
教程题目:Neural Vector Representations beyond Words: Sentence and Document Embeddings
教程简介:
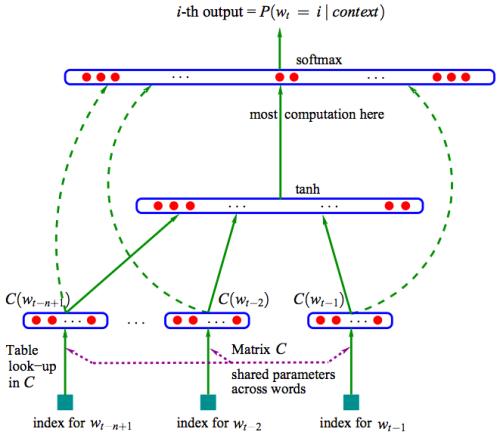
虽然word2vec和GloVe生成的词嵌入被广泛认为是处理文本数据的一种简单方法,但最近在改进产生更好嵌入的方法方面取得了重大进展。特别是人们可能希望归纳出神经向量不仅表示单个单词,而且表示更长的语言单位,包括:多单词短语、整个句子甚至完整的文档。这些设置的算法可以利用大型语料库,但也可以利用其他类型数据的监督,如文档标签、词汇资源或自然语言推理数据集。句子嵌入是特别有趣的,因为它们可能需要适当地解释整个相当相似的句子之间相当微妙的区别。此外,还开发了新的技术来开发多语言和跨语言设置的嵌入式。因此,本教程将概述最新的最先进的方法,这些方法超越了word2vec,并且更好地对更长的单元(例如句子和文档)的语义进行建模,包括单语和跨语言的。本教程将首先简单介绍word2vec,以及它与传统分布语义方法之间的关系,因此不需要先验知识。
组织者:
Gerard de Melo是罗格斯大学(Rutgers University)的助理教授,领导着一个研究NLP和人工智能的团队。他已经发表了100多篇论文,在WWW、CIKM、ICGL和NAACL VSM研讨会上获得了最佳论文/演示奖。
成为VIP会员查看完整内容

相关内容
专知会员服务
24+阅读 · 2019年11月20日
专知会员服务
80+阅读 · 2019年11月5日
Arxiv
7+阅读 · 2018年1月8日
相关主题



相关VIP内容
专知会员服务
24+阅读 · 2019年11月20日
专知会员服务
80+阅读 · 2019年11月5日
相关资讯
相关论文
Arxiv
7+阅读 · 2018年1月8日