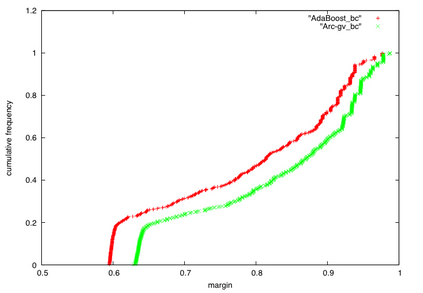
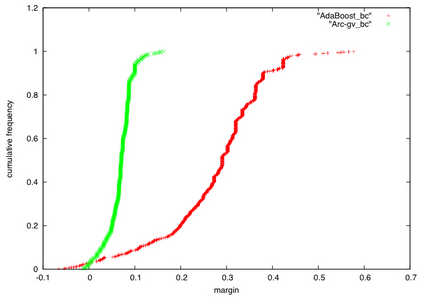
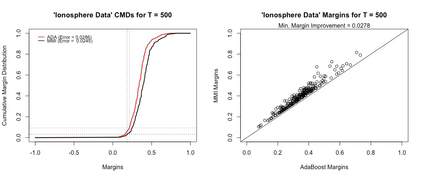
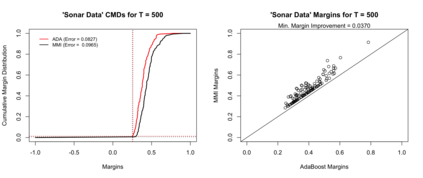
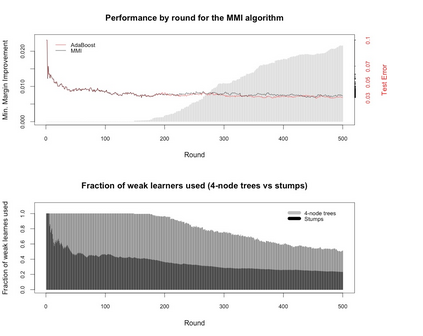
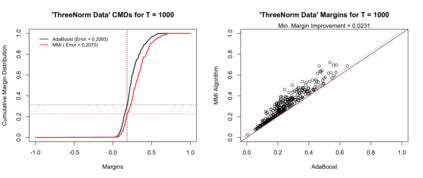
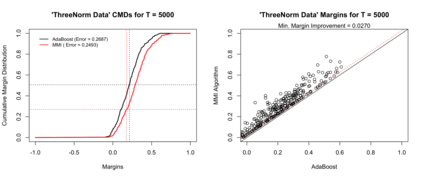
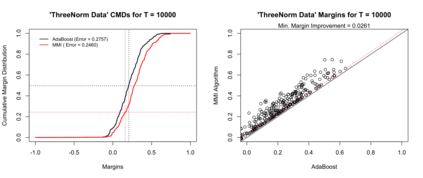
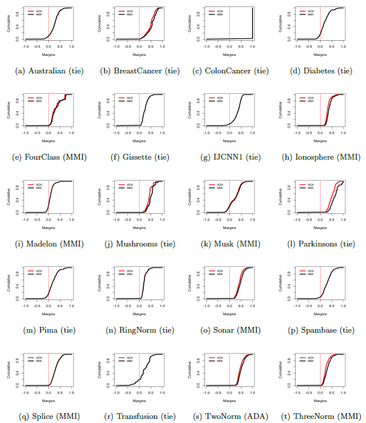
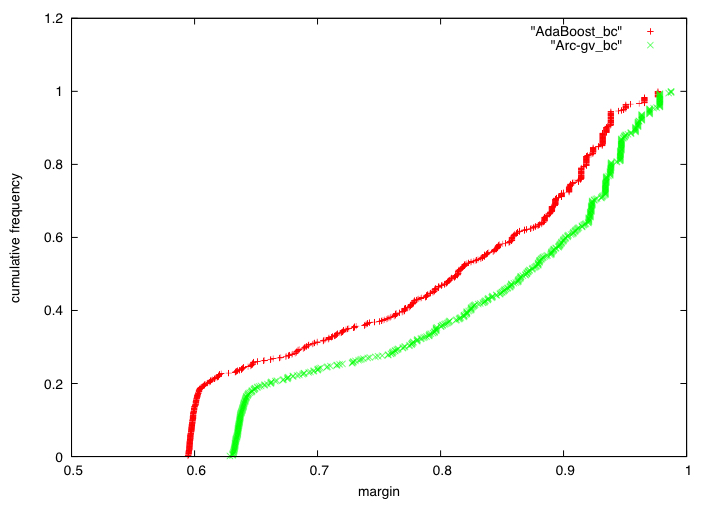
Boosting and other ensemble methods combine a large number of weak classifiers through weighted voting to produce stronger predictive models. To explain the successful performance of boosting algorithms, Schapire et al. (1998) showed that AdaBoost is especially effective at increasing the margins of the training data. Schapire et al. (1998) also developed an upper bound on the generalization error of any ensemble based on the margins of the training data, from which it was concluded that larger margins should lead to lower generalization error, everything else being equal (sometimes referred to as the ``large margins theory''). Tighter bounds have been derived and have reinforced the large margins theory hypothesis. For instance, Wang et al. (2011) suggest that specific margin instances, such as the equilibrium margin, can better summarize the margins distribution. These results have led many researchers to consider direct optimization of the margins to improve ensemble generalization error with mixed results. We show that the large margins theory is not sufficient for explaining the performance of voting classifiers. We do this by illustrating how it is possible to improve upon the margin distribution of an ensemble solution, while keeping the complexity fixed, yet not improve the test set performance.
翻译:通过加权表决,将大量薄弱的分类方法与其他混合方法结合起来,通过加权表决,将大量薄弱的分类方法结合起来,从而产生更强的预测模型。为了解释推算算算法的成功性,Schapire等人(1998年)表明,AdaBoost在增加培训数据的边际方面特别有效。Schapire等人(1998年)还根据培训数据的边际,就任何组合的概括性错误形成了上层界限,由此得出的结论是,较大的边际应导致降低一般化错误,所有其它地方都应相同(有时称为“大边际理论”)。已经得出了更近的界限,加强了大边际理论假设。例如,Wang等人(2011年)建议,特定的边际实例,例如平衡边际,可以更好地总结边际分布。这些结果促使许多研究人员考虑直接优化边际,以改进混合结果的堆积性一般化错误。我们证明,大边际理论不足以解释投票分级者的绩效。我们这样做是通过说明如何改进边际分配,而不是改进复杂性测试。