
题目: PRETRAINED ENCYCLOPEDIA: WEAKLY SUPERVISED KNOWLEDGE-PRETRAINED LANGUAGE MODEL
摘要: 预训练语言模型的最新突破表明了自监督学习在广泛的自然语言处理任务中的有效性。除了标准的句法和语义NLP任务外,预训练模型在涉及真实世界知识的任务上也取得了很强的改进,这表明大规模语言建模可能是一种隐含的知识获取方法。在这项工作中,我们进一步研究了BERT等预训练模型使用零镜头事实完成任务捕获知识的程度,此外,我们还提出了一个简单而有效的弱监督预训练目标,该目标明确地迫使模型包含关于真实世界实体的知识。用我们的新目标训练的模型在事实完成任务上有显著的改进。当应用于下游任务时,我们的模型在四个实体相关的问答数据集(即WebQuestions、TriviaQA、SearchQA和Quasar-T)上的平均F1改进为2.7,标准细粒度实体类型数据集(即FIGER)的平均精度提高为5.7。
作者简介:
Wenhan Xiong,加州大学圣塔芭芭拉分校计算机科学博士,主要研究结构化和非结构化文本数据的信息提取、问答和推理。https://xwhan.github.io/
William Yang Wang,加州大学圣塔芭芭拉分校自然语言处理小组和负责的机器学习中心的主任。他是加州大学圣塔芭芭拉分校计算机科学系的助理教授。他获得了卡内基梅隆大学计算机科学学院的博士学位。他对数据科学的机器学习方法有着广泛的兴趣,包括统计关系学习、信息提取、计算社会科学、语音和视觉。https://sites.cs.ucsb.edu/~william/
成为VIP会员查看完整内容
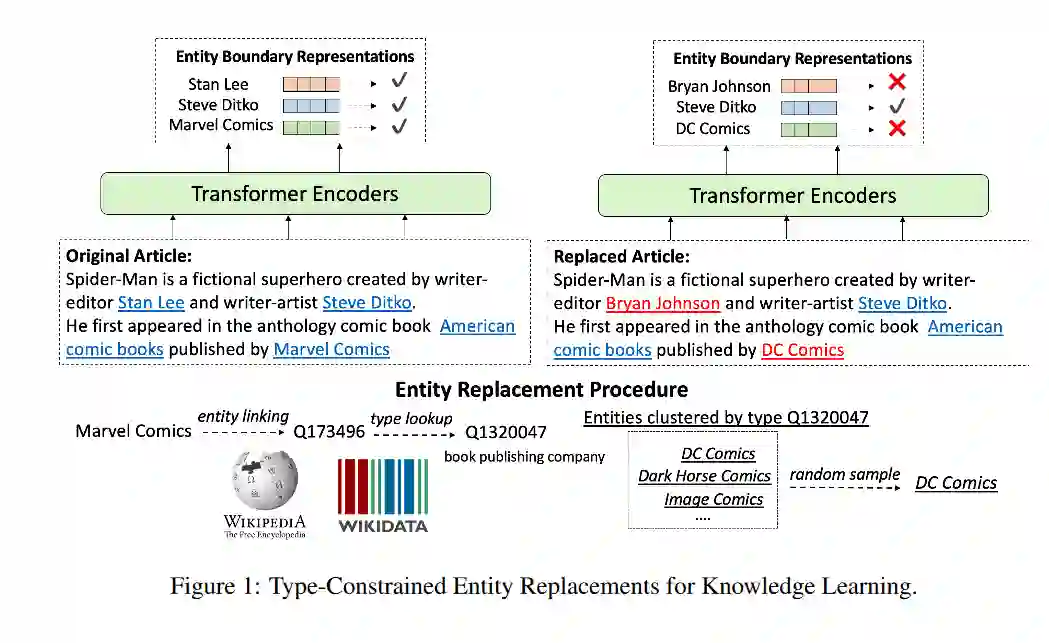
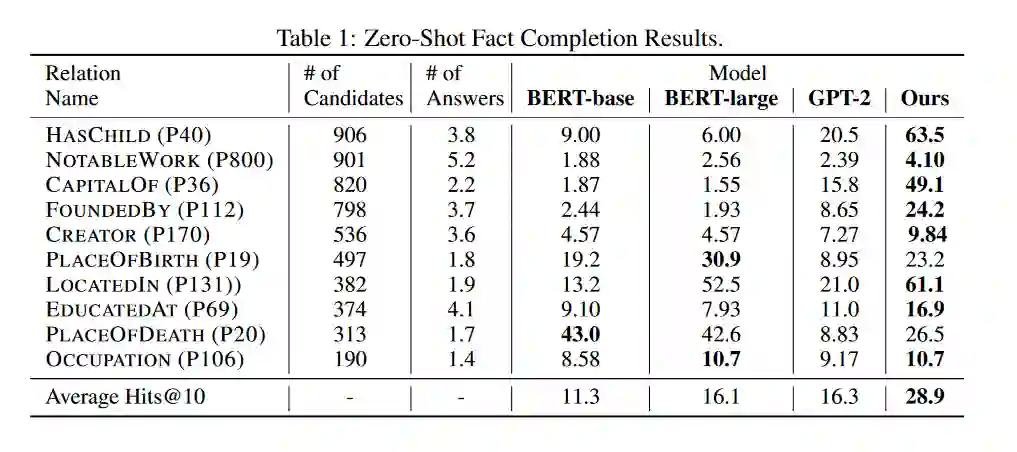
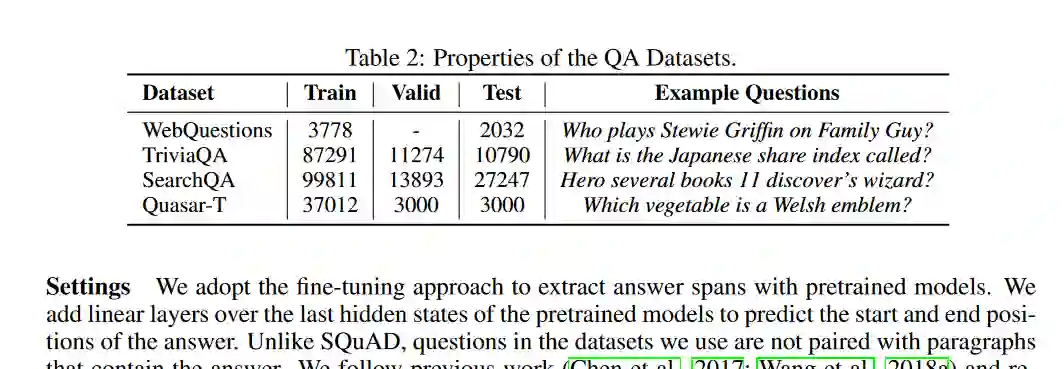
相关内容

弱监督学习:监督学习的一种。大致分3类,第一类是不完全监督(incomplete supervision),即,只有训练集的一个(通常很小的)子集是有标签的,其他数据则没有标签。这种情况发生在各类任务中。例如,在图像分类任务中,真值标签由人类标注者给出的。从互联网上获取巨量图片很容易,然而考虑到标记的人工成本,只有一个小子集的图像能够被标注。第二类是不确切监督(inexact supervision),即,图像只有粗粒度的标签。第三种是不准确的监督(inaccurate supervision),模型给出的标签不总是真值。出现这种情况的常见原因有,图片标注者不小心或比较疲倦,或者某些图片就是难以分类。
【ACL2020】不要停止预训练:根据领域和任务自适应调整语言模型,Don't Stop Pretraining: Adapt Language Models to Domains and Tasks
专知会员服务
46+阅读 · 2020年4月25日
专知会员服务
52+阅读 · 2020年1月20日
Arxiv
7+阅读 · 2019年2月3日




相关VIP内容
【ACL2020】不要停止预训练:根据领域和任务自适应调整语言模型,Don't Stop Pretraining: Adapt Language Models to Domains and Tasks
专知会员服务
46+阅读 · 2020年4月25日
专知会员服务
52+阅读 · 2020年1月20日
相关资讯
相关论文
Arxiv
7+阅读 · 2019年2月3日