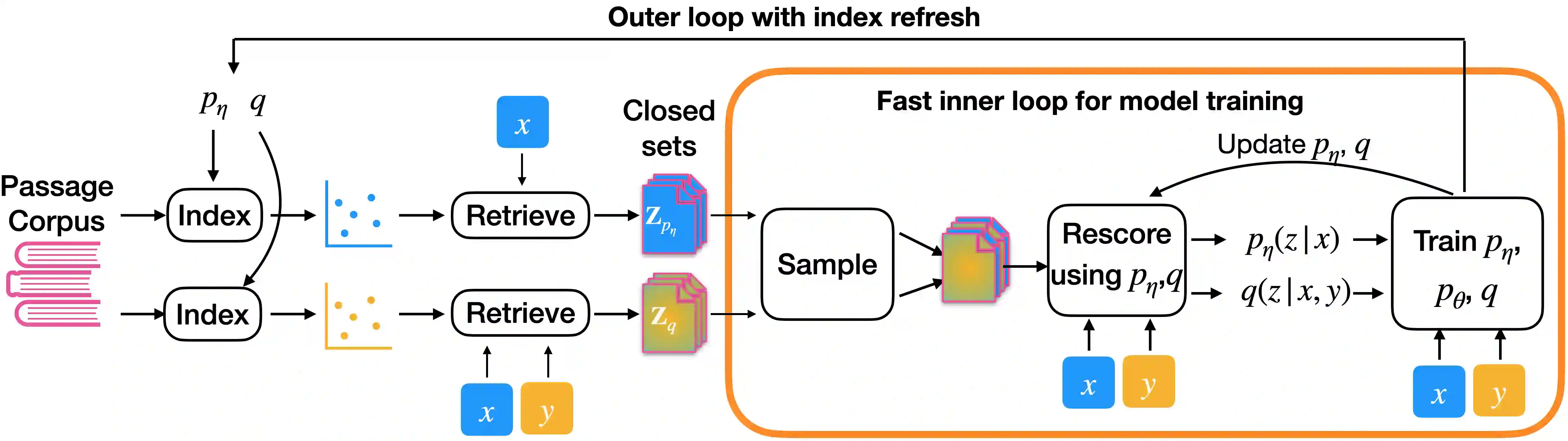
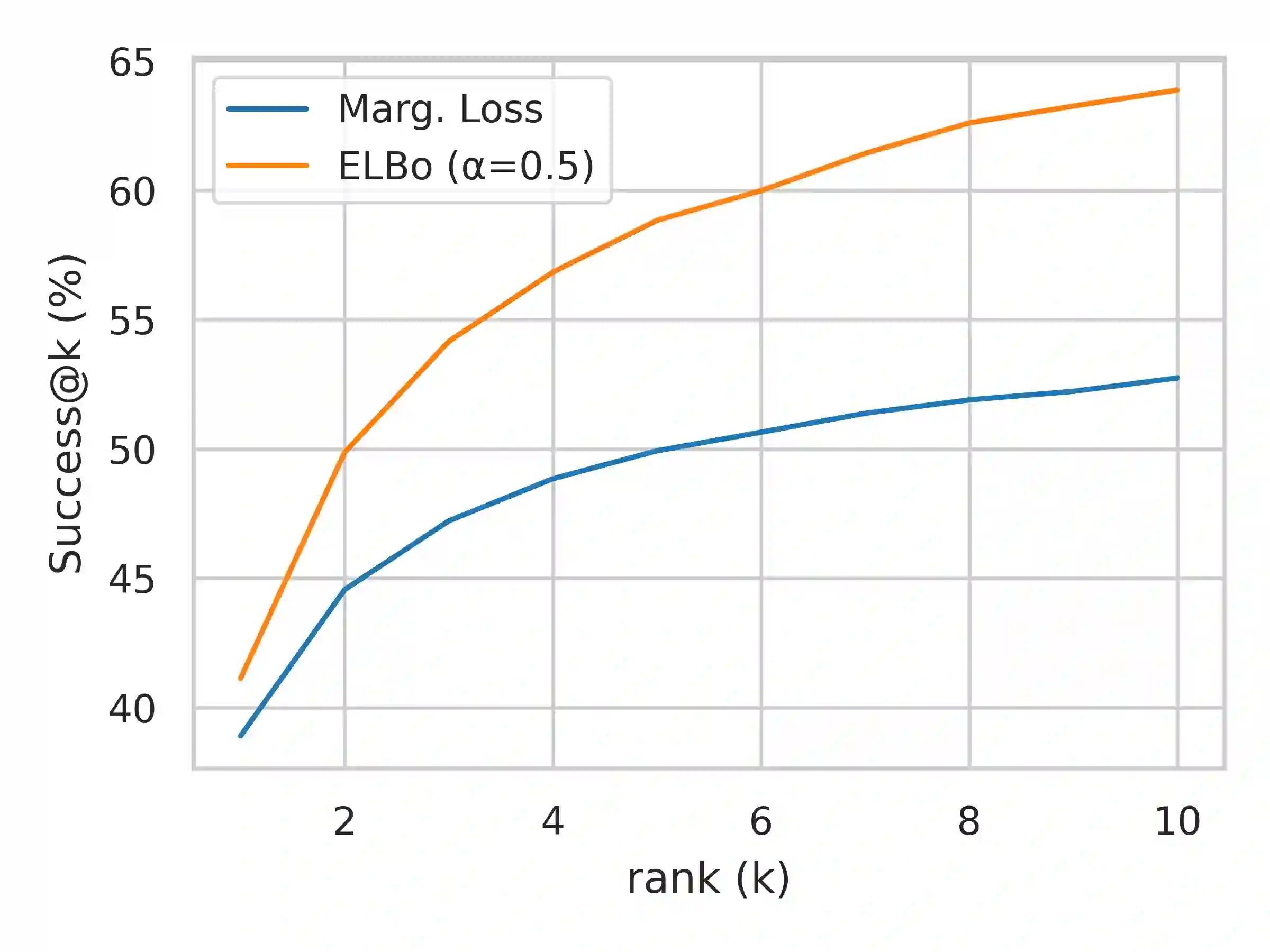
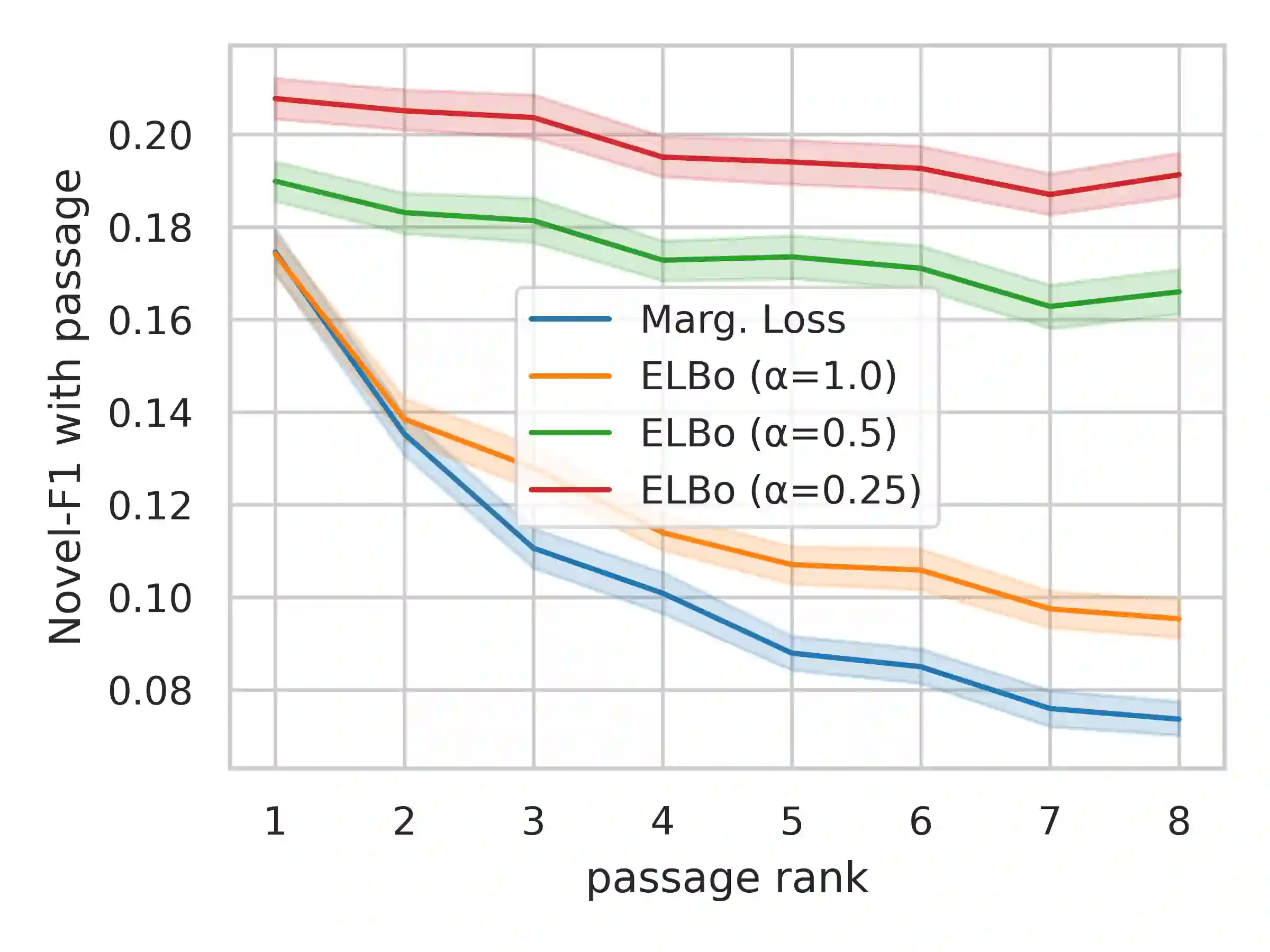
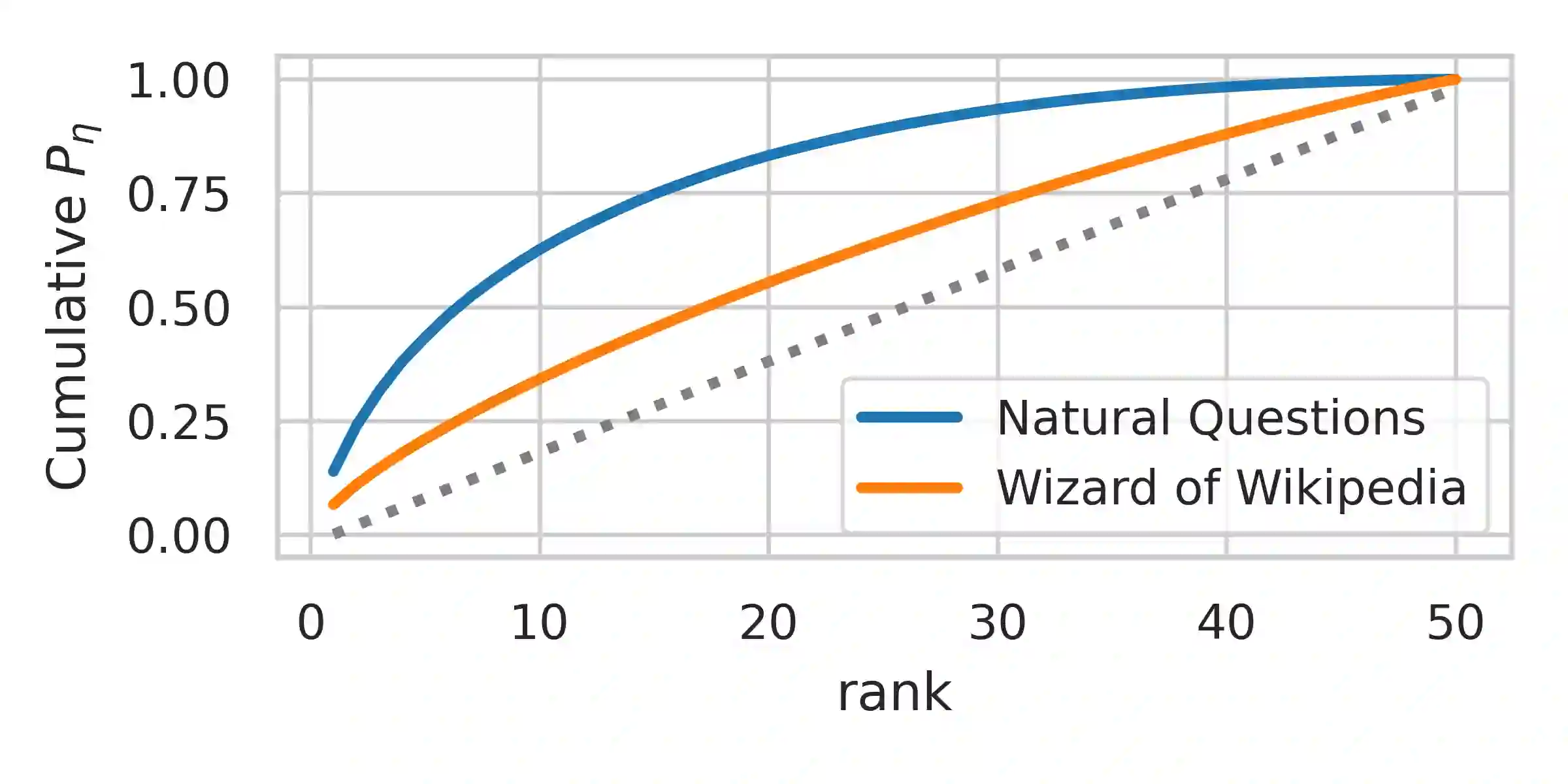
Many text generation systems benefit from using a retriever to retrieve passages from a textual knowledge corpus (e.g., Wikipedia) which are then provided as additional context to the generator. For open-ended generation tasks (like generating informative utterances in conversations) many varied passages may be equally relevant and we find that existing methods that jointly train the retriever and generator underperform: the retriever may not find relevant passages even amongst the top-10 and hence the generator may not learn a preference to ground its generated output in them. We propose using an additional guide retriever that is allowed to use the target output and "in hindsight" retrieve relevant passages during training. We model the guide retriever after the posterior distribution Q of passages given the input and the target output and train it jointly with the standard retriever and the generator by maximizing the evidence lower bound (ELBo) in expectation over Q. For informative conversations from the Wizard of Wikipedia dataset, with posterior-guided training, the retriever finds passages with higher relevance in the top-10 (23% relative improvement), the generator's responses are more grounded in the retrieved passage (19% relative improvement) and the end-to-end system produces better overall output (6.4% relative improvement).
翻译:许多文本生成系统都受益于使用检索器从文本知识堆(例如维基百科)中检索段落,然后作为附加的上下文提供给生成器。对于开放式生成任务(比如在谈话中产生信息化的话语),许多不同段落可能具有同等的相关性,我们发现,联合培训检索器和生成器不完善的现有方法可能具有同等的相关性:检索器可能甚至在前10层中找不到相关通道,因此,生成器可能不会从中学习偏好于将生成的输出置于其中。我们提议使用额外的指南检索器,允许在培训期间使用目标输出和“在后视”检索相关段落。在输入和目标输出的后端分配 Q 之后,我们将指南检索器建模,与标准检索器和生成器联合培训:检索器可能甚至在前10层中找不到相关通道,因此,生成器可能无法从维基百科数据集向导师那里获取信息性谈话,并经过后导培训后,检索器会发现在前10层(23 % 相对改进) 上找到更高相关性的通道。 发电机的反应(19 % 相对改进后路段) 将更接近全面改进。