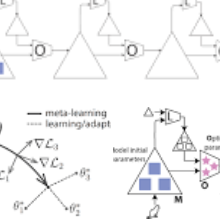
Conventional optimization methods in machine learning and controls rely heavily on first-order update rules. Selecting the right method and hyperparameters for a particular task often involves trial-and-error or practitioner intuition, motivating the field of meta-learning. We generalize a broad family of preexisting update rules by proposing a meta-learning framework in which the inner loop optimization step involves solving a differentiable convex optimization (DCO). We illustrate the theoretical appeal of this approach by showing that it enables one-step optimization of a family of linear least squares problems, given that the meta-learner has sufficient exposure to similar tasks. Various instantiations of the DCO update rule are compared to conventional optimizers on a range of illustrative experimental settings.
翻译:传统的机器学习和控制中的优化方法往往依赖于一阶更新规则。选择特定任务的正确方法和超参数通常涉及试错或者从业者的直觉,因此诞生了元学习领域。我们通过提出一种元学习框架,将现有的广泛更新规则加以推广,其中内循环优化步骤涉及解决一个可微的凸优化问题。我们通过展示这种方法的理论吸引力来说明它的理论成功,给定元学习者有足够的类似任务的实践经验,可以一步优化一类线性最小二乘问题。将DCO更新规则的各种实例与传统优化器在一系列说明性实验设置中进行比较。