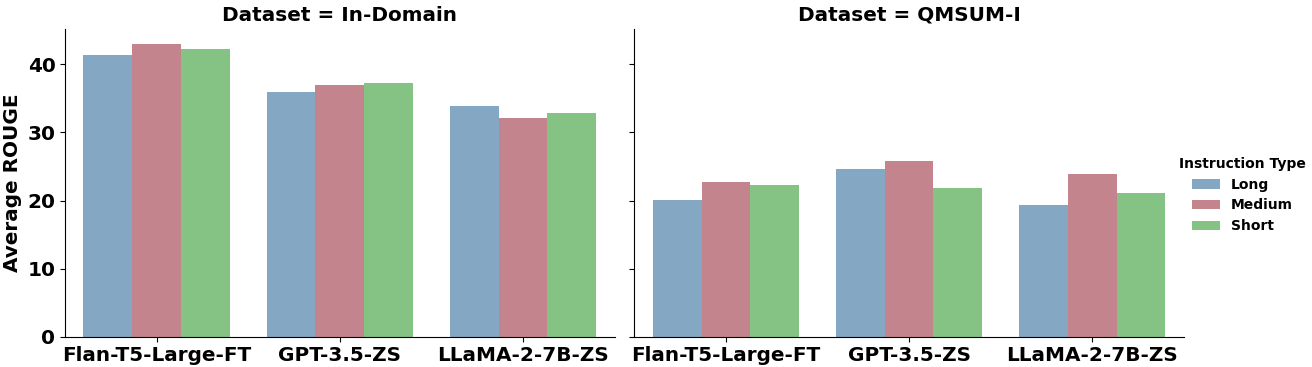
Large Language Models (LLMs) have demonstrated impressive capabilities to solve a wide range of tasks without being explicitly fine-tuned on task-specific datasets. However, deploying LLMs in the real world is not trivial, as it requires substantial computing resources. In this paper, we investigate whether smaller, compact LLMs are a good alternative to the comparatively Larger LLMs2 to address significant costs associated with utilizing LLMs in the real world. In this regard, we study the meeting summarization task in a real-world industrial environment and conduct extensive experiments by comparing the performance of fine-tuned compact LLMs (e.g., FLAN-T5, TinyLLaMA, LiteLLaMA) with zero-shot larger LLMs (e.g., LLaMA-2, GPT-3.5, PaLM-2). We observe that most smaller LLMs, even after fine-tuning, fail to outperform larger zero-shot LLMs in meeting summarization datasets. However, a notable exception is FLAN-T5 (780M parameters), which performs on par or even better than many zero-shot Larger LLMs (from 7B to above 70B parameters), while being significantly smaller. This makes compact LLMs like FLAN-T5 a suitable cost-efficient solution for real-world industrial deployment.
翻译:暂无翻译