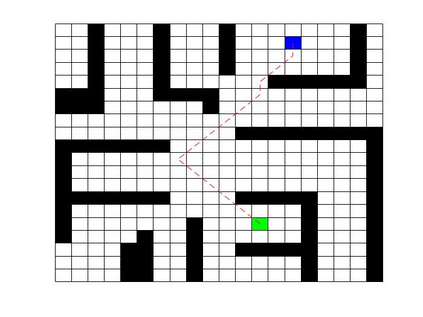
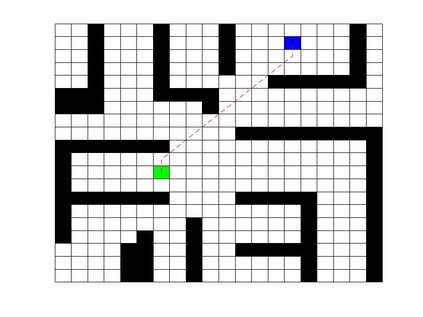
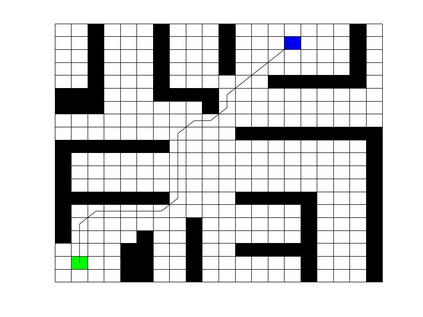
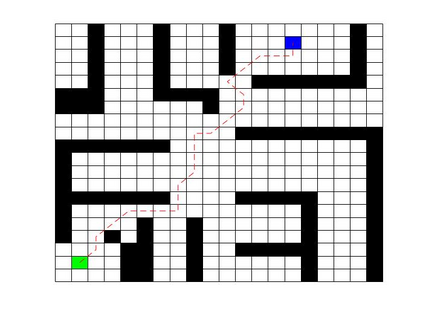
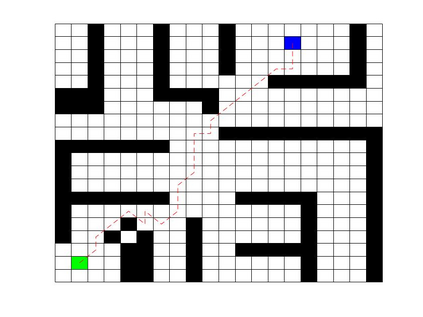
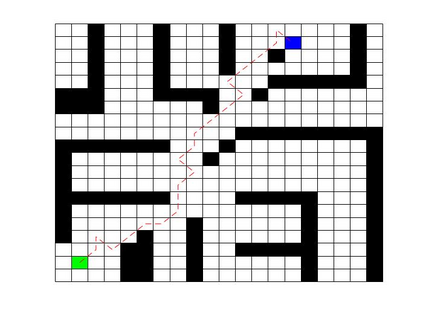
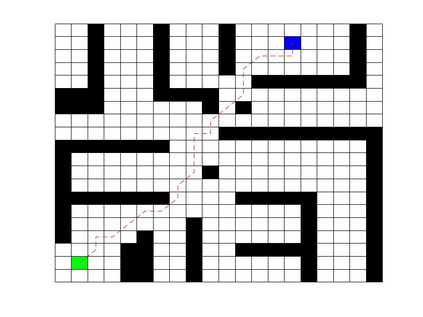
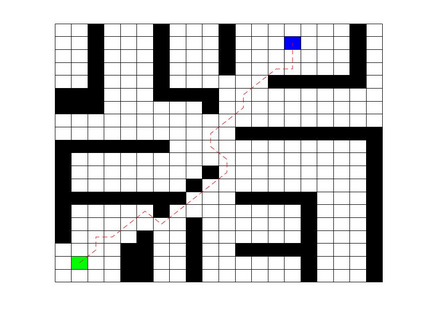
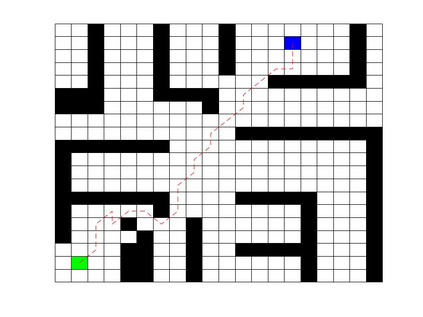
Deep Q Network (DQN) has several limitations when applied in planning a path in environment with a number of dilemmas according to our experiment. The reward function may be hard to model, and successful experience transitions are difficult to find in experience replay. In this context, this paper proposes an improved Double DQN (DDQN) to solve the problem by reference to A* and Rapidly-Exploring Random Tree (RRT). In order to achieve the rich experiments in experience replay, the initialization of robot in each training round is redefined based on RRT strategy. In addition, reward for the free positions is specially designed to accelerate the learning process according to the definition of position cost in A*. The simulation experimental results validate the efficiency of the improved DDQN, and robot could successfully learn the ability of obstacle avoidance and optimal path planning in which DQN or DDQN has no effect.
翻译:深Q网络(DQN)在根据我们的实验在规划环境路径时有几种局限性,根据我们的实验,在规划具有若干两难困境的路径时,其应用有几种局限性。奖励功能可能难以建模,成功的经验转换在经验重现中难以找到。在这方面,本文件建议改进双QN(DDQN),参照A* 和快速开发随机树(RRT)解决这个问题。为了实现经验重播的丰富实验,根据RRT战略重新定义了每轮培训回合中机器人的初始化。此外,根据A* 中定位成本的定义,免费职位的奖励是专门设计的,目的是加速学习过程。模拟实验结果验证了改进的DDQN的效率,机器人可以成功学习避免障碍和最佳路径规划的能力,而DQN或DQN在其中没有效果。