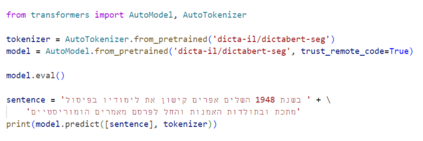
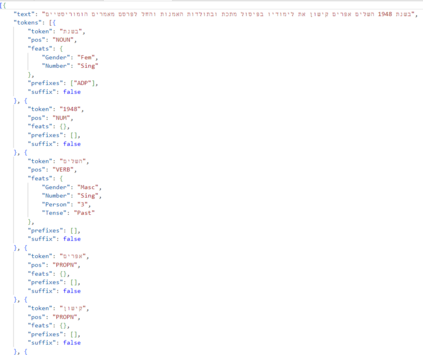
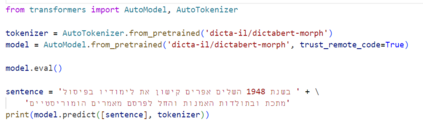
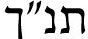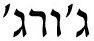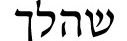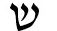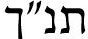We present DictaBERT, a new state-of-the-art pre-trained BERT model for modern Hebrew, outperforming existing models on most benchmarks. Additionally, we release three fine-tuned versions of the model, designed to perform three specific foundational tasks in the analysis of Hebrew texts: prefix segmentation, morphological tagging and question answering. These fine-tuned models allow any developer to perform prefix segmentation, morphological tagging and question answering of a Hebrew input with a single call to a HuggingFace model, without the need to integrate any additional libraries or code. In this paper we describe the details of the training as well and the results on the different benchmarks. We release the models to the community, along with sample code demonstrating their use. We release these models as part of our goal to help further research and development in Hebrew NLP.
翻译:暂无翻译