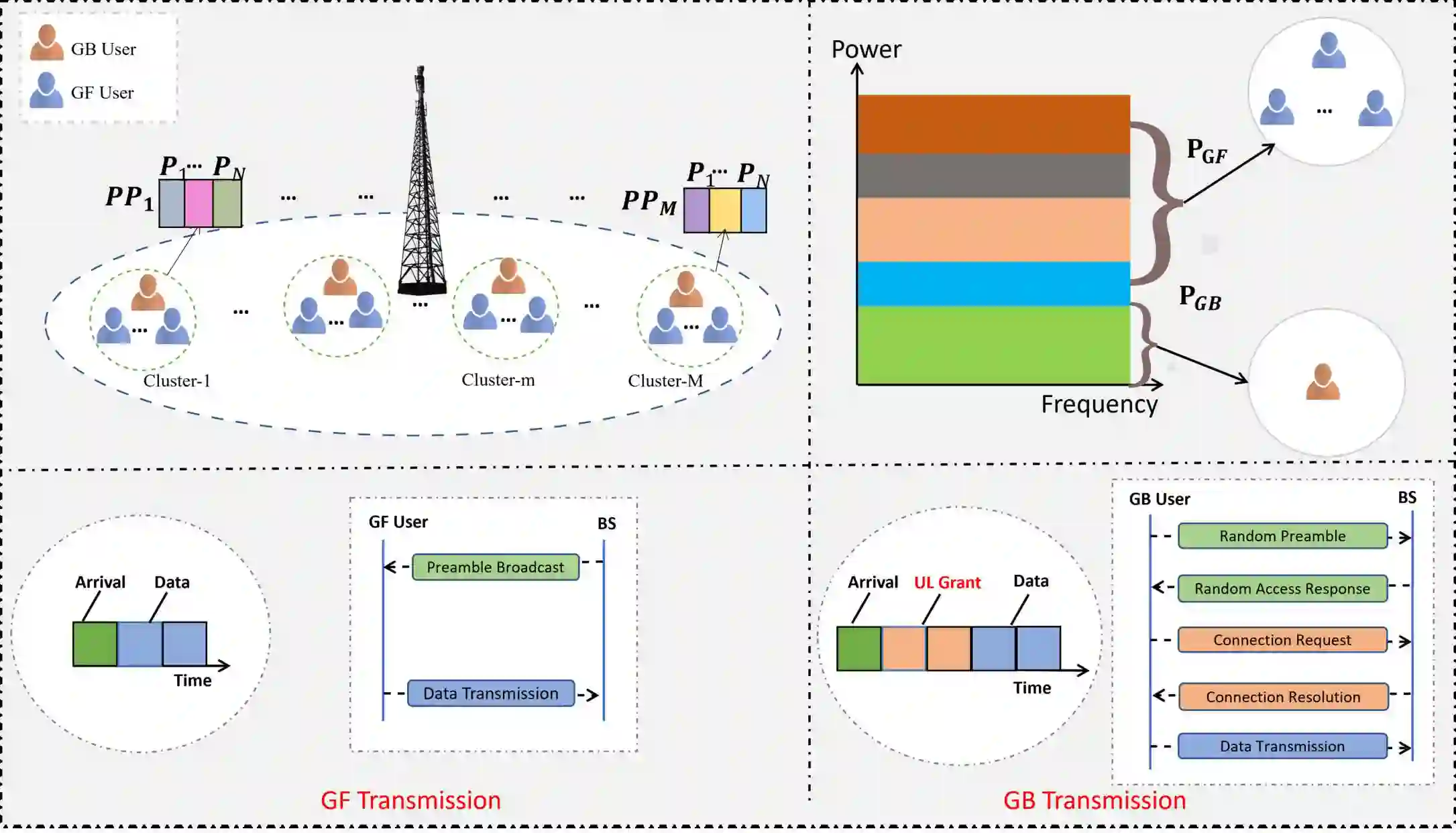
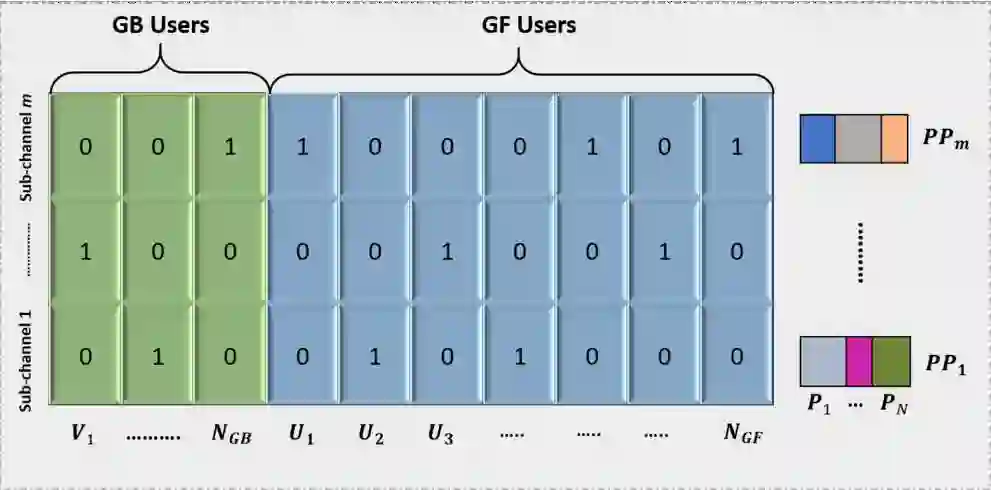
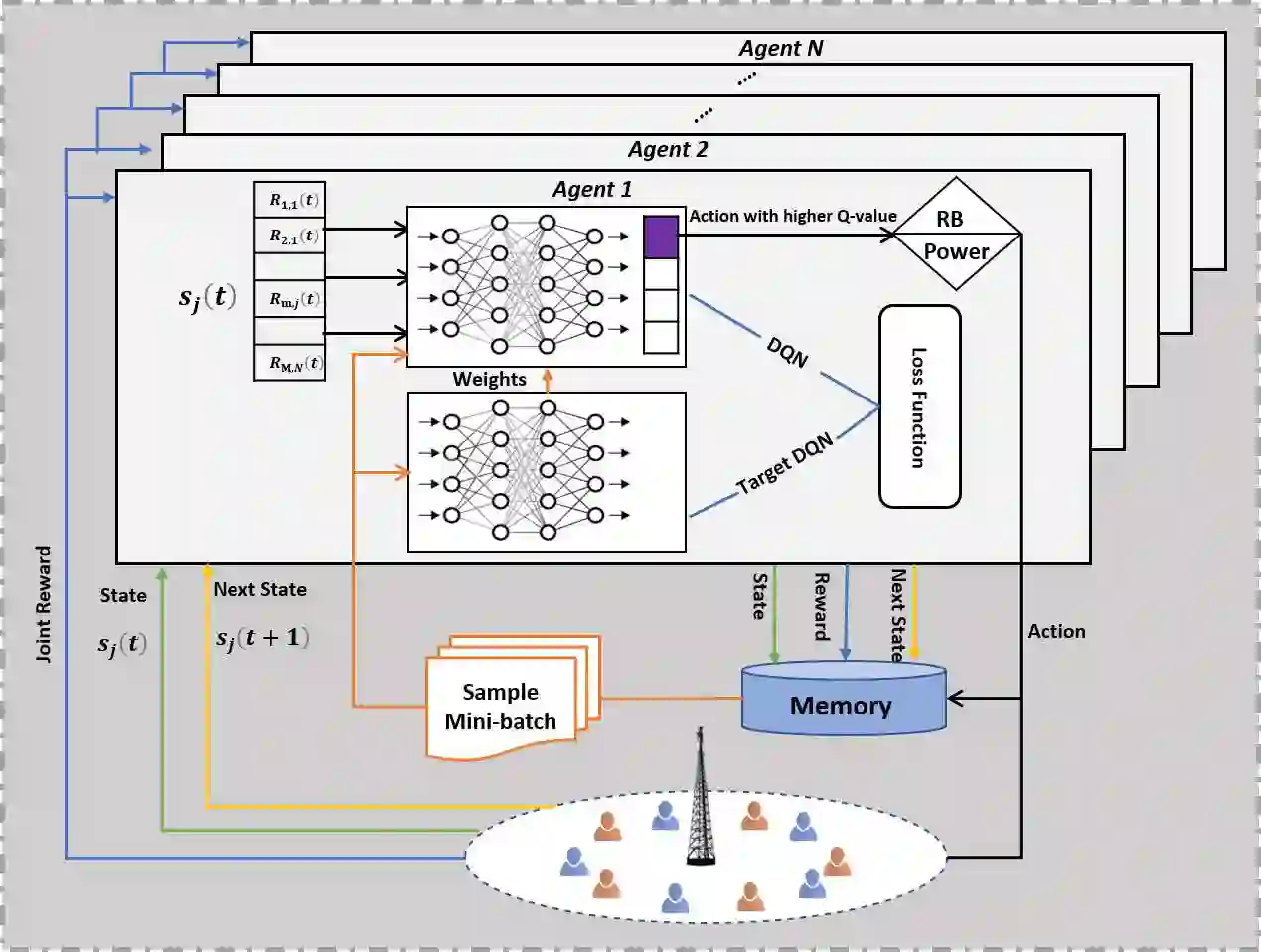
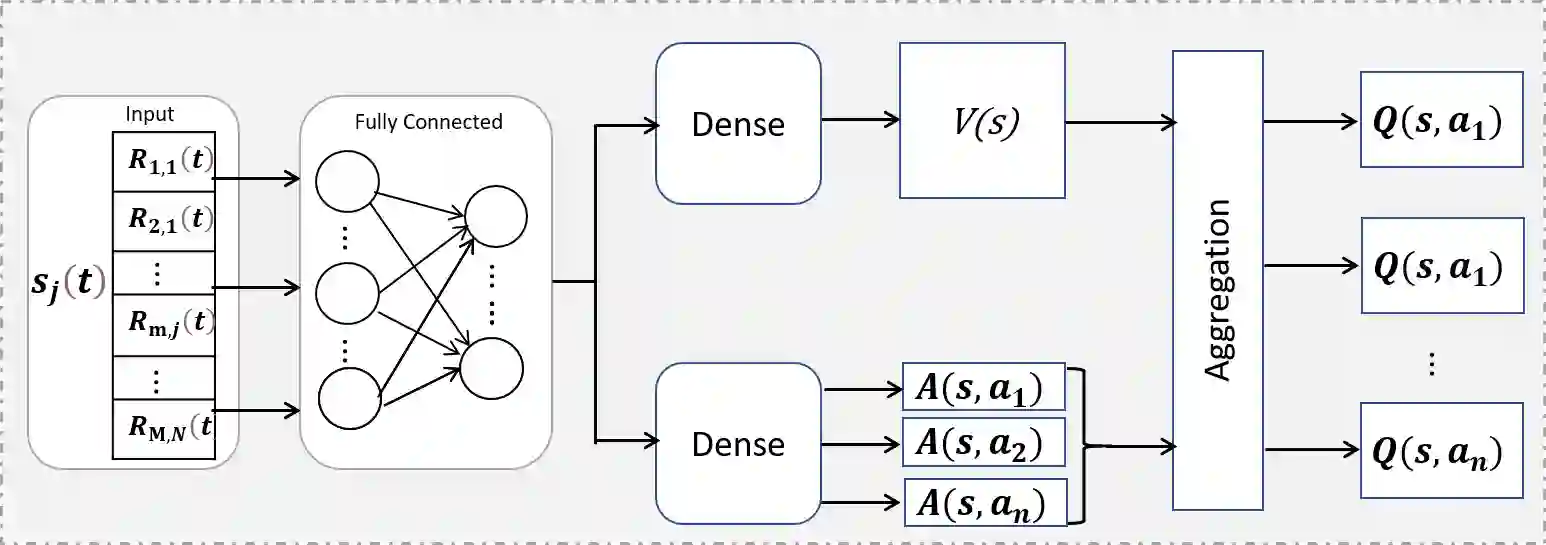
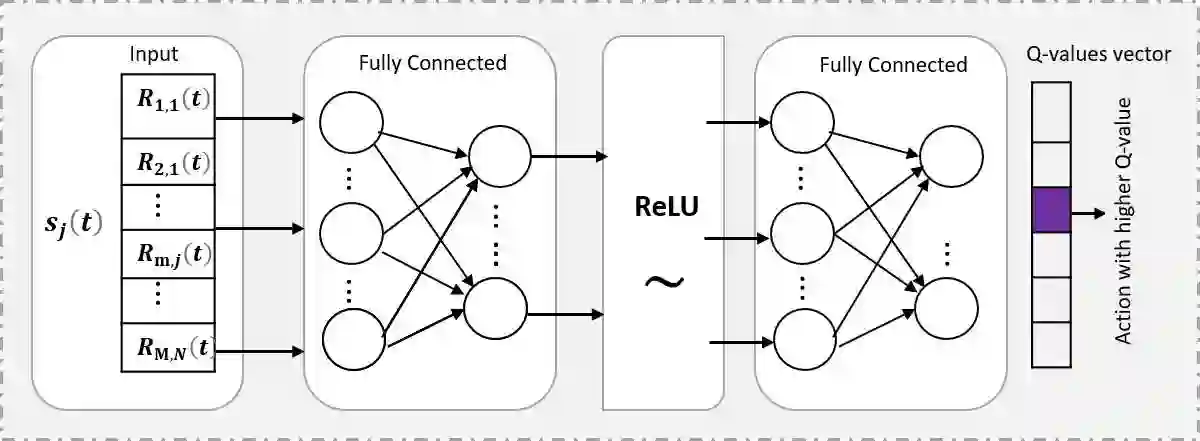
In this paper, we generate a transmit power pool (PP) for Internet of things (IoT) networks with semi-grant-free non-orthogonal multiple access (SGF-NOMA) via multi-agent deep reinforcement learning (MA-DRL) to enable open loop power control (PC). The PP is mapped with each resource block (RB) to achieve distributed power control (DPC). We first formulate the resource allocation problem as stochastic Markov game, and then solve it using two MA-DRL algorithms, namely double deep Q network (DDQN) and Dueling DDQN. Each GF user as an agent tries to find out the optimal transmit power level and RB to form the desired PP. With the aid of dueling processes, the learning process can be enhanced by evaluating the valuable state without considering the effect of each action at each state. Therefore, DDQN is designed for communication scenarios with a small-size action-state space, while Dueling DDQN is for a large-size case. Moreover, to decrease the training time, we reduce the action space by eliminating invalid actions. To control the interference and guarantee the quality-of-service requirements of grant-based users, we determine the optimal number of GF users for each sub-channel. We show that the PC approach has a strong impact on data rates of both grant-based and GF users. We demonstrate that the proposed algorithm is computationally scalable to large-scale IoT networks and produce minimal signalling overhead. Our results show that the proposed MA-Dueling DDQN based SGF-NOMA with DPC outperforms the existing SGF-NOMA system and networks with pure GF protocols with 17.5\% and 22.2\% gain in terms of the system throughput, respectively. Finally, we show that our proposed algorithm outperforms the conventional open loop PC mechanism.
翻译:在本文中,我们通过多剂深层强化学习(MA-DRL),为互联网(IOT)网络生成一个传输电源库(PP),通过多剂深度强化学习(SGF-NOMA),为开放环状电源控制(PC)。PP与每个资源块(RB)一起绘制,以实现分散电源控制(DPC)。我们首先将资源分配问题设计成一个小游戏,然后使用两个MA-DRL算法来解决,即双倍深度Q网络(DDQN)和配对DDQN。每个GF用户作为代理试图找到最佳传输电源水平和RB以形成理想的PPPP。在配对程序的帮助下,可以通过评估每个资源块块(RB)实现分散电源控制(DPC)来增强学习进程。因此,DDQN是设计一个小规模行动空间的通信场景,而DDQN则是用大型的配置,而DQN则用双倍的量最小的Q(DQN)算法。此外,我们减少了培训时间,我们减少了行动空间,通过消除了22个用户的电路段的信号速度,从而展示了S-RFDMA的信号的每个用户的进度。