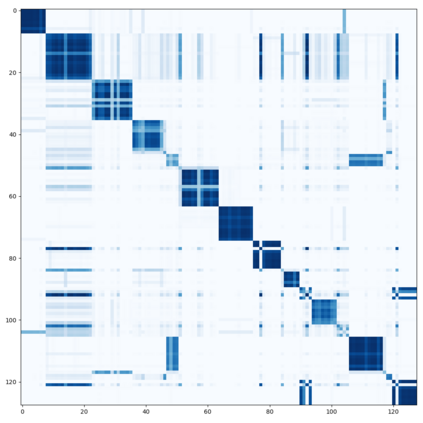
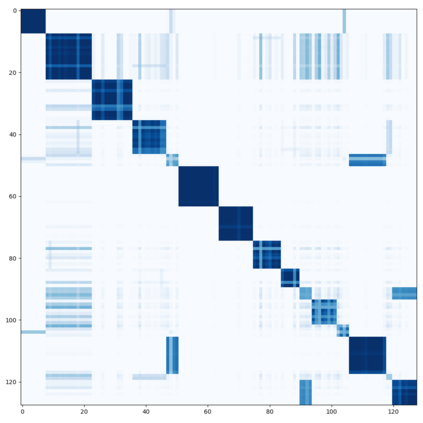
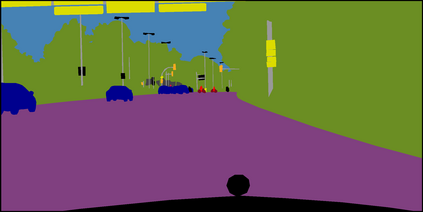
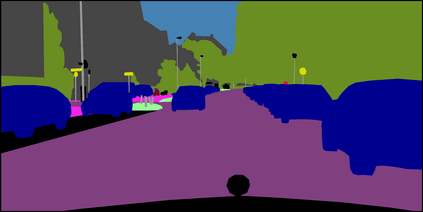
Semi-supervised semantic segmentation needs rich and robust supervision on unlabeled data. Consistency learning enforces the same pixel to have similar features in different augmented views, which is a robust signal but neglects relationships with other pixels. In comparison, contrastive learning considers rich pairwise relationships, but it can be a conundrum to assign binary positive-negative supervision signals for pixel pairs. In this paper, we take the best of both worlds and propose multi-view correlation consistency (MVCC) learning: it considers rich pairwise relationships in self-correlation matrices and matches them across views to provide robust supervision. Together with this correlation consistency loss, we propose a view-coherent data augmentation strategy that guarantees pixel-pixel correspondence between different views. In a series of semi-supervised settings on two datasets, we report competitive accuracy compared with the state-of-the-art methods. Notably, on Cityscapes, we achieve 76.8% mIoU with 1/8 labeled data, just 0.6% shy from the fully supervised oracle.
翻译:半监督的语义分解需要丰富和对未贴标签的数据进行严格的监督。 一致的学习在不同的扩展视图中执行相同的像素, 以具有相似的特性, 这是一种强大的信号, 但忽略了与其他像素的关系。 相比之下, 对比式的学习会考虑丰富的双向关系, 但对于给像素配对配配配双色的半监督性监督信号来说, 这可能是个难题。 在本文中, 我们采用两种世界的最佳方法, 并提议多视角的关联一致性( MVCC) 学习 : 它会考虑自我对称矩阵中的丰富对称关系, 并匹配它们来提供强有力的监督。 再加上这种关联性的一致性损失, 我们提议了一个视觉相近的数据增强战略, 保证不同观点之间的像素- 像素对应。 在两个数据集上的一系列半监督的设置中, 我们报告与最新技术方法相比具有竞争性的准确性。 值得注意的是, 在城市景象上, 我们实现了76. 8% mIOU, 1/8的标签数据为1/8, 仅0.6% 害于完全监控的 。