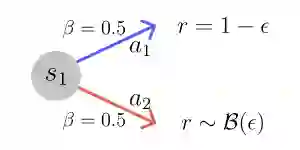
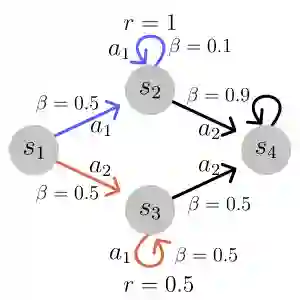
Several recent works have proposed a class of algorithms for the offline reinforcement learning (RL) problem that we will refer to as return-conditioned supervised learning (RCSL). RCSL algorithms learn the distribution of actions conditioned on both the state and the return of the trajectory. Then they define a policy by conditioning on achieving high return. In this paper, we provide a rigorous study of the capabilities and limitations of RCSL, something which is crucially missing in previous work. We find that RCSL returns the optimal policy under a set of assumptions that are stronger than those needed for the more traditional dynamic programming-based algorithms. We provide specific examples of MDPs and datasets that illustrate the necessity of these assumptions and the limits of RCSL. Finally, we present empirical evidence that these limitations will also cause issues in practice by providing illustrative experiments in simple point-mass environments and on datasets from the D4RL benchmark.
翻译:最近的一些著作提出了一套关于离线强化学习(RL)问题的算法,我们称之为返回条件监督学习(RCSL)。RCSL算法学习以状态和轨迹返回为条件的行动分布。然后它们以高回报为条件来界定政策。在本文中,我们对RCSL的能力和局限性进行了严格研究,这是以前工作中关键缺失的。我们发现RCSL在一套假设下返回了最佳政策,这些假设比更传统的动态程序化算法所需要的更强。我们提供了显示这些假设的必要性和RCSL限度的MDP和数据集的具体例子。最后,我们提出经验证据,证明这些限制也会在实践中产生问题,在简单的点质量环境中和D4RL基准的数据集上提供说明性实验。