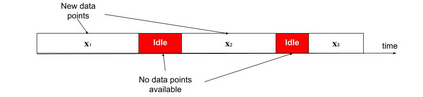
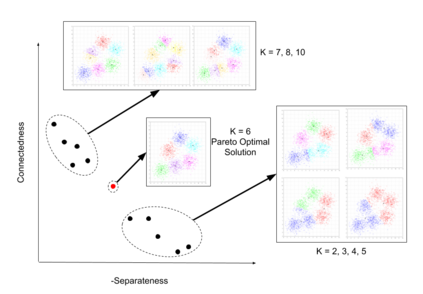
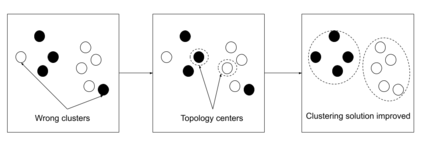
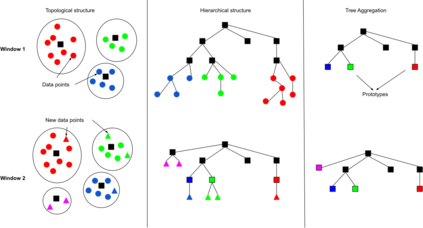
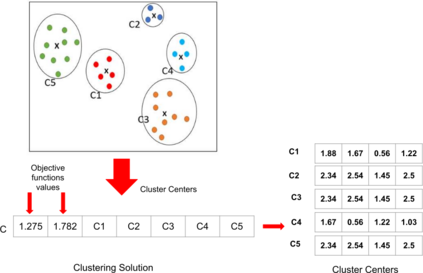
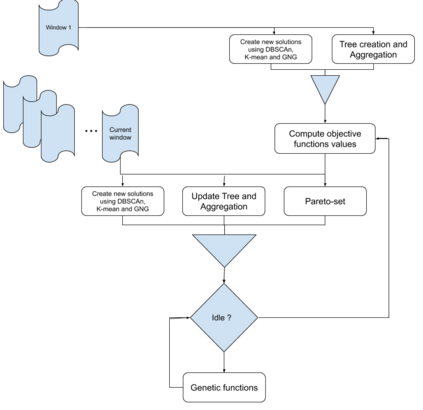
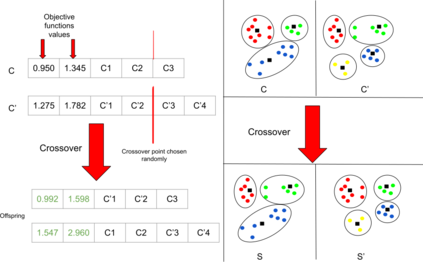
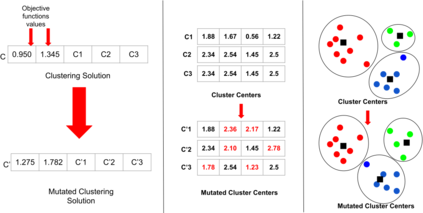
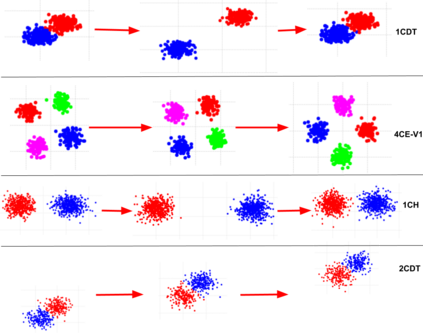
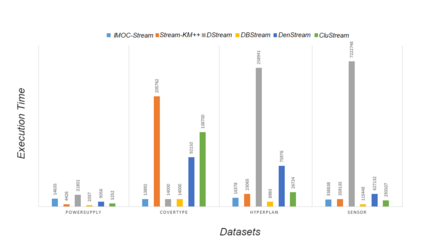
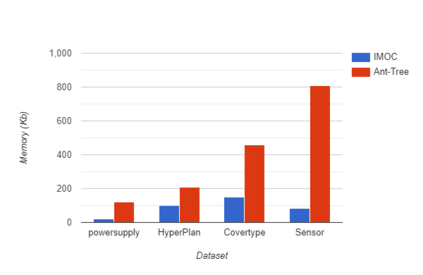
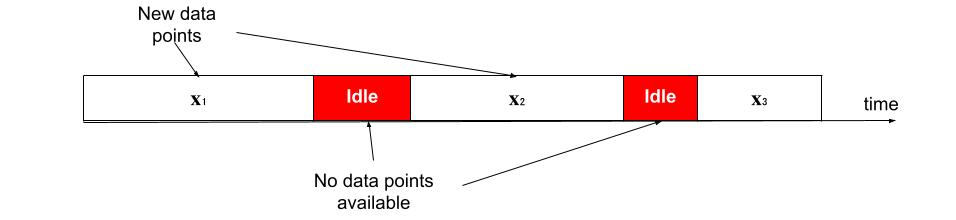
The analysis of data streams has received considerable attention over the past few decades due to sensors, social media, etc. It aims to recognize patterns in an unordered, infinite, and evolving stream of observations. Clustering this type of data requires some restrictions in time and memory. This paper introduces a new data stream clustering method (IMOC-Stream). This method, unlike the other clustering algorithms, uses two different objective functions to capture different aspects of the data. The goal of IMOC-Stream is to: 1) reduce computation time by using idle times to apply genetic operations and enhance the solution. 2) reduce memory allocation by introducing a new tree synopsis. 3) find arbitrarily shaped clusters by using a multi-objective framework. We conducted an experimental study with high dimensional stream datasets and compared them to well-known stream clustering techniques. The experiments show the ability of our method to partition the data stream in arbitrarily shaped, compact, and well-separated clusters while optimizing the time and memory. Our method also outperformed most of the stream algorithms in terms of NMI and ARAND measures.
翻译:过去几十年来,由于传感器、社交媒体等原因,数据流分析受到相当重视。它旨在识别无顺序、无限和不断演变的观测流中的模式。这种类型的数据集群在时间和记忆上需要一些限制。本文件采用了新的数据流群集方法(IMOC-Stream ) 。与其他群集算法不同,这种方法使用两种不同的客观功能来捕捉数据的不同方面。IMOC-Stream的目标是:1)通过使用闲置时间应用基因操作和加强解决方案来缩短计算时间。2)通过引入新的树形概要来减少记忆分配。3)通过使用多目标框架来发现任意形状的群集。我们用高维流数据集进行了实验研究,并将它们与众所周知的流群集技术进行了比较。实验显示了我们的方法在优化时间和记忆的同时将数据流分解成任意形状、紧凑和分离的群集的能力。我们的方法在NMI和ARAND措施方面也超过了大部分流算法。