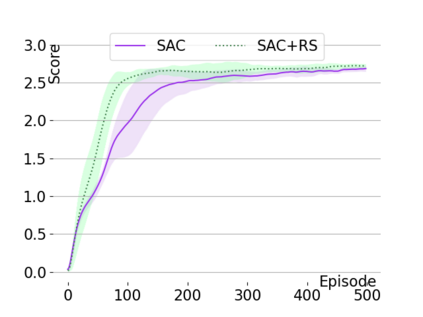
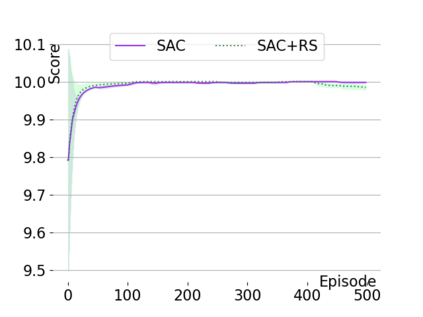
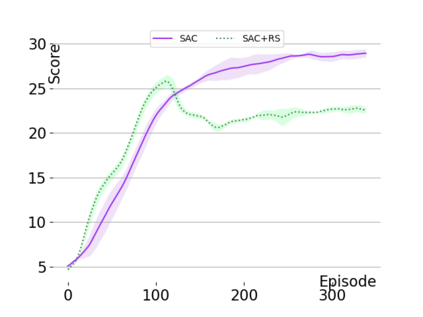
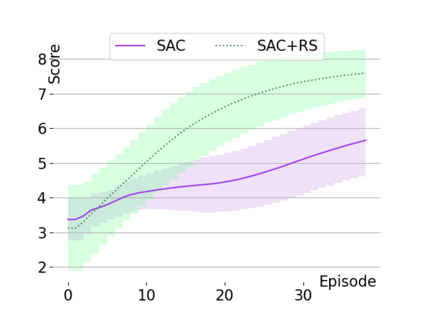
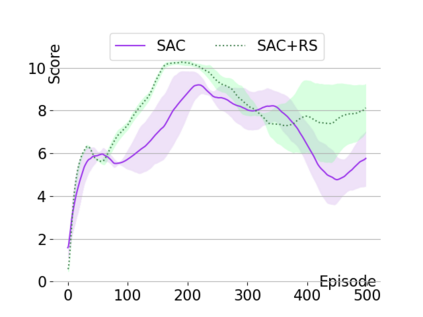
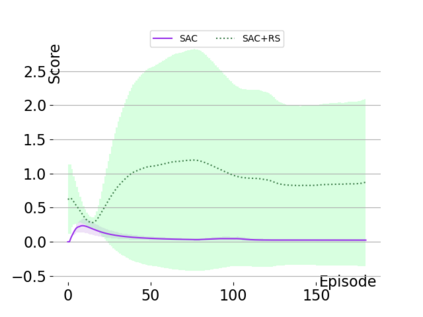
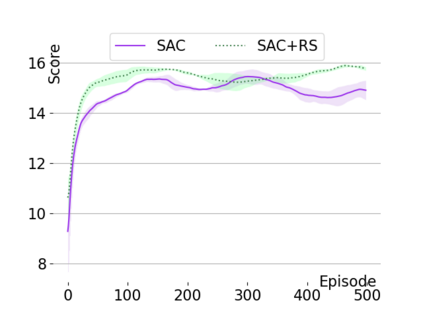
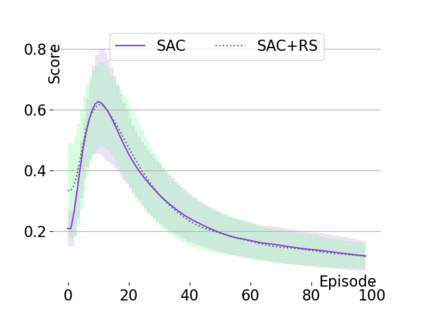
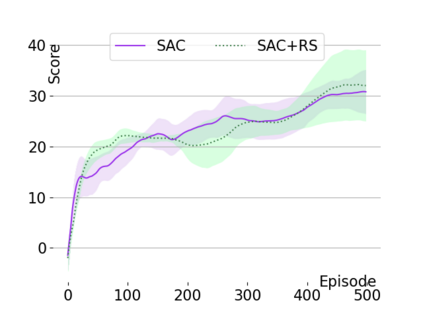
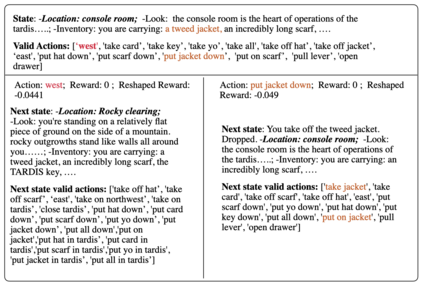
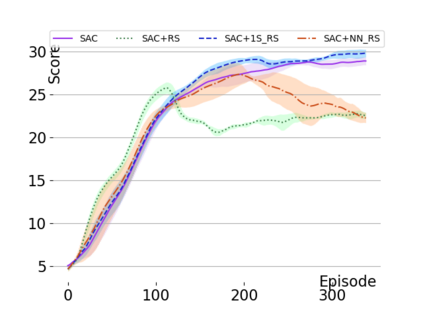
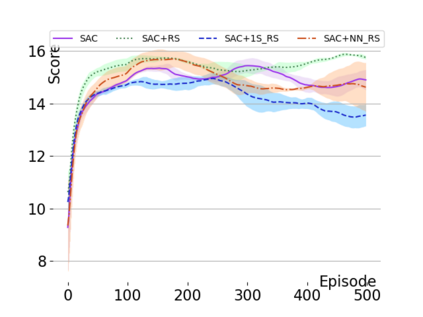
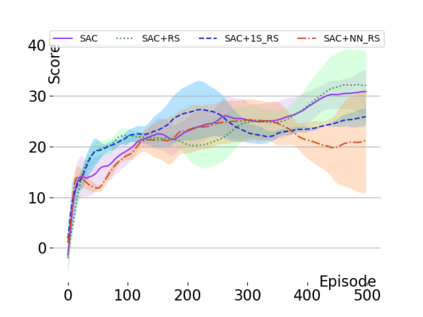
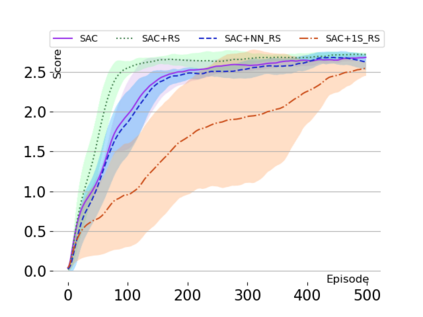
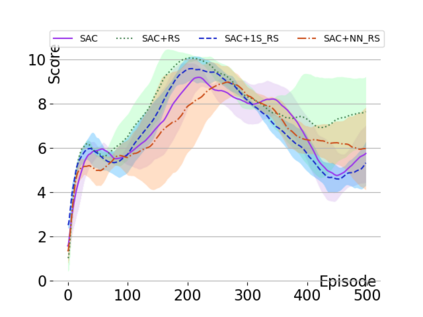
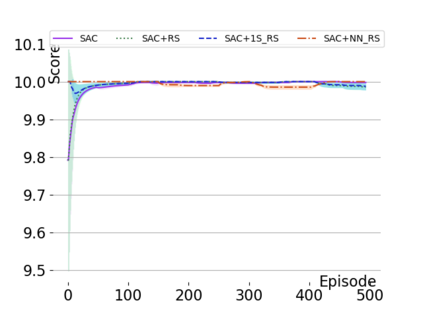
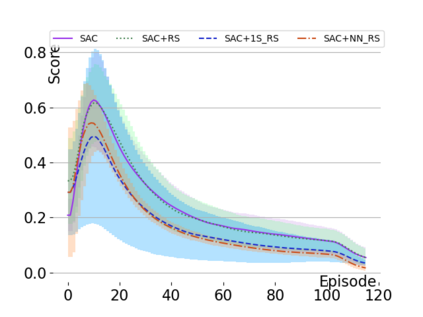
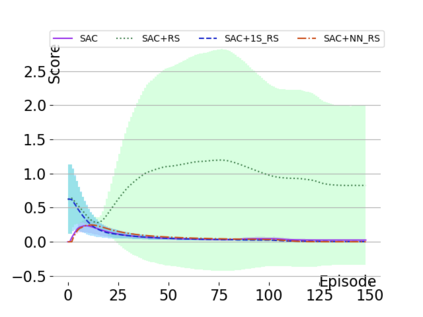
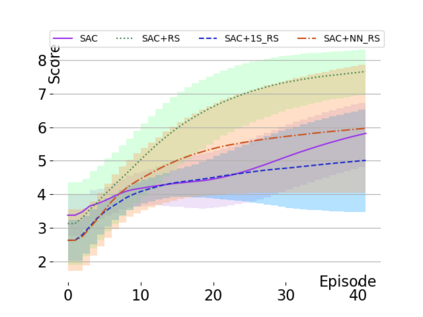
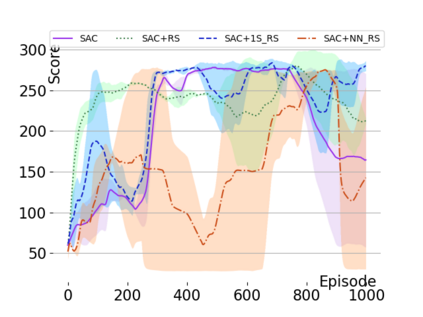
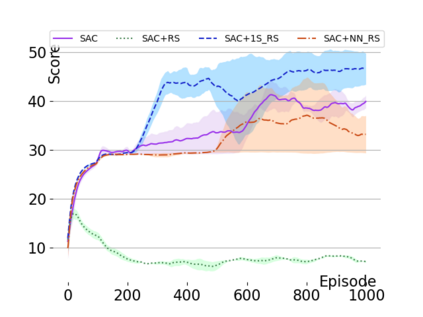
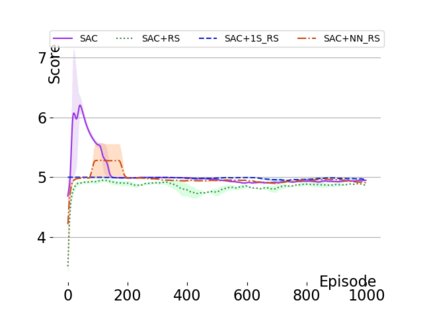
Text-based games are a popular testbed for language-based reinforcement learning (RL). In previous work, deep Q-learning is commonly used as the learning agent. Q-learning algorithms are challenging to apply to complex real-world domains due to, for example, their instability in training. Therefore, in this paper, we adapt the soft-actor-critic (SAC) algorithm to the text-based environment. To deal with sparse extrinsic rewards from the environment, we combine it with a potential-based reward shaping technique to provide more informative (dense) reward signals to the RL agent. We apply our method to play difficult text-based games. The SAC method achieves higher scores than the Q-learning methods on many games with only half the number of training steps. This shows that it is well-suited for text-based games. Moreover, we show that the reward shaping technique helps the agent to learn the policy faster and achieve higher scores. In particular, we consider a dynamically learned value function as a potential function for shaping the learner's original sparse reward signals.
翻译:以文字为基础的游戏是基于语言的强化学习(RL)的流行测试台。在以往的工作中,深Q学习通常被用作学习的媒介。Q学习算法由于培训不稳定等原因,难以适用于复杂的现实领域。因此,在本文中,我们将软Actor-critic(SAC)算法适应基于文字的环境。为了处理环境的稀少的外源收益,我们把它与潜在的奖励塑造技术结合起来,为RL代理提供更丰富(强烈)的奖励信号。我们运用我们的方法来玩基于文字的困难游戏。SAC方法在许多游戏中获得比Q学习方法更高的分数,只有培训步骤的一半。这表明它适合基于文字的游戏。此外,我们证明,奖励塑造技术有助于代理人更快地学习政策并获得更高的分数。我们特别认为,动态学习价值功能是塑造学习者原始分散的奖励信号的潜在功能。