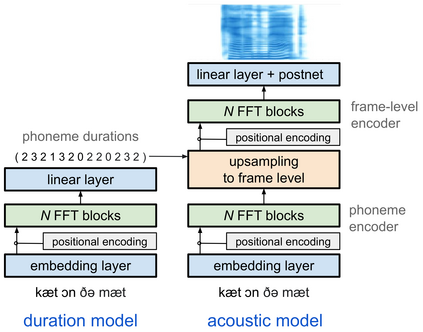
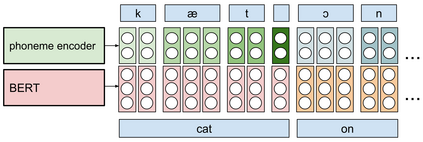
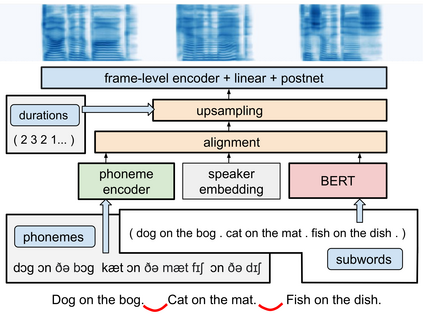
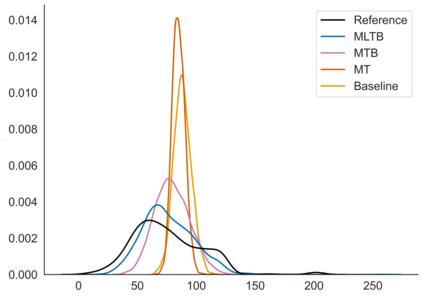
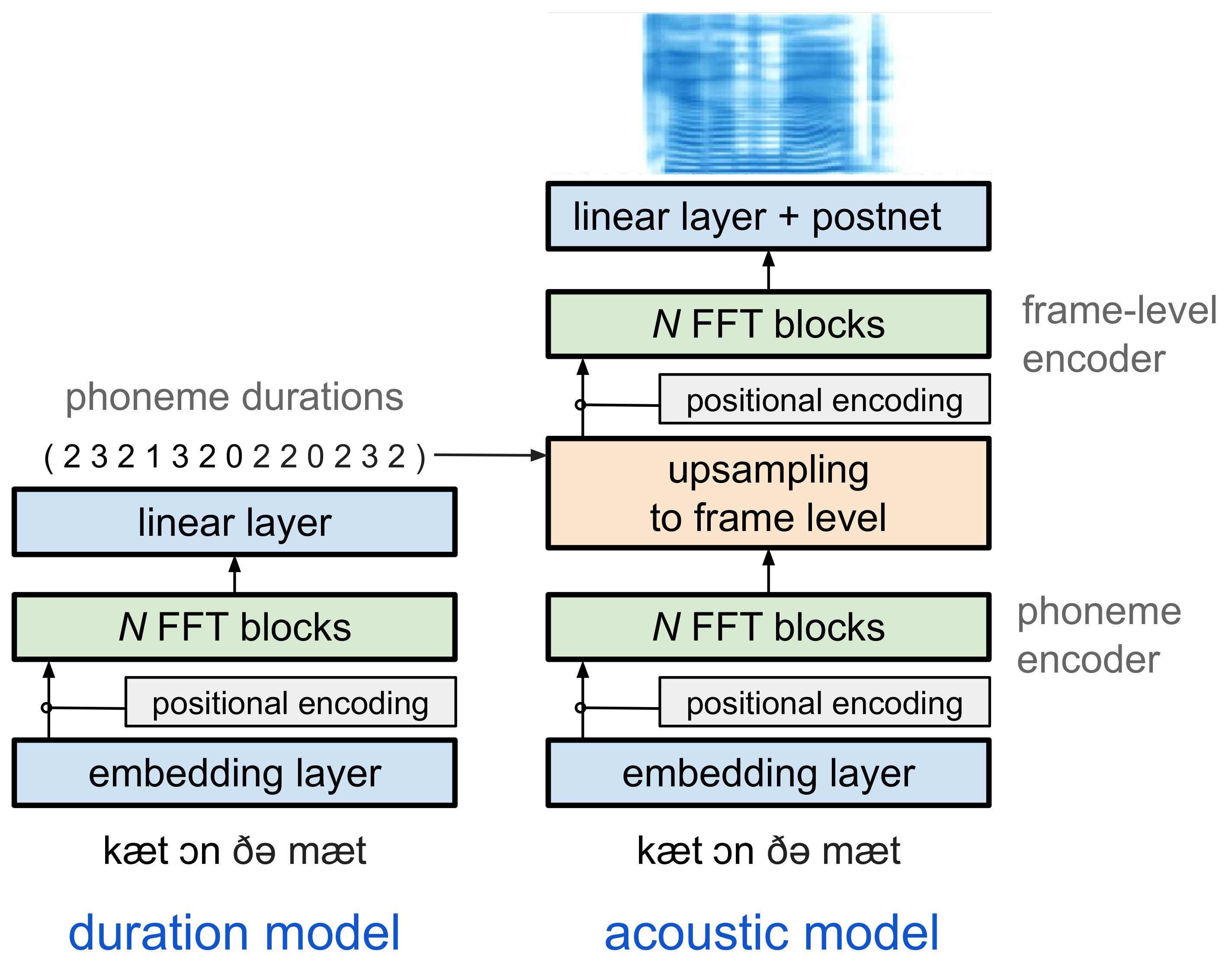
Generating expressive and contextually appropriate prosody remains a challenge for modern text-to-speech (TTS) systems. This is particularly evident for long, multi-sentence inputs. In this paper, we examine simple extensions to a Transformer-based FastSpeech-like system, with the goal of improving prosody for multi-sentence TTS. We find that long context, powerful text features, and training on multi-speaker data all improve prosody. More interestingly, they result in synergies. Long context disambiguates prosody, improves coherence, and plays to the strengths of Transformers. Fine-tuning word-level features from a powerful language model, such as BERT, appears to profit from more training data, readily available in a multi-speaker setting. We look into objective metrics on pausing and pacing and perform thorough subjective evaluations for speech naturalness. Our main system, which incorporates all the extensions, achieves consistently strong results, including statistically significant improvements in speech naturalness over all its competitors.
翻译:对现代文本到语音(TTS)系统来说,产生直截了当和符合背景的偏移仍然是一项挑战。对于长长的多语种投入来说,这一点特别明显。在本文中,我们审视了以变换器为基础的快速语音系统简单的扩展,目的是改进多语种 TTS 的演练。我们发现,长的上下文、强大的文本特征和多语种数据培训都提高了动听能力。更有趣的是,它们产生了协同效应。长的上下文模糊不清,改进了一致性,并发挥了变异器的优势。从强大的语言模型(如BERT)中精微调字级特征似乎得益于在多语种环境中随时可获得的更多培训数据。我们审视了关于发音和速度的客观指标,并对语言自然特性进行了彻底的主观评价。我们的主要系统吸收了所有的扩展,取得了持续有力的成果,包括对所有竞争对手的言语自然性有统计意义的改进。