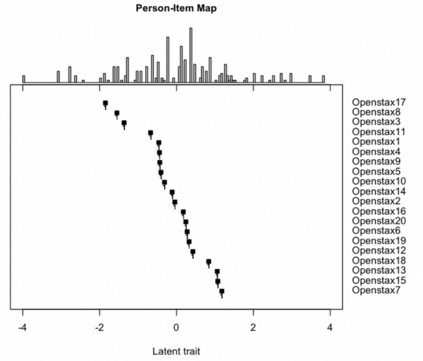
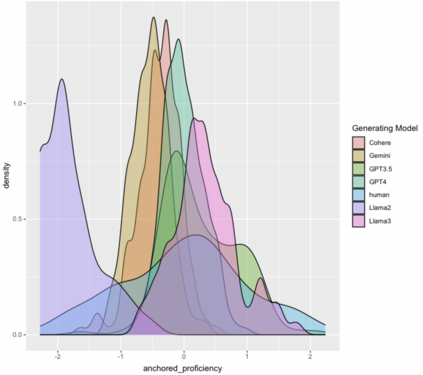
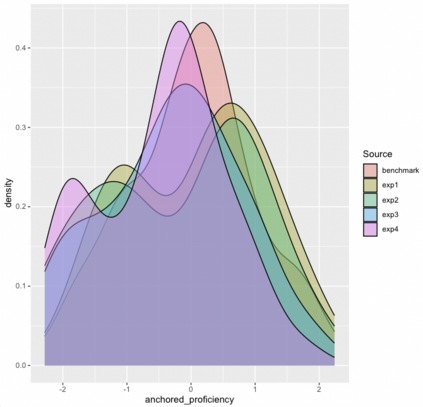
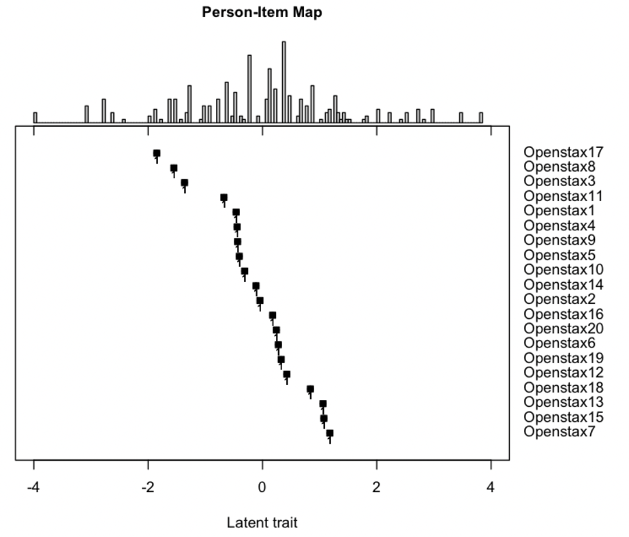
Effective educational measurement relies heavily on the curation of well-designed item pools (i.e., possessing the right psychometric properties). However, item calibration is time-consuming and costly, requiring a sufficient number of respondents for the response process. We explore using six different LLMs (GPT-3.5, GPT-4, Llama 2, Llama 3, Gemini-Pro, and Cohere Command R Plus) and various combinations of them using sampling methods to produce responses with psychometric properties similar to human answers. Results show that some LLMs have comparable or higher proficiency in College Algebra than college students. No single LLM mimics human respondents due to narrow proficiency distributions, but an ensemble of LLMs can better resemble college students' ability distribution. The item parameters calibrated by LLM-Respondents have high correlations (e.g. > 0.8 for GPT-3.5) compared to their human calibrated counterparts, and closely resemble the parameters of the human subset (e.g. 0.02 Spearman correlation difference). Several augmentation strategies are evaluated for their relative performance, with resampling methods proving most effective, enhancing the Spearman correlation from 0.89 (human only) to 0.93 (augmented human).
翻译:暂无翻译