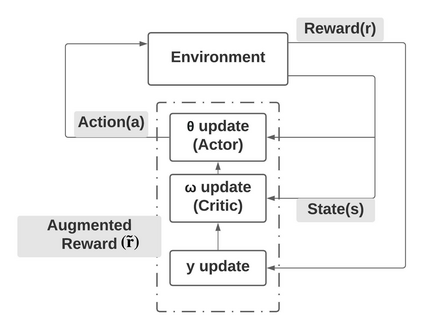
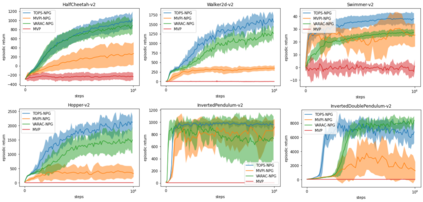
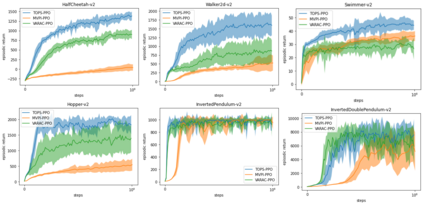
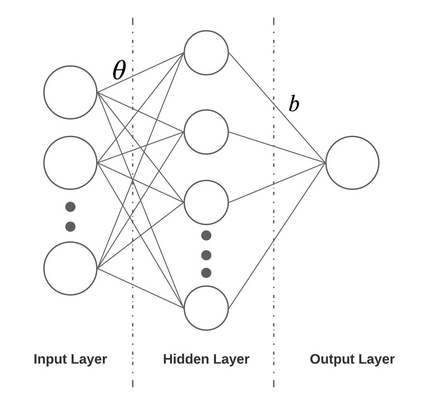
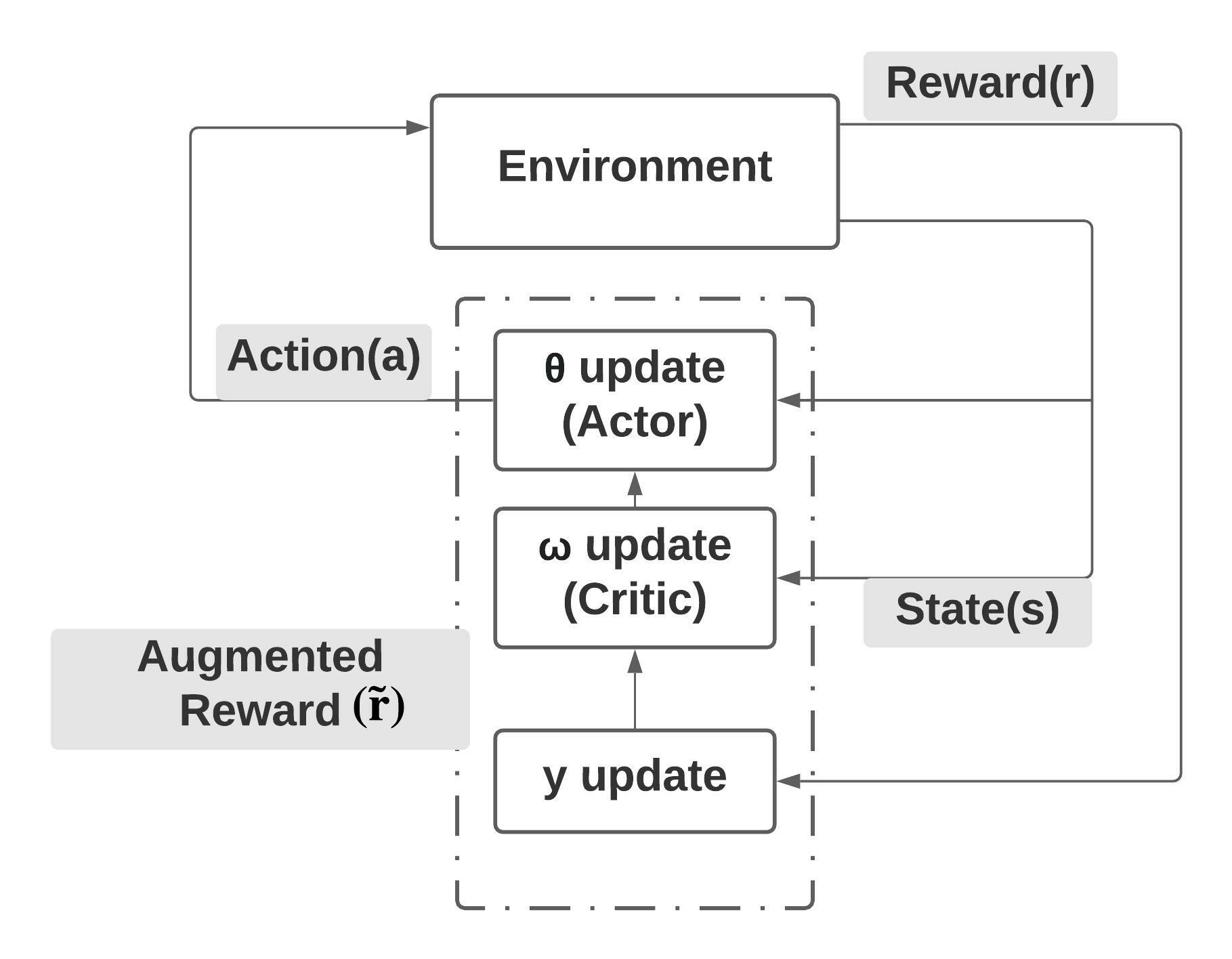
Risk-averse problems receive far less attention than risk-neutral control problems in reinforcement learning, and existing risk-averse approaches are challenging to deploy to real-world applications. One primary reason is that such risk-averse algorithms often learn from consecutive trajectories with a certain length, which significantly increases the potential danger of causing dangerous failures in practice. This paper proposes Transition-based VOlatility-controlled Policy Search (TOPS), a novel algorithm that solves risk-averse problems by learning from (possibly non-consecutive) transitions instead of only consecutive trajectories. By using an actor-critic scheme with an overparameterized two-layer neural network, our algorithm finds a globally optimal policy at a sublinear rate with proximal policy optimization and natural policy gradient, with effectiveness comparable to the state-of-the-art convergence rate of risk-neutral policy-search methods. The algorithm is evaluated on challenging Mujoco robot simulation tasks under the mean-variance evaluation metric. Both theoretical analysis and experimental results demonstrate a state-of-the-art level of risk-averse policy search methods.
翻译:与强化学习中的风险中性控制问题相比,风险偏重问题得到的关注远不如加强学习中的风险中性控制问题,而现有的风险偏重方法在部署到现实世界应用方面具有挑战性。一个主要原因是,这种风险偏重算法往往从一定长度的连续轨迹中学习,这大大增加了在实践中造成危险失败的潜在危险。本文件提出了基于过渡的无孔径控制政策搜索(TOOPS),这是一种新颖的算法,它通过学习(可能不是连带的)过渡而不是仅仅连续的轨迹来解决风险反性问题。通过使用具有超分度的双层神经网络的行为体-critical计划,我们的算法在亚线速率上找到了一种全球最佳的政策,配有准度政策优化和自然政策梯度,其效力可与风险中性政策研究方法的最新趋同率相比。根据中度评价指标对挑战的穆乔科机器人模拟任务进行评估。理论分析和实验结果都显示了风险反政策搜索方法的状态。