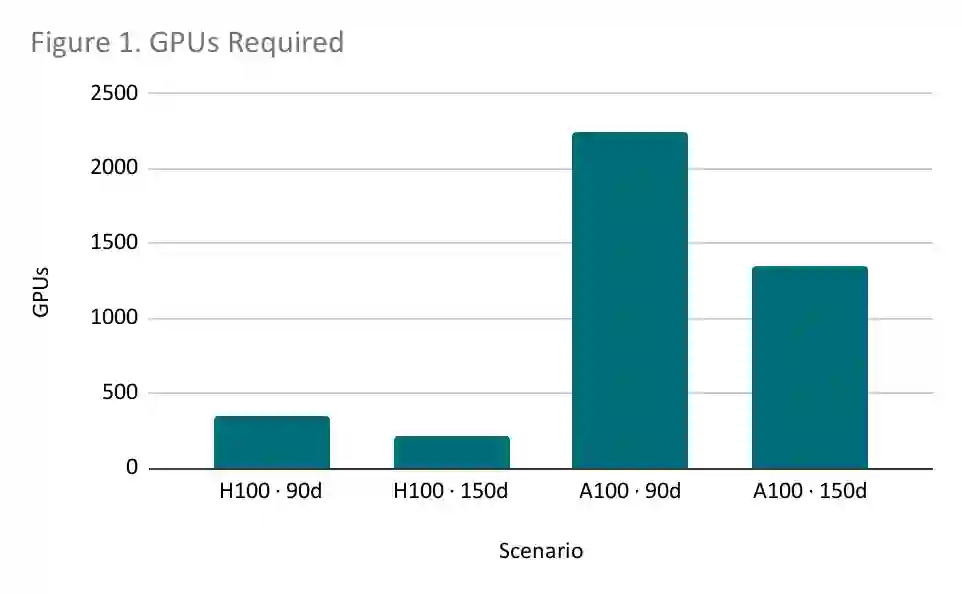
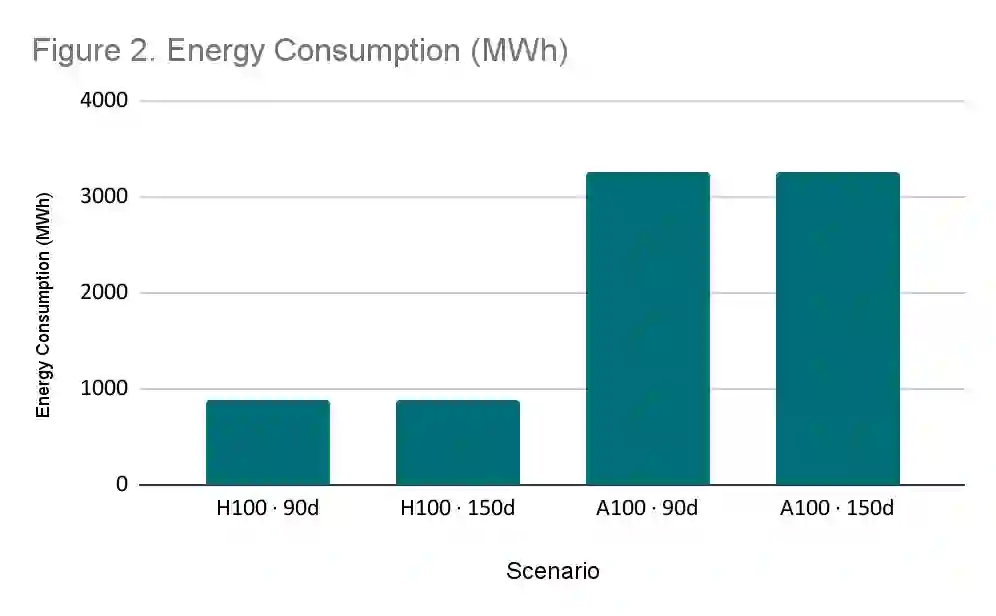
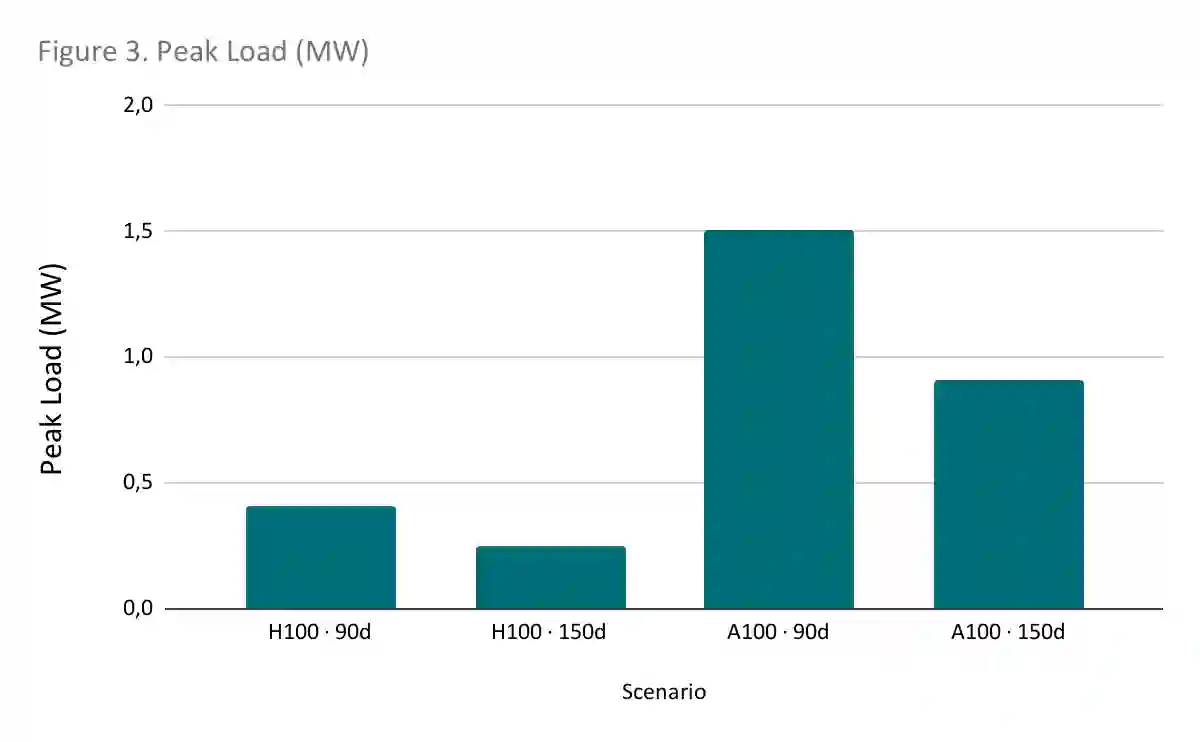
The rapid escalation of computational requirements for training large-scale language models has reinforced structural asymmetries between high-capacity jurisdictions and countries in the Global South. This paper examines the technical and fiscal feasibility of sovereign-scale language model training in Brazil and Mexico under conditions of constrained hardware access, energy availability, and fiscal ceilings. Using a dual-axis design that varies accelerator generation (NVIDIA H100 vs. A100) and training duration (90 vs. 150 days), we estimate compute demand, energy consumption, capital expenditures, and regulatory compatibility for the training of a 10-trillion-token model. Our findings show that while all configurations remain below export-control and electrical infrastructure thresholds, fiscal viability is determined by hardware efficiency. H100-based scenarios achieve training feasibility at a total cost of 8-14 million USD, while A100 deployments require 19-32 million USD due to higher energy and hardware demand. We argue that extending training timelines should be treated as a policy lever to mitigate hardware constraints, enabling the production of usable, auditable, and locally aligned models without competing at the global frontier. This study contributes to the discourse on AI compute governance and technological sovereignty by highlighting context-sensitive strategies that allow middle-income countries to establish sustainable and strategically sufficient AI capabilities.
翻译:大规模语言模型训练所需计算资源的急剧增长,加剧了高算力司法管辖区与全球南方国家之间的结构性不对称。本文研究了在硬件获取受限、能源供应有限及财政预算约束条件下,巴西与墨西哥开展主权级语言模型训练的技术与财政可行性。通过采用双轴设计——分别调整加速器代际(NVIDIA H100 与 A100)和训练时长(90 天与 150 天),我们估算了训练一个 10 万亿词元模型所需的算力需求、能耗、资本支出及监管兼容性。研究结果表明,尽管所有配置方案均未超出出口管制与电力基础设施的阈值,但财政可行性取决于硬件效率。基于 H100 的方案以 800 万至 1400 万美元的总成本实现了训练可行性,而 A100 部署因更高的能源与硬件需求需要 1900 万至 3200 万美元。我们认为,延长训练周期应被视为缓解硬件约束的政策杠杆,使得在不参与全球前沿竞争的情况下,能够产出可用、可审计且符合本地需求的语言模型。本研究通过强调适应具体情境的策略——使中等收入国家能够建立可持续且战略上自足的人工智能能力,为人工智能算力治理与技术主权领域的讨论提供了新的见解。