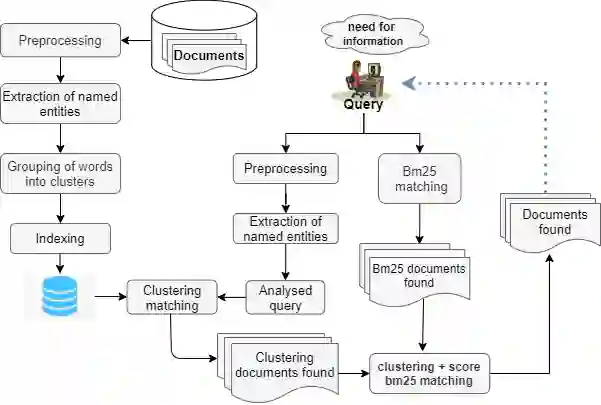
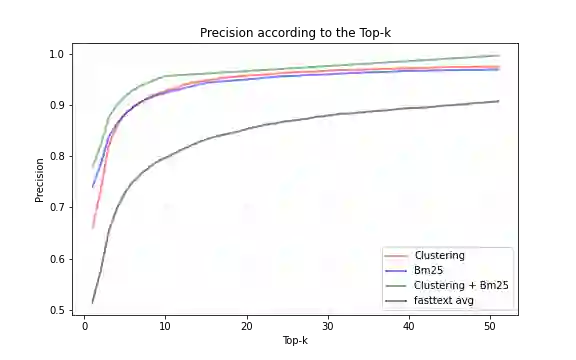
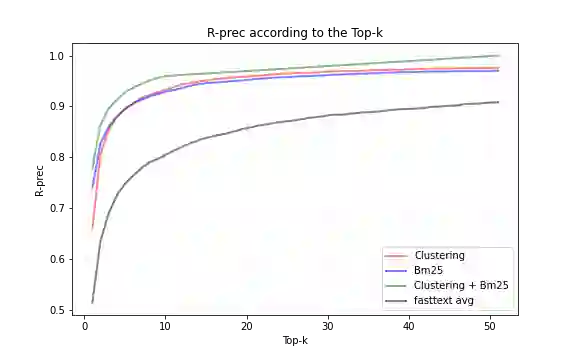
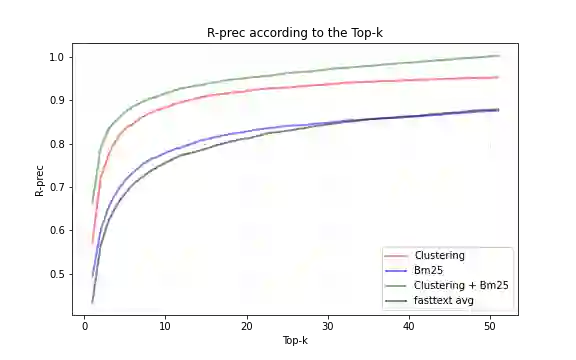
In this paper, we propose an alternative to deep neural networks for semantic information retrieval for the case of long documents. This new approach exploiting clustering techniques to take into account the meaning of words in Information Retrieval systems targeting long as well as short documents. This approach uses a specially designed clustering algorithm to group words with similar meanings into clusters. The dual representation (lexical and semantic) of documents and queries is based on the vector space model proposed by Gerard Salton in the vector space constituted by the formed clusters. The originalities of our proposal are at several levels: first, we propose an efficient algorithm for the construction of clusters of semantically close words using word embedding as input, then we define a formula for weighting these clusters, and then we propose a function allowing to combine efficiently the meanings of words with a lexical model widely used in Information Retrieval. The evaluation of our proposal in three contexts with two different datasets SQuAD and TREC-CAR has shown that is significantly improves the classical approaches only based on the keywords without degrading the lexical aspect.
翻译:在本文中,我们提出一个替代深神经网络的替代办法,用于为长文件进行语义信息检索。这种新办法利用集群技术,以考虑到信息检索系统中长期和简短文档中文字的含义。这种方法使用专门设计的群集算法,将具有类似含义的词组分组成组。文档和查询的双重表述(传统和语义)基于由组成组组成的矢量空间Gerard Salton建议的矢量空间模型。我们提案的原创性存在于几个层面:首先,我们提出一种高效的算法,用于用嵌入文字作为投入来构建语义密切的词组,然后我们界定对这些群群进行加权的公式,然后我们提出一种功能,以便有效地将文字的含义与信息检索中广泛使用的词汇模型结合起来。我们的提案在三个背景下用两个不同的数据集SQuAD和TREC-CAR来评估。我们的提案表明,仅仅根据关键词而不是贬低词的典型方法,我们的提案在三个背景下大大改进了古典方法。