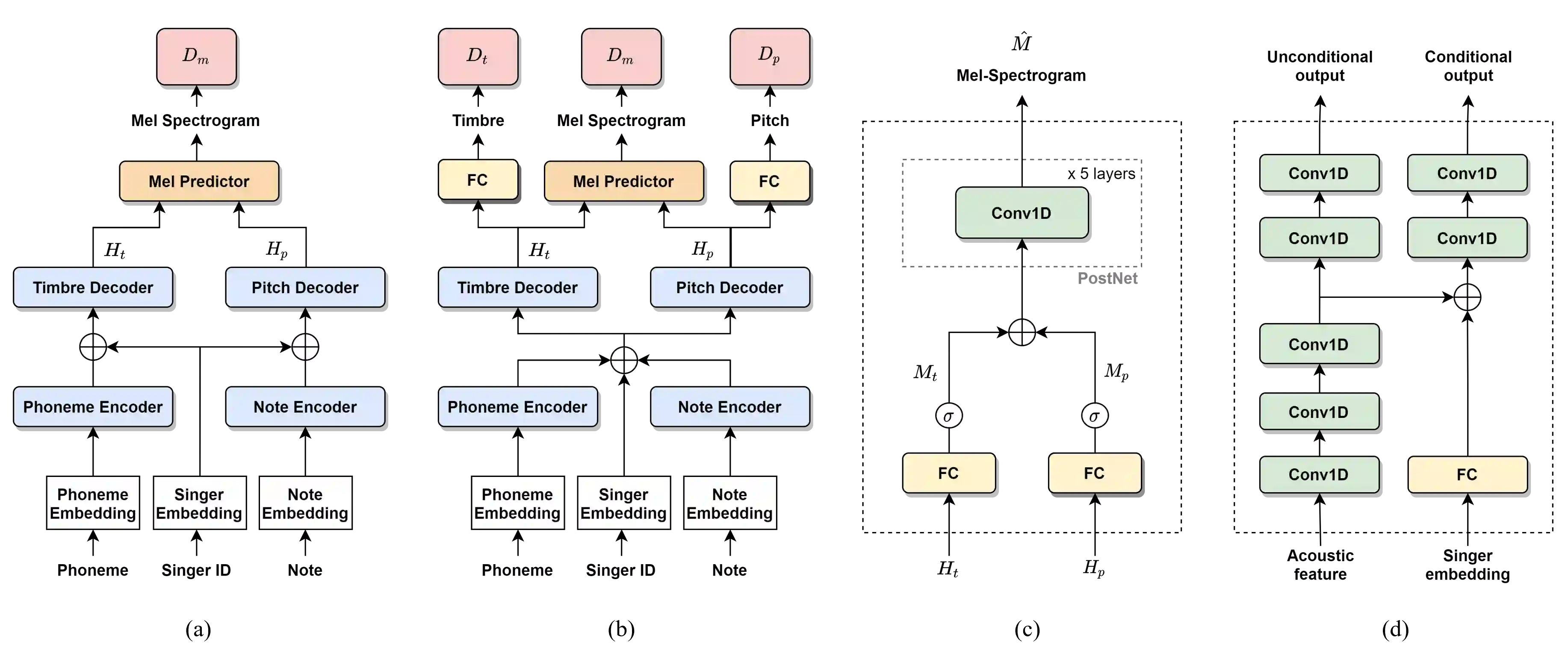
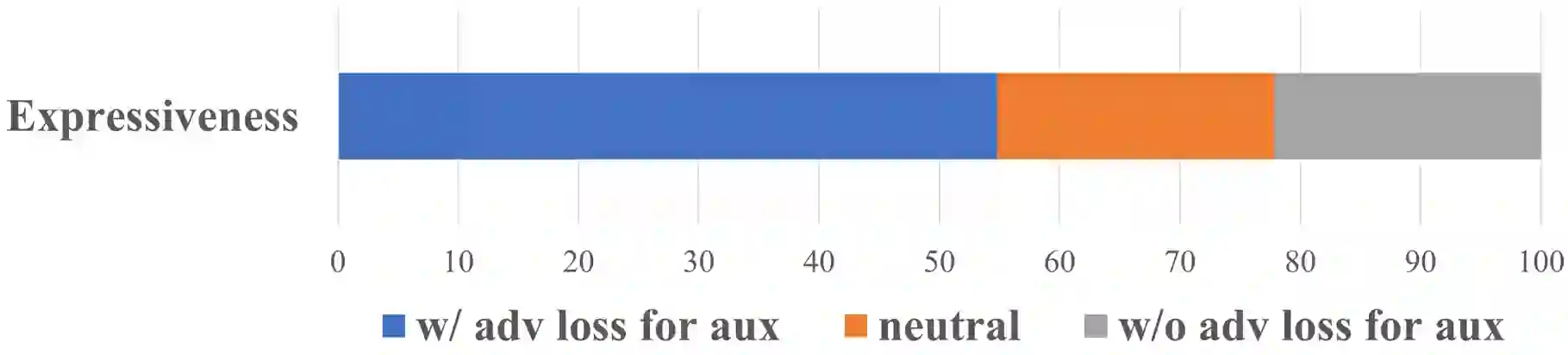
Recently, deep learning-based generative models have been introduced to generate singing voices. One approach is to predict the parametric vocoder features consisting of explicit speech parameters. This approach has the advantage that the meaning of each feature is explicitly distinguished. Another approach is to predict mel-spectrograms for a neural vocoder. However, parametric vocoders have limitations of voice quality and the mel-spectrogram features are difficult to model because the timbre and pitch information are entangled. In this study, we propose a singing voice synthesis model with multi-task learning to use both approaches -- acoustic features for a parametric vocoder and mel-spectrograms for a neural vocoder. By using the parametric vocoder features as auxiliary features, the proposed model can efficiently disentangle and control the timbre and pitch components of the mel-spectrogram. Moreover, a generative adversarial network framework is applied to improve the quality of singing voices in a multi-singer model. Experimental results demonstrate that our proposed model can generate more natural singing voices than the single-task models, while performing better than the conventional parametric vocoder-based model.
翻译:最近,引入了深层次的基于学习的基因模型来产生歌声。一种方法是预测由明确的语音参数组成的微调参数。这种方法的好处是,每个特征的含义都有明确的区别。另一种方法是预测神经电动电动器的光谱;然而,光学电动器的声音质量有局限性,而光谱特征很难模型,因为音频和声频信息相互交织。在这项研究中,我们提议了一种配有多任务学习的歌声合成模型,使用两种方法 -- -- 准电动电动器的声学特征和电动电动电动器的光谱仪。通过使用对准电动电动电动器的光谱特征作为辅助特征,拟议的模型可以有效地分解和控制Mel-光谱的音调和声调成分。此外,还应用了一种基因对抗网络框架来提高多任务模型中歌声的质量。实验结果显示,我们提议的模型能够产生更自然的、而不是更自然的、比演化的单式模型。