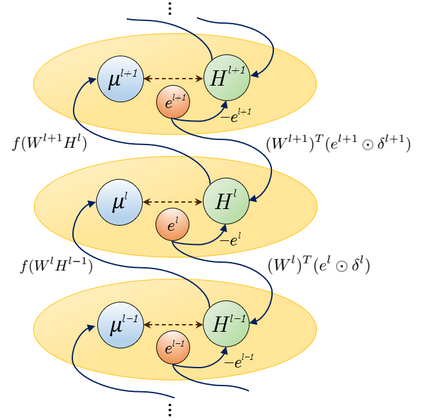
Nearly all state-of-the-art deep learning algorithms rely on error backpropagation, which is generally regarded as biologically implausible. An alternative way of training an artificial neural network is through treating each unit in the network as a reinforcement learning agent, and thus the network is considered as a team of agents. As such, all units can be trained by REINFORCE, a local learning rule modulated by a global signal that is more consistent with biologically observed forms of synaptic plasticity. Although this learning rule follows the gradient of return in expectation, it suffers from high variance and thus the low speed of learning, rendering it impractical to train deep networks. We therefore propose a novel algorithm called MAP propagation to reduce this variance significantly while retaining the local property of the learning rule. Experiments demonstrated that MAP propagation could solve common reinforcement learning tasks at a similar speed to backpropagation when applied to an actor-critic network. Our work thus allows for the broader application of the teams of agents in deep reinforcement learning.
翻译:几乎所有最先进的深层学习算法都依赖错误回向变异法,这通常被认为是不可信的生物。培训人工神经网络的另一种方法就是将网络中的每个单元视为强化学习剂,因此网络可以被视为一个代理体。因此,所有单元都可以由REINFORCE来培训,这是一个本地学习规则,由更符合生物观测的合成塑料形式的全球信号来调节。虽然这种学习规则遵循返回的梯度,但差异很大,因此学习速度低,使得深层网络的培训不切实际。因此,我们提议了一个称为MAP传播的新算法,以大幅缩小这一差异,同时保留学习规则的当地特性。实验表明,MAP传播可以以类似的速度解决共同的强化学习任务,在应用到一个演员-批评网络时,其速度与反向适应。因此,我们的工作允许在深层强化学习中更广泛地应用各种代理体。