**从简单的样本到困难的样本,以一种有意义的顺序,使用课程学习可以提供比基于随机数据变换的标准训练方法更好的性能,而不需要额外的计算成本。**课程学习策略已成功地应用于机器学习的各个领域,广泛的任务。然而,必须找到一种方法来对样本从容易到难进行排序,以及正确的节奏函数来引入更难的数据,这可能会限制课程方法的使用。在本综述中,我们展示了这些限制是如何在文献中被处理的,并且我们为机器学习中的各种任务提供了不同的课程学习实例。我们根据不同的分类标准,手工构建了一个多角度的课程学习方法分类。我们进一步使用凝聚聚类算法建立课程学习方法的层次树,将发现的聚类与我们的分类方法联系起来。最后,我们对未来的工作提出了一些有趣的方向。
https://www.zhuanzhi.ai/paper/737037858f92a59732f06559b38cfc15
背景和动机。深度神经网络已经在各种各样的任务成为最先进的方法,从对象识别图像[1],[2],[3],[4]和医学成像[5],[11]0,[11]1,[11]3到文本分类[11]2,[10],[11],[12]和语音识别[13],[14]。这一研究领域的主要焦点是构建越来越深入的神经体系结构,这是最近性能改进的主要驱动力。例如,Krizhevsky等人的CNN模型[1]在只有8层结构的ImageNet[15]上达到了15.4%的top-5误差,而最近的ResNet模型[4]达到了3.6%的top-5误差,有152层。在过去的几年里,CNN的架构已经进化到可以容纳更多的卷积层,减少滤波器的尺寸,甚至消除完全连接的层,相比之下,人们对改进训练过程的关注较少。上面提到的最先进的神经模型的一个重要限制是在训练过程中以随机顺序考虑示例。事实上,训练通常是用小批随机梯度下降的某种变体来进行的,每个小批中的例子是随机选择的。
既然神经网络的架构是受到人类大脑的启发,那么我们似乎可以合理地认为,学习过程也应该受到人类学习方式的启发。与机器通常接受的训练方式的一个本质区别是,人类学习基本(简单)概念的时间较早,学习高级(困难)概念的时间较晚。这基本上反映在世界上所有学校系统所教授的课程中,因为当例子不是随机呈现,而是按照有意义的顺序组织起来时,人类学习得更好。使用类似的策略训练机器学习模型,我们可以实现两个重要的好处: (i) 提高训练过程的收敛速度和(ii) 更好的准确性。Elman[16]对这一方向进行了初步研究。据我们所知,Bengio等人[17]是第一个在机器学习的背景下形成易-难训练策略的人,并提出了课程学习(CL)范式。这一开创性的工作激发了许多研究人员在各种应用领域研究课程学习策略,如弱监督对象定位[18],[19],[20],对象检测[21],[22],[23],[24]和神经机器翻译[25],[26],[27],[18]0等。这些研究的实证结果表明,用课程学习取代基于随机小批量抽样的传统训练有明显的好处。尽管课程学习在多个领域都取得了一致的成功,但这种训练策略并没有被主流作品所采用。这一事实促使我们撰写了这篇关于课程学习方法的综述,以提高课程学习方法的普及程度。另一方面,研究人员提出了相反的策略,强调更难的例子,如硬样例挖掘(HEM)[29],[30],[31],[32]或反课程[33],[34],在特定条件下显示出改善的结果。
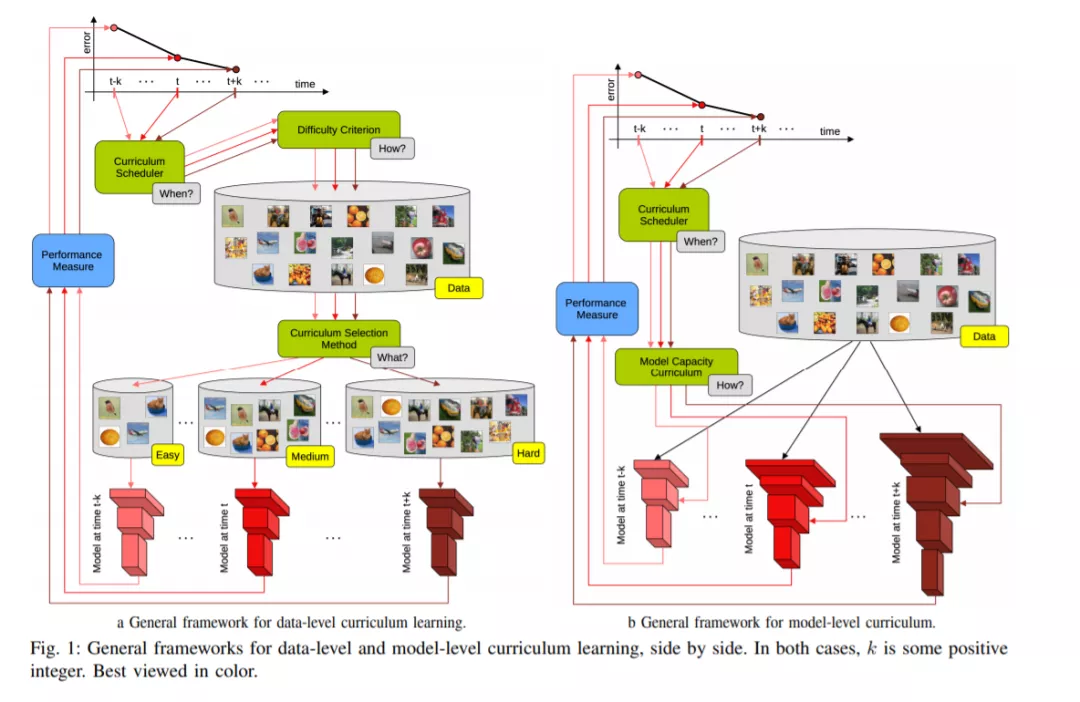
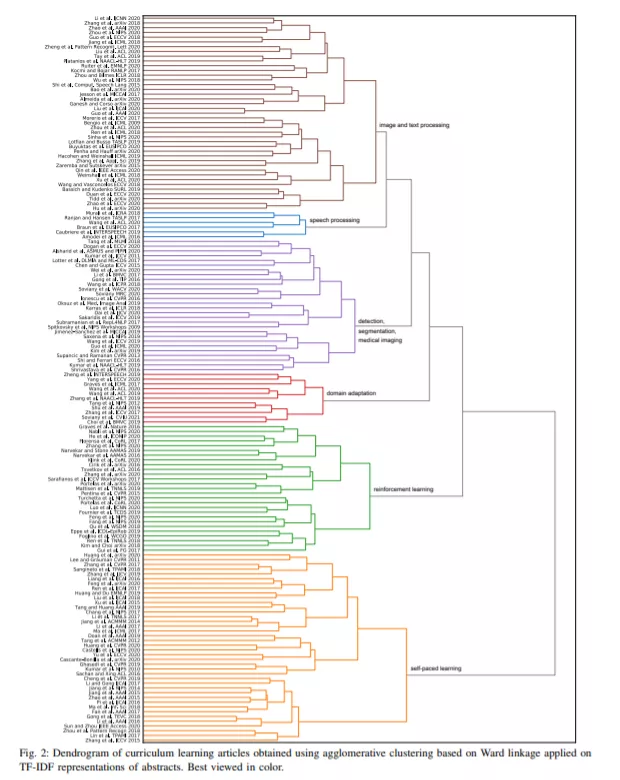
贡献。我们的第一个贡献是将现有的课程学习方法正式化。这使我们能够定义课程学习的一般形式。从理论上讲,我们将课程学习与任何机器学习方法的四个主要组成部分联系起来:数据、模型、任务和性能度量。我们观察到,课程学习可以应用于这些组成部分中的每一个,所有这些课程形式都有一个与损失函数平滑相关的联合解释。在此基础上,结合数据类型、任务、课程策略、排名标准和课程安排的正交分析视角,对课程学习方法进行了分类。我们用自动构建的课程方法层次树来验证人工构建的分类方法。在很大程度上,层次树确认了我们的分类,尽管它也提供了一些新的视角。在收集关于课程学习和定义课程学习方法分类的工作的同时,我们的综述也旨在展示课程学习的优势。因此,我们最后的贡献是在主流工作中提倡课程学习。