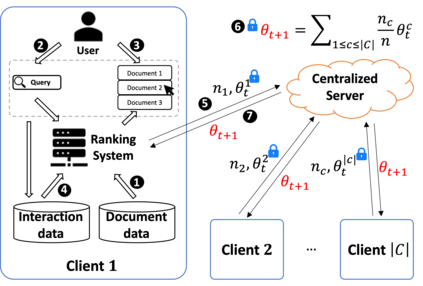
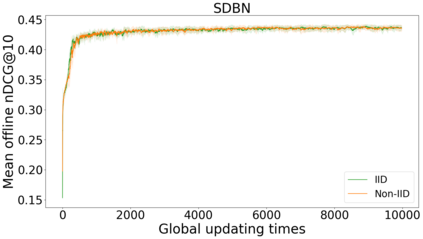
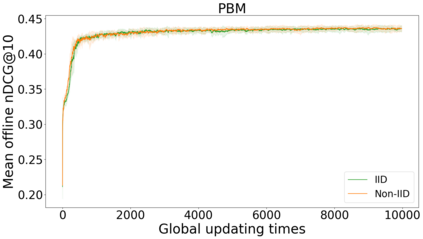
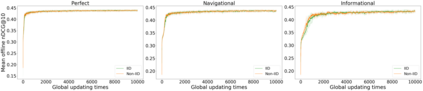
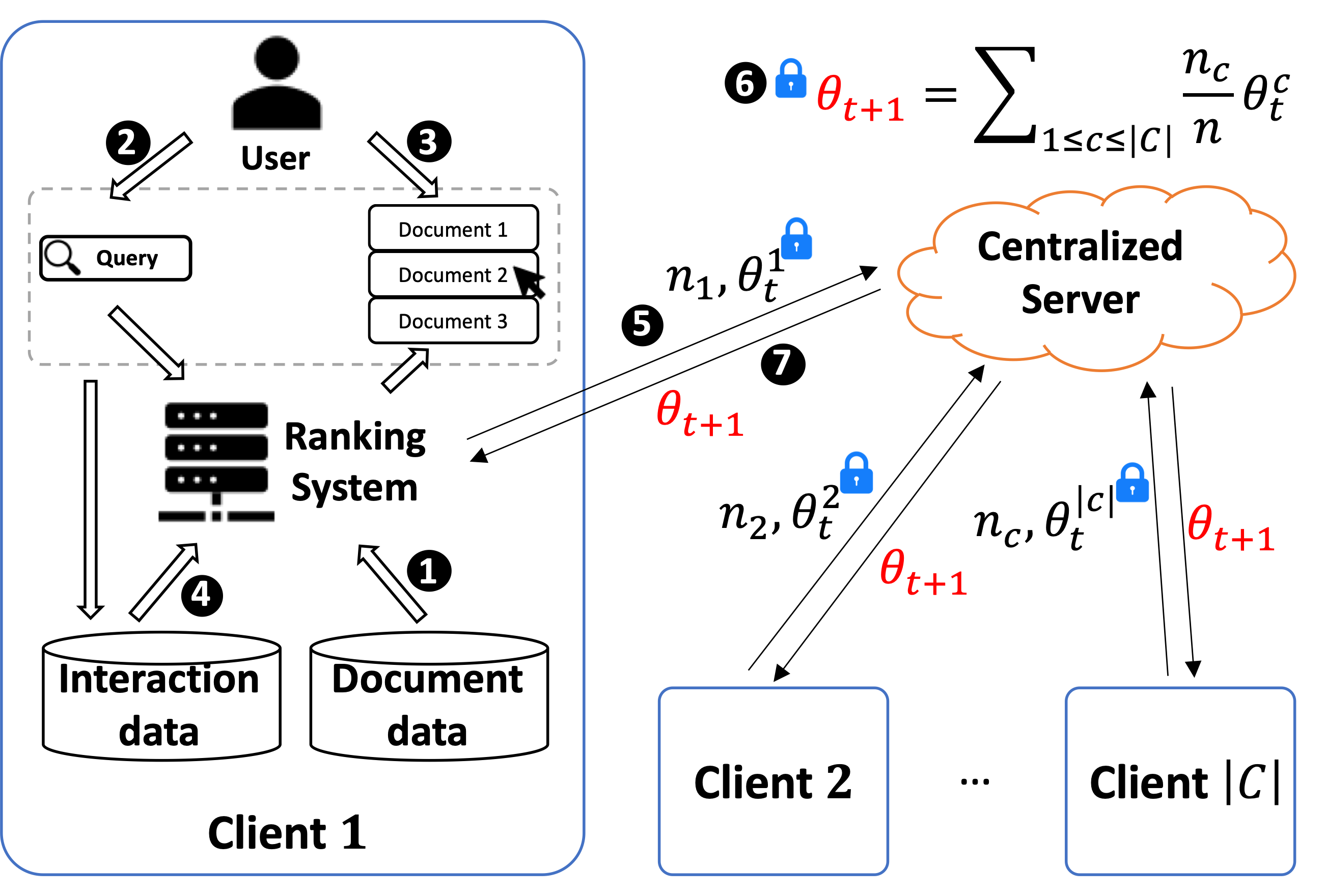
In this perspective paper we study the effect of non independent and identically distributed (non-IID) data on federated online learning to rank (FOLTR) and chart directions for future work in this new and largely unexplored research area of Information Retrieval. In the FOLTR process, clients participate in a federation to jointly create an effective ranker from the implicit click signal originating in each client, without the need to share data (documents, queries, clicks). A well-known factor that affects the performance of federated learning systems, and that poses serious challenges to these approaches, is that there may be some type of bias in the way data is distributed across clients. While FOLTR systems are on their own rights a type of federated learning system, the presence and effect of non-IID data in FOLTR has not been studied. To this aim, we first enumerate possible data distribution settings that may showcase data bias across clients and thus give rise to the non-IID problem. Then, we study the impact of each setting on the performance of the current state-of-the-art FOLTR approach, the Federated Pairwise Differentiable Gradient Descent (FPDGD), and we highlight which data distributions may pose a problem for FOLTR methods. We also explore how common approaches proposed in the federated learning literature address non-IID issues in FOLTR. This allows us to unveil new research gaps that, we argue, future research in FOLTR should consider. This is an important contribution to the current state of FOLTR field because, for FOLTR systems to be deployed, the factors affecting their performance, including the impact of non-IID data, need to be thoroughly understood.
翻译:在本观点文件中,我们研究了非独立和同样分发的(非IID)在线数据对联合在线学习的影响(FOLTR)和在信息检索新领域(信息检索新领域)未来工作的图表方向。在FOLTR进程中,客户参与一个联合会,共同从来自每个客户的隐性点击信号中创建有效的排名器,无需分享数据(文件、查询、点击),影响联合学习系统业绩的一个众所周知的因素,给这些方法带来严重挑战,这就是数据在客户之间分配方式上可能存在某种偏差。虽然FOLTRTR系统在自己的权利上是一种联合学习系统,但在FOLTRTR研究领域,非II系统的存在和影响还没有研究。为了这个目的,我们首先列出可能显示客户之间数据偏差从而引起非IID问题的可能的数据分发环境。 然后,我们研究每个因素对目前水平的TRTRTR工具的绩效的影响,在客户之间分配方式上可能存在某种偏差的偏差。 FOLTRTRTRTRTRII方法,而FOL研究方法在FLFFD中也使得我们未来的研究方法能够进行这样的研究。