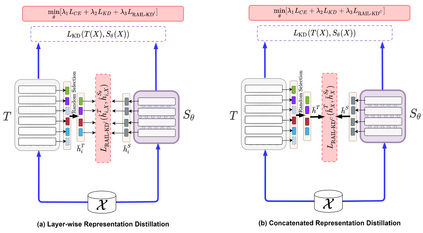
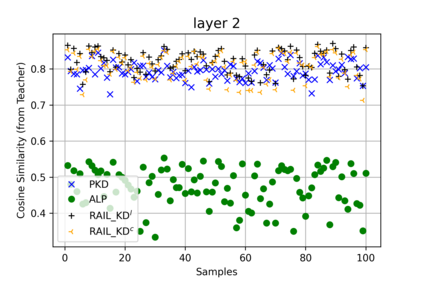
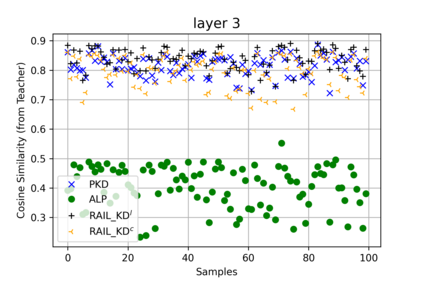
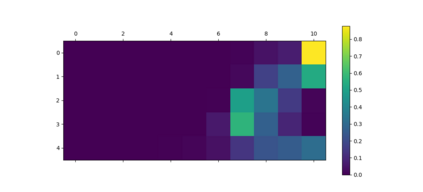
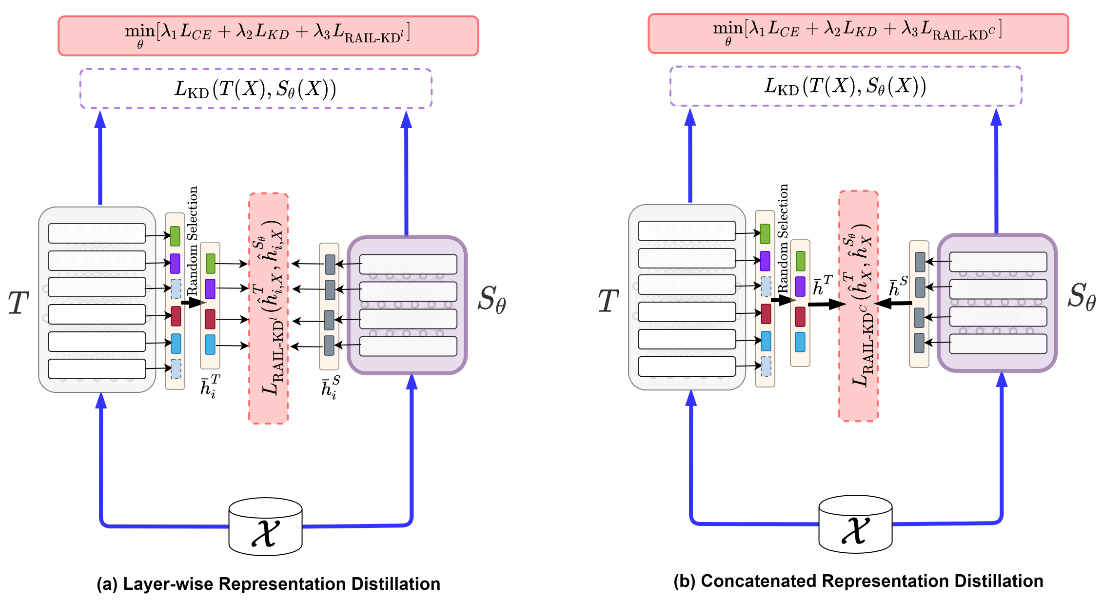
Intermediate layer knowledge distillation (KD) can improve the standard KD technique (which only targets the output of teacher and student models) especially over large pre-trained language models. However, intermediate layer distillation suffers from excessive computational burdens and engineering efforts required for setting up a proper layer mapping. To address these problems, we propose a RAndom Intermediate Layer Knowledge Distillation (RAIL-KD) approach in which, intermediate layers from the teacher model are selected randomly to be distilled into the intermediate layers of the student model. This randomized selection enforce that: all teacher layers are taken into account in the training process, while reducing the computational cost of intermediate layer distillation. Also, we show that it act as a regularizer for improving the generalizability of the student model. We perform extensive experiments on GLUE tasks as well as on out-of-domain test sets. We show that our proposed RAIL-KD approach outperforms other state-of-the-art intermediate layer KD methods considerably in both performance and training-time.
翻译:中间层知识蒸馏(KD)可以改进标准的KD技术(仅针对教师和学生模型的产出),特别是大型的经过培训的语言模型;然而,中间层蒸馏由于过重的计算负担和为建立适当的层图绘制所需的工程努力而受到影响;为解决这些问题,我们建议采用RAndom中间层知识蒸馏(RAIL-KD)方法,其中教师模型的中间层随机选择,以蒸馏成学生模型的中间层。这种随机选择强制要求:在培训过程中考虑到所有教师层,同时降低中间层蒸馏的计算成本。此外,我们还表明,它是一种常规化的作用,可以改进学生模型的通用性。我们在GLUE任务以及外部测试场上进行了广泛的实验。我们表明,我们提议的RAI-KD方法在业绩和培训期间大大地超越了其他最先进的中间层KD方法。