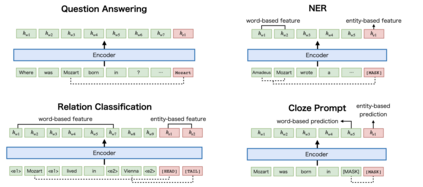
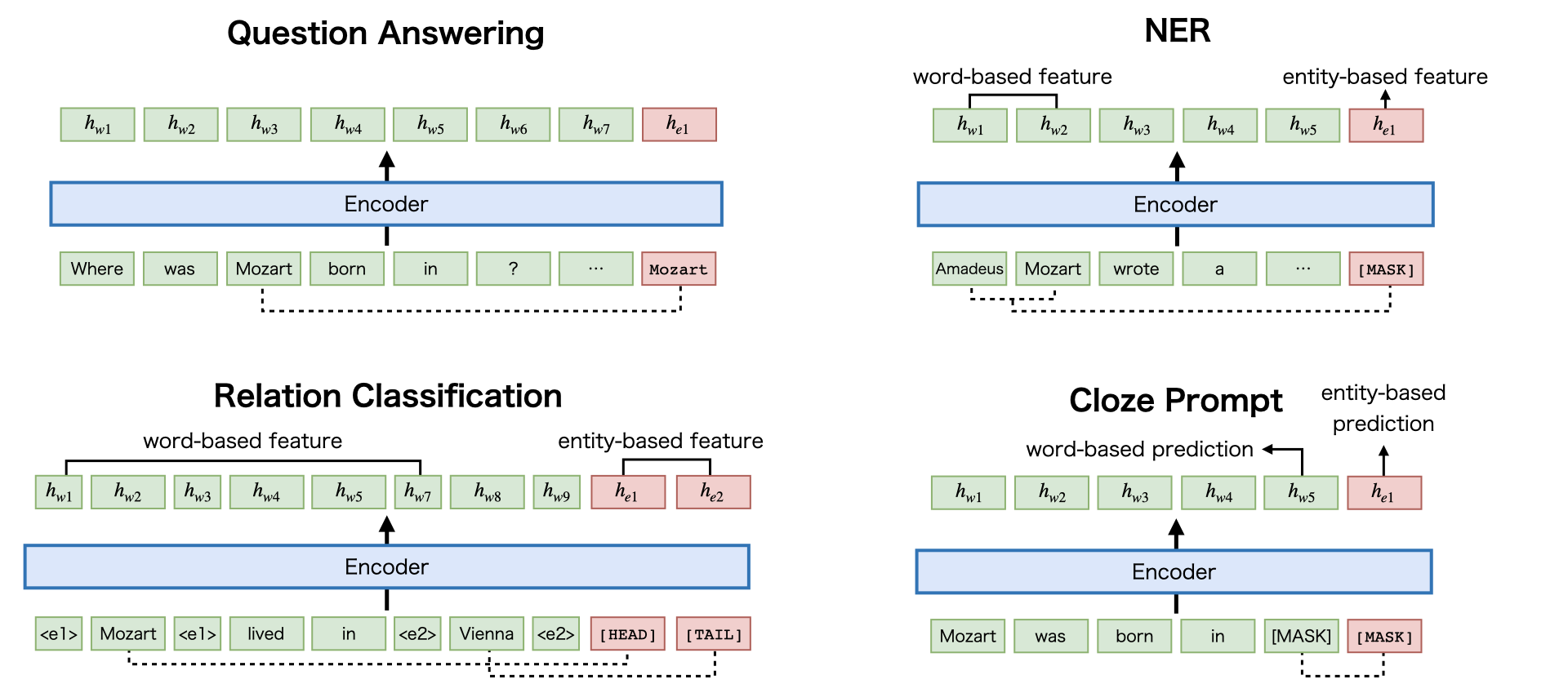
Recent studies have shown that multilingual pretrained language models can be effectively improved with cross-lingual alignment information from Wikipedia entities. However, existing methods only exploit entity information in pretraining and do not explicitly use entities in downstream tasks. In this study, we explore the effectiveness of leveraging entity representations for downstream cross-lingual tasks. We train a multilingual language model with 24 languages with entity representations and show the model consistently outperforms word-based pretrained models in various cross-lingual transfer tasks. We also analyze the model and the key insight is that incorporating entity representations into the input allows us to extract more language-agnostic features. We also evaluate the model with a multilingual cloze prompt task with the mLAMA dataset. We show that entity-based prompt elicits correct factual knowledge more likely than using only word representations.
翻译:最近的研究显示,通过维基百科各实体的跨语文统一信息,多语种预先培训语言模式可以有效地得到改进;然而,现有方法只利用预先培训中的实体信息,而没有明确利用实体开展下游任务;在本研究中,我们探讨了利用实体代表机构开展下游跨语文任务的效力;我们用实体代表机构培训了具有24种语文的多语种语言模式,并表明该模式在各种跨语文转移任务中一贯优于基于字种的预先培训模式;我们还分析了该模式和关键见解,即将实体代表机构纳入投入中,使我们得以提取更多的语文 -- -- 不可知性特征;我们还利用MLAMA数据集,用多语种的快速任务来评估该模式。我们显示,基于实体的及时获取正确知识比仅使用文字代表机构更有可能。