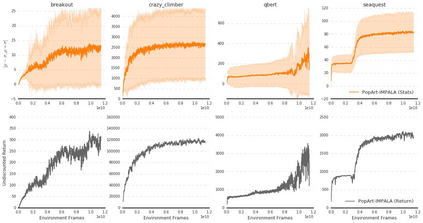
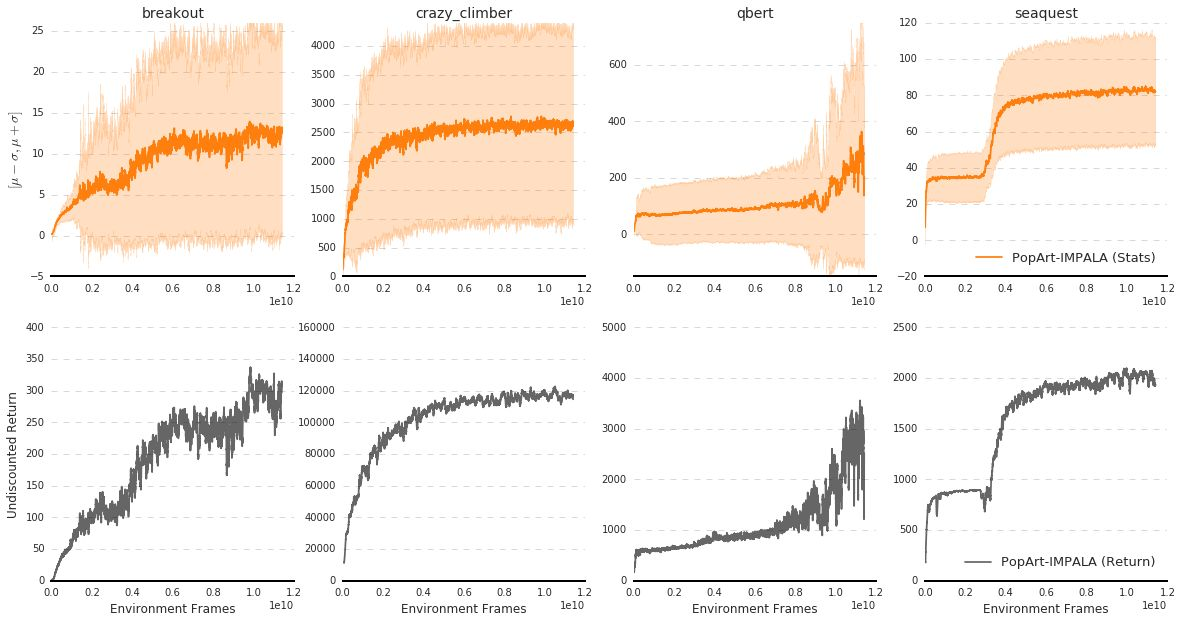
The reinforcement learning community has made great strides in designing algorithms capable of exceeding human performance on specific tasks. These algorithms are mostly trained one task at the time, each new task requiring to train a brand new agent instance. This means the learning algorithm is general, but each solution is not; each agent can only solve the one task it was trained on. In this work, we study the problem of learning to master not one but multiple sequential-decision tasks at once. A general issue in multi-task learning is that a balance must be found between the needs of multiple tasks competing for the limited resources of a single learning system. Many learning algorithms can get distracted by certain tasks in the set of tasks to solve. Such tasks appear more salient to the learning process, for instance because of the density or magnitude of the in-task rewards. This causes the algorithm to focus on those salient tasks at the expense of generality. We propose to automatically adapt the contribution of each task to the agent's updates, so that all tasks have a similar impact on the learning dynamics. This resulted in state of the art performance on learning to play all games in a set of 57 diverse Atari games. Excitingly, our method learned a single trained policy - with a single set of weights - that exceeds median human performance. To our knowledge, this was the first time a single agent surpassed human-level performance on this multi-task domain. The same approach also demonstrated state of the art performance on a set of 30 tasks in the 3D reinforcement learning platform DeepMind Lab.
翻译:强化学习社区在设计能够超越特定任务的人性表现的算法方面取得了长足的进步。 这些算法大多是当时训练的一项任务, 每一个新任务都需要训练一个品牌的新代理实例。 这意味着学习算法是一般性的, 但每个解决方案都不是; 每个代理商只能解决它所训练的一项任务。 在这项工作中, 我们研究学习一次掌握一个而不是多个顺序决定任务的问题。 多任务学习的一个一般问题是, 必须在为单一学习系统的有限资源竞争的多重任务需求之间找到平衡。 许多学习算法可以因需要解决的一组任务中的某些任务而分心。 许多学习算法在学习过程中显得更加突出, 例如因为学习算法是普通的密度或规模。 我们研究每个代理商的每个任务的贡献会自动适应于代理商的更新, 这样所有任务都会对学习的动态产生类似的影响。 许多学习算法可以分级地在一组需要解决的任务中学习所有游戏的深度。 这些任务看起来更突出, 举例来说, 也就是由于任务中的密度或规模的强度, 一种经过训练的 一种单一操作方法。