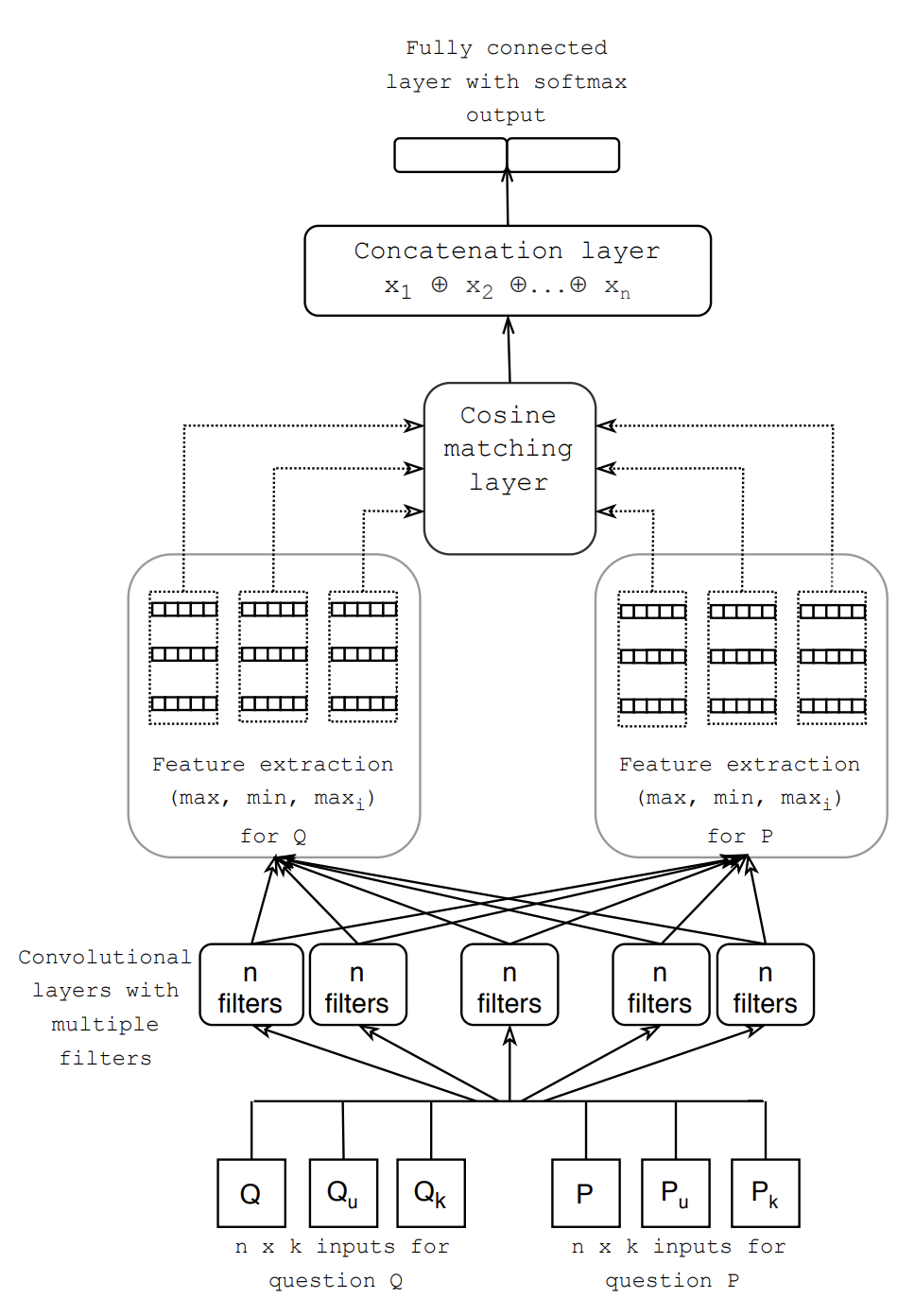
Detecting semantic similarities between sentences is still a challenge today due to the ambiguity of natural languages. In this work, we propose a simple approach to identifying semantically similar questions by combining the strengths of word embeddings and Convolutional Neural Networks (CNNs). In addition, we demonstrate how the cosine similarity metric can be used to effectively compare feature vectors. Our network is trained on the Quora dataset, which contains over 400k question pairs. We experiment with different embedding approaches such as Word2Vec, Fasttext, and Doc2Vec and investigate the effects these approaches have on model performance. Our model achieves competitive results on the Quora dataset and complements the well-established evidence that CNNs can be utilized for paraphrase detection tasks.
翻译:今天,由于自然语言的模糊性,检测判决之间的语义相似性仍然是一项挑战。在这项工作中,我们提出一个简单的方法,通过将单词嵌入和进化神经网络(CNNs)的长处结合起来,找出语义相似的问题。此外,我们演示如何使用共生相似性衡量标准来有效地比较特质矢量。我们的网络接受Quora数据集培训,该数据集包含400多条问题配对。我们实验了Word2Vec、快速文本和Doc2Vec等不同嵌入方法,并调查这些方法对模型性能的影响。我们的模型在Quora数据集上取得了竞争性结果,并补充了CNN可用于参数探测任务的既定证据。