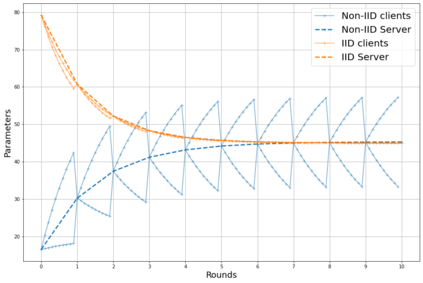
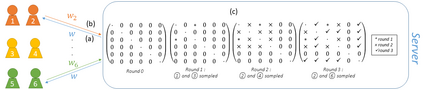
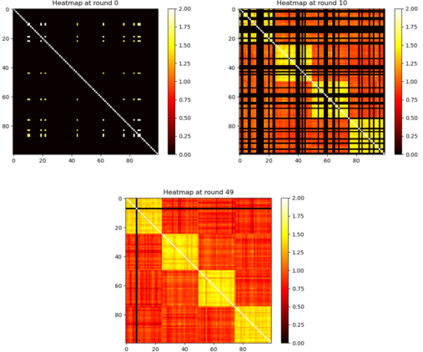
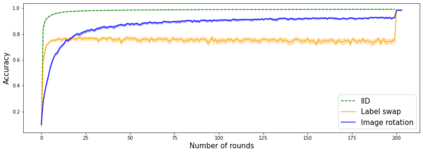
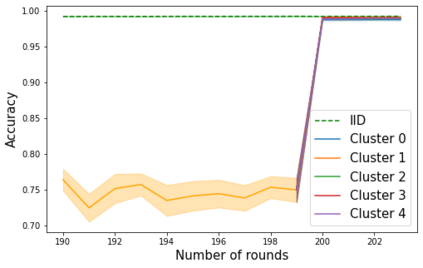
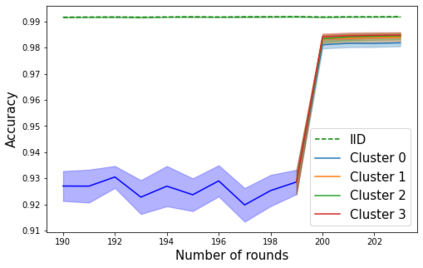
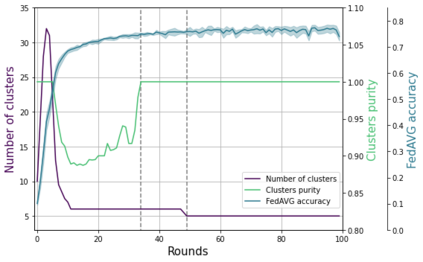
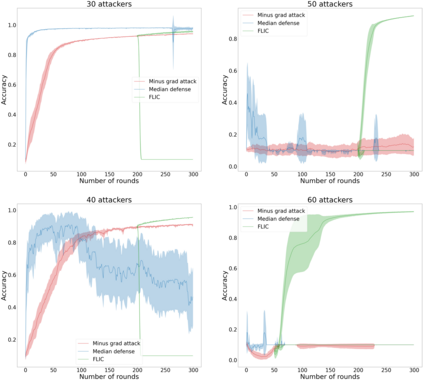
Federated learning enables different parties to collaboratively build a global model under the orchestration of a server while keeping the training data on clients' devices. However, performance is affected when clients have heterogeneous data. To cope with this problem, we assume that despite data heterogeneity, there are groups of clients who have similar data distributions that can be clustered. In previous approaches, in order to cluster clients the server requires clients to send their parameters simultaneously. However, this can be problematic in a context where there is a significant number of participants that may have limited availability. To prevent such a bottleneck, we propose FLIC (Federated Learning with Incremental Clustering), in which the server exploits the updates sent by clients during federated training instead of asking them to send their parameters simultaneously. Hence no additional communications between the server and the clients are necessary other than what classical federated learning requires. We empirically demonstrate for various non-IID cases that our approach successfully splits clients into groups following the same data distributions. We also identify the limitations of FLIC by studying its capability to partition clients at the early stages of the federated learning process efficiently. We further address attacks on models as a form of data heterogeneity and empirically show that FLIC is a robust defense against poisoning attacks even when the proportion of malicious clients is higher than 50\%.
翻译:联邦学习使不同方能够在服务器的协调下合作构建一个全球模型,同时保留客户设备的培训数据。然而,如果客户有不同的数据,业绩就会受到影响。为了解决这一问题,我们假设,尽管数据差异性不同,但有些客户群体拥有类似的数据分布,可以将数据分组。在以往的做法中,服务器要求客户同时发送参数,但为了对客户进行分组,服务器要求客户同时发送参数。然而,在大量参与者可能难以获得的情况下,这可能存在问题。为防止出现这种瓶颈,我们提议FLIC(学习递增集群联盟),服务器在这种瓶颈中利用客户在联合培训期间提供的最新信息,而不是要求客户同时发送参数。因此,服务器和客户之间没有必要进行更多的通信,只有传统的联合学习要求。我们从经验上证明,我们的方法成功地将客户按照同样的数据分布成功地分成群体。我们通过研究其在联邦更高学习过程早期对客户进行分割的能力,从而发现FLIC的局限性。我们进一步将50级的战前防御模式视为一种可靠的模型,而当他对50级的战前战时,我们又将50级的战前战时的战前防御模式视为一种可靠的攻击。