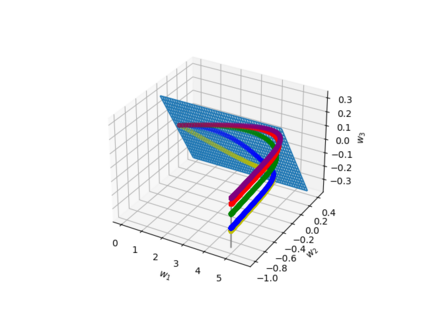
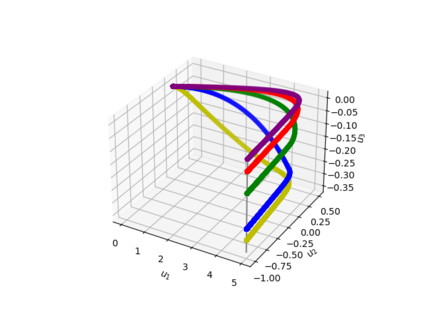
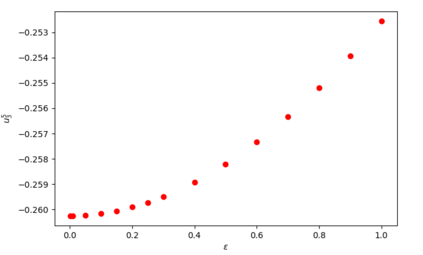
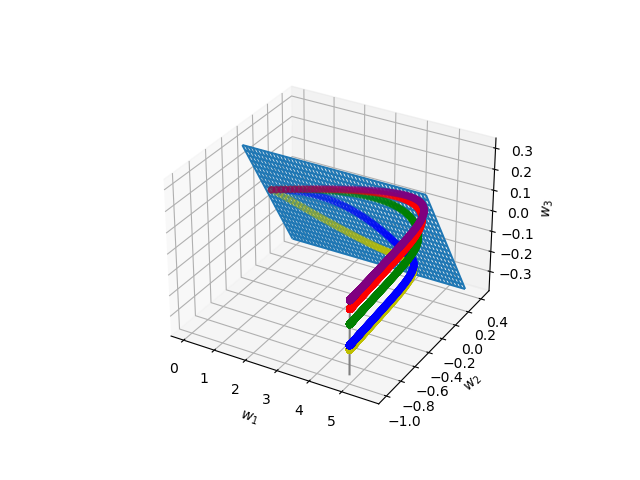
Understanding the implicit regularization (or implicit bias) of gradient descent has recently been a very active research area. However, the implicit regularization in nonlinear neural networks is still poorly understood, especially for regression losses such as the square loss. Perhaps surprisingly, we prove that even for a single ReLU neuron, it is \emph{impossible} to characterize the implicit regularization with the square loss by any explicit function of the model parameters (although on the positive side, we show it can be characterized approximately). For one hidden-layer networks, we prove a similar result, where in general it is impossible to characterize implicit regularization properties in this manner, \emph{except} for the "balancedness" property identified in Du et al. [2018]. Our results suggest that a more general framework than the one considered so far may be needed to understand implicit regularization for nonlinear predictors, and provides some clues on what this framework should be.
翻译:最近一个非常活跃的研究领域是了解梯度下降的隐含正规化(或隐含偏向),然而,非线性神经网络的隐含正规化仍然不甚为人理解,特别是对于回归损失(如平方损失)而言。也许令人惊讶的是,我们证明,即使是单一的RELU神经元,也有必要用模型参数的任何明确功能来将隐含的正规化与平方损失定性(尽管从积极的方面看,我们证明它大致可以定性 ) 。 对于一个隐性网络,我们证明,我们有一个相似的结果,因为一般来说无法以这种方式描述隐含的正规化特性, \ emph{ 除了杜等人([2018年] ) 所指明的“平衡性”财产。 我们的结果表明,可能需要一个比所考虑的范围更宽泛的框架来理解非线性预测器的隐含的正规化,并提供有关这一框架应该是什么的线索。