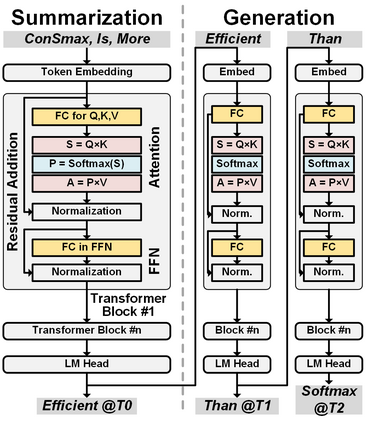
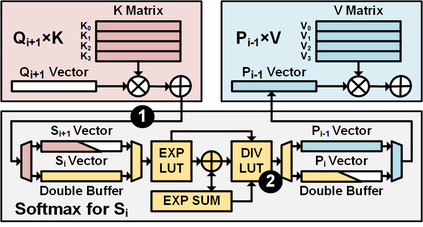
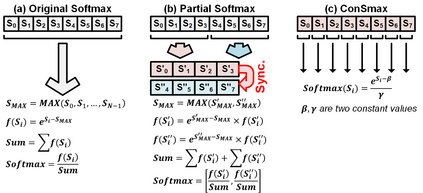
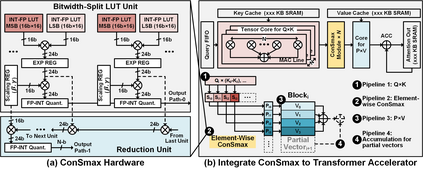
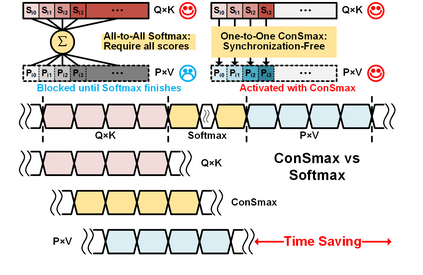
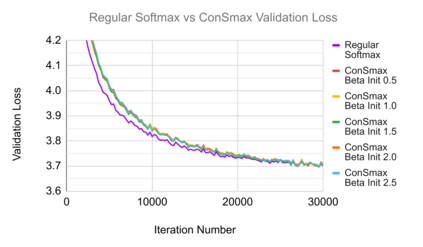
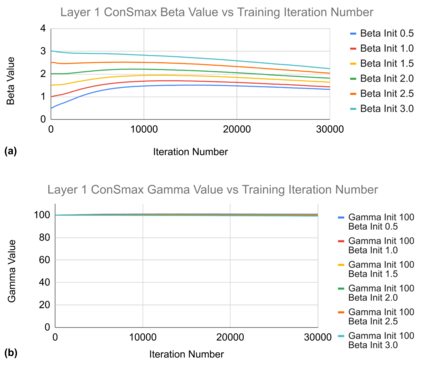
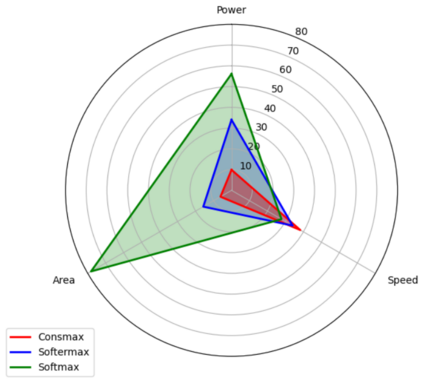
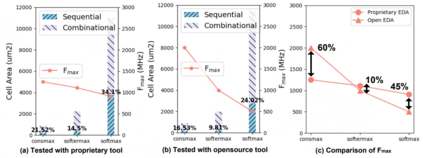
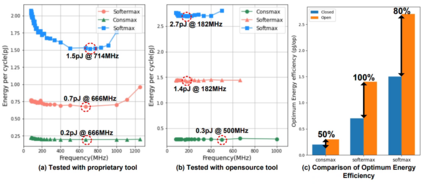
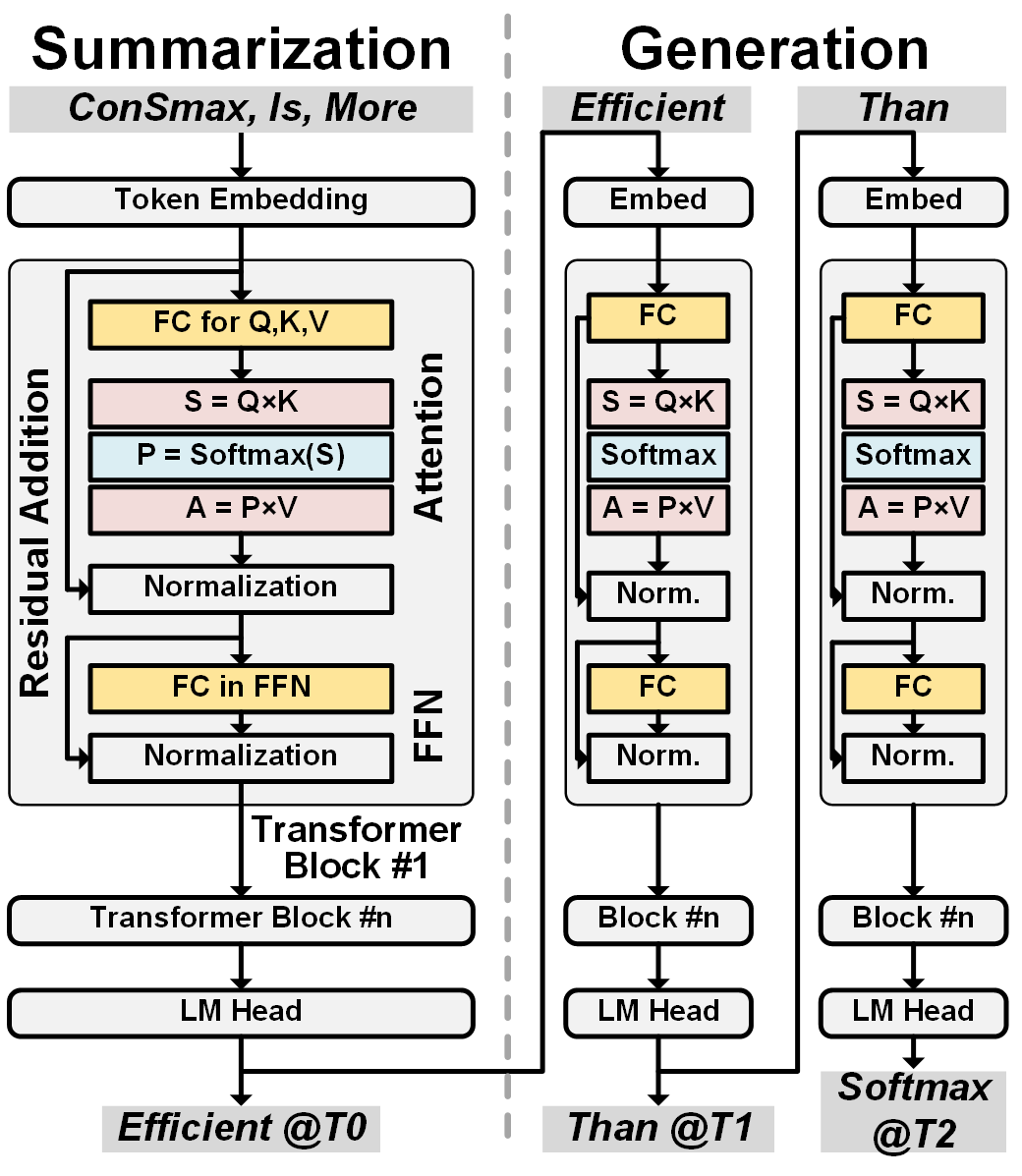
The self-attention mechanism sets transformer-based large language model (LLM) apart from the convolutional and recurrent neural networks. Despite the performance improvement, achieving real-time LLM inference on silicon is challenging due to the extensively used Softmax in self-attention. Apart from the non-linearity, the low arithmetic intensity greatly reduces the processing parallelism, which becomes the bottleneck especially when dealing with a longer context. To address this challenge, we propose Constant Softmax (ConSmax), a software-hardware co-design as an efficient Softmax alternative. ConSmax employs differentiable normalization parameters to remove the maximum searching and denominator summation in Softmax. It allows for massive parallelization while performing the critical tasks of Softmax. In addition, a scalable ConSmax hardware utilizing a bitwidth-split look-up table (LUT) can produce lossless non-linear operation and support mix-precision computing. It further facilitates efficient LLM inference. Experimental results show that ConSmax achieves a minuscule power consumption of 0.43 mW and area of 0.001 mm2 at 1-GHz working frequency and 22-nm CMOS technology. Compared to state-of-the-art Softmax hardware, ConSmax results in 14.5x energy and 14.0x area savings with a comparable accuracy on a GPT-2 model and the WikiText103 dataset.
翻译:暂无翻译